





Abstract
Cellular Electron CryoTomography (CECT) is an emerging 3D imaging technique that visualizes subcellular organization of single cells at sub-molecular resolution and in near-native state. CECT captures large numbers of macromolecular complexes of highly diverse structures and abundances. However, the structural complexity and imaging limits complicate the systematic de novo structural recovery and recognition of these macromolecular complexes. Efficient and accurate reference-free subtomogram averaging and classification represent the most critical tasks for such analysis. Existing subtomogram alignment based methods are prone to the missing wedge effects and low signal-to-noise ratio (SNR). Moreover, existing maximum-likelihood based methods rely on integration operations, which are in principle computationally infeasible for accurate calculation.
Built on existing works, we propose an integrated method, Fast Alignment Maximum Likelihood method (FAML), which uses fast subtomogram alignment to sample sub-optimal rigid transformations. The transformations are then used to approximate integrals for maximum-likelihood update of subtomogram averages through expectation–maximization algorithm. Our tests on simulated and experimental subtomograms showed that, compared to our previously developed fast alignment method (FA), FAML is significantly more robust to noise and missing wedge effects with moderate increases of computation cost. Besides, FAML performs well with significantly fewer input subtomograms when the FA method fails. Therefore, FAML can serve as a key component for improved construction of initial structural models from macromolecules captured by CECT.
1 Introduction
Biological pathways rely on the functioning of macromolecular complexes, whose structures and spatial organizations are critical for the function and dysfunction of the pathways. The native structure information of macromolecular complexes has been extremely difficult to obtain due to the limitations of data acquisition techniques. Recent advances in Cellular Electron CryoTomography (CECT) imaging technique enables 3D visualization of subcellular structures at sub-molecular resolution and at near-native state, which makes the extraction of such information possible (Lučić et al., 2013). However, the imaging limits and high degree of structural complexity make the systematic analysis of a CECT 3D image (i.e. a tomogram) highly challenging. The cellular tomograms are normally of very low signal-to-noise ratio (SNR) that few macromolecular complexes can be identified by simple visual inspection. In addition, a tomogram has missing values (i.e. missing wedge effect) due to the limited imaging tilt angle range during the data acquisition process, which induces anisotropic resolution. Moreover, the relative size of a macromolecular complex is typically small compared to the image resolution. The abundances of macromolecular structures also vary widely (Beck et al., 2014). The structural identification and recovery of macromolecular complexes of low abundance are significantly more difficult than those of high abundance.
Due to the above challenges, the structural recovery of an individual macromolecular complex captured by CECT often requires the inference of its structure (represented by image signals) from large numbers (thousands) of observed subtomograms of identical structures. Such inference is called subtomogram averaging. A subtomogram is a sub-volume of a tomogram that is likely to contain only one macromolecule. There are two main types of subtomogram averaging methods. The first is through calculating the average of image intensity of multiple aligned subtomograms containing the same structure with the same orientation and displacement (e.g. Amat et al., 2010; Bartesaghi et al., 2008; Chen et al., 2013; Förster et al., 2008; Xu et al., 2012). Given that the input subtomograms normally contain structures of different orientations and displacements, they need to be aligned to reduce the resolution decrease resulted from orientation and translation difference. Alignment of 3D subtomograms (typical size voxels) is by nature computationally intensive. Therefore in practice, the alignment based averaging of thousands of subtomograms relies on fast alignment techniques (e.g. Bartesaghi et al., 2008; Chen et al., 2013; Xu et al., 2012) which use approximations to achieve sub-optimal alignment solutions (Section 2.1). Such subtomogram alignment methods (e.g. Xu et al., 2012) were able to achieve three magnitudes of speed increase compared with orientation scanning based exhaustive methods (e.g. Förster et al., 2008). Nevertheless, subtomogram alignment methods are parsimony: they only output a single optimal rigid transformation between a subtomogram and subtomogram average, which is likely to be biased by noise and missing wedge effects. As a result, compared to the maximum-likelihood methods (see the following paragraph), the alignment based subtomogram averaging methods are more prone to noise and missing wedge (Section 3.2).
The second type of averaging methods are maximum-likelihood based (e.g. Bharat et al., 2015; Scheres et al., 2009) (Section 2.3). Compared with alignment based methods, maximum-likelihood methods are, in principle, more robust to noise and to missing wedge effects because the signal at each location is inferred not only from across multiple subtomograms (as in alignment based methods), but also from multiple rigid transforms of each subtomogram through ‘data augmentation’ (Section 2.3). Maximum-likelihood based methods are based on integrating over all rigid transformations. An accurate calculation of such integral in principle requires the exhaustive scanning over a 6D space that parameterizes 3D rigid transformations, which is computationally infeasible.
The macromolecular complexes extracted from cellular tomograms are normally highly heterogeneous. First, crowded cellular environment (Best et al., 2007; Frangakis et al., 2002) has macromolecules that adopt different conformations to serve their particular function. They can also dynamically interact with other macromolecules to form different complexes across time. The structural recovery of heterogeneous macromolecules requires separation of the macromolecules into structurally homogeneous sets so that the averaging of each set can more accurately represent the true underlying structures of the set. Such process is called (unsupervised) subtomogram classification. The above alignment and maximum-likelihood based subtomogram averaging methods have been extended for simultaneously averaging and classifying the structurally heterogeneous subtomograms (e.g. Bartesaghi et al., 2008; Bharat et al., 2015; Chen et al., 2014; Scheres et al., 2009; Xu et al., 2012) by integrating with clustering. The limitations of the averaging methods are also carried to the extended classification tasks. To reduce the heterogeneity of millions of structurally highly diverse macromolecules, we have developed deep learning based unsupervised classification method (Zeng et al., 2017) that can coarsely group subtomograms into more homogeneous clusters without accurate alignment. Clusters of interest can be selected for further analysis.
To complement the above methods, based on existing work, here we propose a new method that integrates the above alignment and maximum-likelihood methods. The new method is termed as integrated Fast Alignment Maximum Likelihood method (FAML). Similar to other subtomogram averaging methods (e.g. Scheres et al., 2009; Xu et al., 2012), our new method is an expectation–maximization process that iteratively updates the subtomogram averages. However, the updates involve both fast alignment (Xu et al., 2012) and maximum-likelihood estimation (Scheres et al., 2009). Specifically, our integrated method consists of three main steps (Algorithm 1): (i) We first calculate a set of the rigid transformations that achieve suboptimal alignments between given subtomograms and subtomogram averages through adapting our previously developed fast alignment method (Xu et al., 2012) (Section 2.1); (ii) We then use these suboptimal rigid transformations to approximate integrals over the entire 6D parametric space of possible 3D rigid transformations (Section 2.2); (iii) The approximate integrals are used to update the subtomogram averages through expectation–maximization algorithm similar to (Scheres et al., 2009) (Section 2.3).
Our experiments on simulated and experimental subtomograms show that, compared to our previously developed fast alignment based method (FA) (Frazier et al., 2017; Xu et al., 2012), FAML is significantly more robust to noise and missing wedge bias with only a moderate increase in computational costs. FAML also performs well with a low number of input subtomograms when FA fails.
2 Materials and methods
An overview of the FAML method is given in Algorithm 1.
Integrated Fast Alignment Maximum Likelihood
1: procedure FAML()
2: Initialize model parameters from the distribution of data X (Section 2.4).
3:
4: fordo
5: ▹ Compute suboptimal rigid transformations (Section 2.1)
6: ▹ Compute Voronoi weights (Section 2.2)
7: ▹ Equation 11
8: ▹ Equation 12
9: ▹ Equation 13
10: ▹ Equation 10
11: ▹ Update model parameters
2.1 Step 1: Calculate suboptimal rigid transformations through fast alignment
2.2 Step 2: Approximate integration by summation over suboptimal rigid transformations
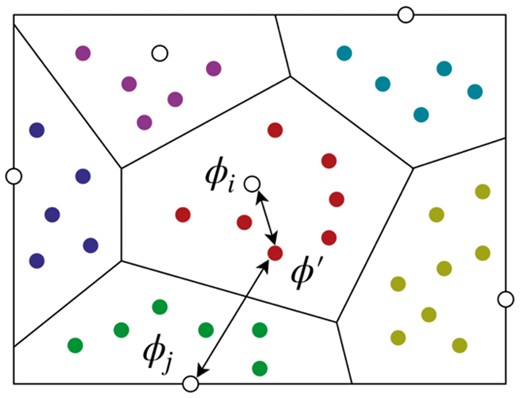
The basic idea of hypervolume calculation. The white dots are the suboptimal rigid transformations obtained by fast alignment (Section 2.1), and the colored dots are the sampled points . The Voronoi region is defined as the set of all points such that it is closer to than any when under the distance metric τ. The number of points in a Voronoi region becomes a good estimation of its hypervolume when a large number of points are sampled
For any two points , we define their distance as , where R is the corresponding rotation matrix of is the Frobenius norm (Huynh, 2009), and is a coefficient parameter used to balance the value scales between rotation and translation. In our experiments (Section 3), we set for simplicity.
2.3 Step 3: Maximum-likelihood based updating of subtomogram averages using expectation–maximization
N is total number of input subtomograms
is the ith subtomogram in the form of a J-dimensional vector of complex values (or Xij in short), which is divided into a vector of observed components and a vector missing components .
The observed and missing components of Xi are formalized by defining a J-dimensional missing data indicator vector , such that if is observed, and if is missing.
is one of K unknown 3D structures represented by subtomogram averages in Fourier space. . These are the objects to estimate from the data. The data model is used for subtomogram averaging when setting K = 1, and subtomogram classification and averaging when setting K > 1.
is an unknown, random integer, indicating which of the unknown structures corresponded to Xi.
is a rigid transformation operator which maps the unknown structure onto Xi. The actual transformation for particle Xi are unknown. Same as in Section 2.1, this transformation is parameterized by , a 6D vector (corresponding to three Euler angles in ZYZ convention, and three real-space translation coordinates, ); In such case, the rigid transformation operator is decomposed into a combination of rotation and translation operators .
is a J-dimensional vector of unknown, independent Gaussian noise with zero mean and unknown standard deviation σ.
Optionally, regularization of the similarities between averages can also be applied in a similar way as in (Scheres et al., 2009).
2.4 Parameter initialization
The way we initialize the model parameters is as follows. We set the αi for every class to be equal to . We divide all subtomograms evenly into K sets at random and let the average of each set be the class average Ai. The initial value of is obtained by picking a random subtomogram and class average and computing the square voxel intensity difference averaged over all observed parts, and ζ is initially set to be equal to the size of the image.
2.5 Implementation details
A modified version of the Tomominer library (Frazier et al., 2017) was used for fast alignment, 3D rigid transformation, and other processing. EMAN2 (Galaz-Montoya et al., 2015) library was used for constructing simulated subtomograms. The methods were parallelized on multiple CPU cores. The tests were performed on two computers. The first computer has two Intel Xeon E5-2687W CPUs at 3.0 GHz frequency and 256GB memory, allowing simultaneous running 48 parallel processes. The second computer has one Intel Core i7-6800K CPU at 3.4 GHz frequency and 128 GB memory, allowing simultaneous running 12 parallel processes. The isosurfaces and atomic models were plotted using UCSF Chimera (Pettersen et al., 2004). In all tests, both FAML and FA methods were executed for 20 iterations and converged within 20 iterations.
3 Results
3.1 Generation of realistically simulated subtomograms
In order to assess the performance of the FAML method, we simulated realistic subtomograms by mimicking the tomogram reconstruction process as described previously (Beck et al., 2009; Förster et al., 2008; Nickell et al., 2005). Missing wedge, image noise, and electron optical factors, including the Modulation Transfer Function (MTF) and the Contrast Transfer Function (CTF), were properly included. Electron optical density of macromolecular complexes was set to be proportional to the electrostatic potential. Volume electron density maps were generated by the Situs (Wriggers et al., 1999) PDB2VOL program, which was used to simulate electron micrograph images through a sequence of tilt-angles. Random noise was added to the images (Förster et al., 2008) to reach the target SNR levels, which were similar to the SNRs estimated from experimental data (Section 3.2.2). Electron micrograph images were convolved with the MTF and CTF to produce electron optical effects (Frank, 2006; Nickell et al., 2005). Data acquisition parameters in the simulation were determined by the experimental data acquisition parameters in Section 3.2.2, with spherical aberration of 2.7 mm, defocus of -6 μ m, and voltage of 300 kV. The MTF is defined as , where ω is the fraction of the Nyquist frequency, corresponding to a detector (McMullan et al., 2009). To reconstruct the simulated subtomogram from the tilt series, a direct Fourier inversion reconstruction algorithm [from the EMAN2 library (Galaz-Montoya et al., 2015)] was applied.
To determine the SNR of experimental subtomograms, we measured the SNR of the selected 859 ribosome subtomograms from a tomogram of primary rat neuron culture (Section 3.2.2). We selected 1000 random pairs of subtomograms that were already aligned to the corresponding ribosome template (PDB ID: 5T2C). The SNR of each subtomograms pairs was computed according to (Frank and Al-Ali, 1975). The mean SNR is 0.01035. We measured the SNR of TMV subtomograms (Section 3.2.3) in a similar way by aligning them to their FAML average. The mean SNR is 0.002313. The measured SNRs serve as a reference range to determine the SNR of simulated subtomograms. All simulated subtomograms are of size 643 with voxel size 0.6 nm and resolution 0.6 nm.
Figure 2 shows central slices of simulated GroEL (PDB ID: 1KP8) subtomograms (size: 643) of different level of SNRs and tilt angles. Compared with noise-free subtomograms (i.e. templates), subtomograms of lower SNR and smaller tilt angle range show more distortions.

Center slices (x–z plane) of simulated subtomograms of specified level of SNRs and tilt angle ranges
3.2 Reference-free averaging tests
When we assume all input subtomograms contain the same structure with random orientations and displacements, we choose K = 1. FAML is used for refining a single average, known as reference-free averaging.
3.2.1 Averaging of simulated GroEL subtomograms
Due to the crowded cellular environments and imaging limits, CECT data is usually of low SNR. Low SNR is a major challenge for reference-free subtomogram averaging. To test the performance of the FAML averaging with respect to a high noise level, we chose a low SNR 0.003, and simulated 100 GroEL (PDB ID: 1KP8) at that SNR level with tilt angle range . All 100 GroEL structures were randomly rotated and translated before constructing the simulated subtomograms.
The averaging results were plotted with fitted atomic model alongside a true GroEL structure (Fig. 3). The fitted atomic model with FAML GroEL average achieved cross-correlation coefficient of 0.77 whereas the fitted atomic model with FA GroEL average achieved cross-correlation coefficient of 0.19. Figure 3C showed that at such a low SNR level, the FA method failed to recover the GroEL structure, resulting in a subtomogram average of a collection of ‘torn pieces’. Figure 3B showed that FAML method successfully recovered the GroEL structure. The top view (Fig. 3B top) showed that the sevenfold rotational symmetry of GroEL was recovered. The advantage of FAML over FA on low SNR experimental subtomograms was further demonstrated in Section 3.2.2.
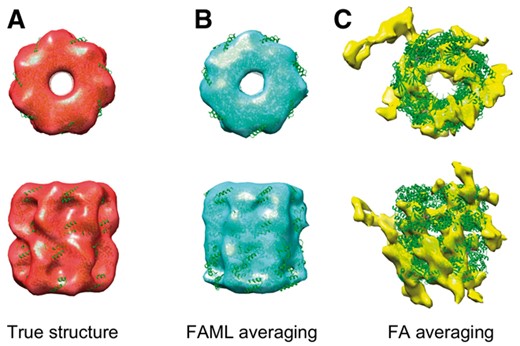
Averaging of low SNR simulation GroEL subtomograms: (A) Isosurface of true GroEL structure (PDB ID: 1KP8, filtered at 0.6 nm resolution) with fitted atomic model. (B) FAML subtomogram average with fitted atomic model (r = 0.77). (C) FA subtomogram average with fitted atomic model (r = 0.19)
Another CECT imaging distortion is the missing wedge effect. Many tomograms are processed at a small tilt angle range such as or to prevent excessive electron beam damage to the specimen. As the same structure may adopt different orientations inside a subtomogram, the missing wedge bias could be partly compensated and corrected by aligning and averaging multiple identical structures of different orientations during the structural recovery process. However, in some cases, such as small numbers of input subtomograms, small tilt angle ranges (i.e. large missing wedge angles), and having preferred orientations, correcting the missing wedge bias in the averaging process is substantially more challenging. In fact, a recent study shows that having preferred orientation is often a problem in single particle cryo-electron microscopy imaging (Glaeser and Han, 2017).
To test the performance of the FAML method on reference-free averaging of subtomograms with the above limits, we simulated a small number of 50 GroEL (PDB ID: 1KP8) subtomograms, at SNR level 0.01 with tilt angle range . Preferred orientation was also simulated by only allowing the structure to rotate about the Y axis. The principal axis of the structure is constrained to be parallel to the Y axis. All the GroEL structures were randomly rotated with constraints and translated before constructing simulated subtomograms.
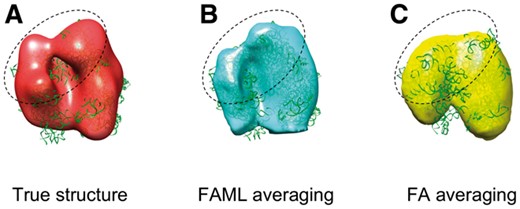
The averaging results were plotted with fitted atomic model alongside a true GroEL structure (Fig. 4). The fitted atomic model with FAML GroEL average achieved cross-correlation coefficient of 0.78 whereas the fitted atomic model with FA GroEL average achieved cross-correlation coefficient of only 0.49. Figure 4C showed that the FA method is heavily biased by the missing wedge effect. The averaged structure is distorted and elongated along the Y direction with a sizable missing region along the Z direction. In comparison, the FAML method fully corrected the missing wedge effect (Fig. 4B). No missing regions nor significant distortions are observable from the FAML average. The top view (Fig. 4B top) showed that FAML method recovered the GroEL structure with the sevenfold rotational symmetry. The advantage of FAML over FA on reducing missing wedge bias was further demonstrated on the experimental TMV subtomograms in Section 3.2.3.

Averaging of simulated GroEL subtomograms with small tilt angle range: (A) Isosurface of true GroEL structure (PDB ID: 1KP8, filtered at 0.6 nm resolution) with fitted atomic model. (B) FAML subtomogram average with fitted atomic model (r = 0.78). (C) FA subtomogram average with fitted atomic model (r = 0.49)
3.2.2 Averaging of experimental ribosome subtomograms extracted from a tomogram of primary rat neuron culture
Reference-free averaging was also tested on a dataset of 859 ribosome subtomograms extracted and purified from a tomogram of primary rat neuron culture (Guo et al., 2018). The tomogram was captured with a tilt angle range of to . It was then binned twice to a voxel size of 1.368 nm. 58 549 subtomograms of size 403 were extracted from the tomogram using the Difference of Gaussian particle picking method (Pei et al., 2016). The extracted subtomograms are highly heterogeneous. Therefore, we used a convolutional autoencoder (Zeng et al., 2017) to perform unsupervised clustering of the extracted subtomograms and selected only the clusters with large globular features because they are more likely to be ribosomes. This filtering process selected about 10% subtomograms for further analysis. Template search (Frazier et al., 2017) was applied to identify the top 1000 subtomograms with high structural correlation to the ribosome template. We manually inspected the 1000 subtomograms, and filtered out 141 of them which contained obvious non-ribosome structure such as fiducial.
Both FAML and FA method were tested on this ribosome subtomogram dataset. The averaging results were plotted with fitted atomic models alongside a true ribosome structure filtered at low resolution (10 nm). The fitted atomic model with FAML ribosome average achieved cross-correlation coefficient of 0.61 whereas the fitted atomic model with FA ribosome average achieved cross-correlation coefficient of 0.66. Figure 5C showed that FA subtomogram average converged to a general shape resembling a ribosome structure consisting of the 40S and 60S subunits with a major glove feature in between. Although the cross-correlation coefficient for FA average is slightly higher, the finer structural details (circled region), such as those connecting the two subunits, were lost as compared to the true structure. FAML method, on the other hand, recovered not only the general shape of a ribosome with two subunits but also with significantly more structural details of both subunits and their connection.
Averaging of experimental ribosome subtomograms (circled regions show that FAML recovers more structural details): (A) Isosurface of true ribosome structure (PDB ID: 5T2C, filtered at 10 nm resolution) with fitted atomic model. (B) FAML subtomogram average with fitted atomic model (r = 0.61). (C) FA subtomogram average with fitted atomic model (r = 0.66)
3.2.3 Averaging of experimental tobacco mosaic virus subtomograms
The performance of FAML in correcting missing wedge effects was further tested using a subtomogram dataset of tobacco mosaic virus (TMV), a type of helical virus (Kunz et al., 2015). The dataset consists of 2742 TMV subtomograms of size 1283. They were two times binned to size 643. The tilt angle range is and the voxel size is 0.54 nm after binning.
Without taking advantage of rotational symmetry information, the FA subtomogram averaging resulted in large missing regions (Fig. 6B bottom part) and appears to be a stack of ring structures rather than a single helical structure (Fig. 6D). The top and bottom view regions of the FA averages are significantly distorted (Fig. 6B). Compared to the FA average, the FAML average is significantly more similar to the known helical structure of TMV, although the parts that are located at top and bottom views are not perfectly smooth (Fig. 6A). No significant missing regions are observable and a symmetric helical structure was roughly recovered (Fig. 6C).
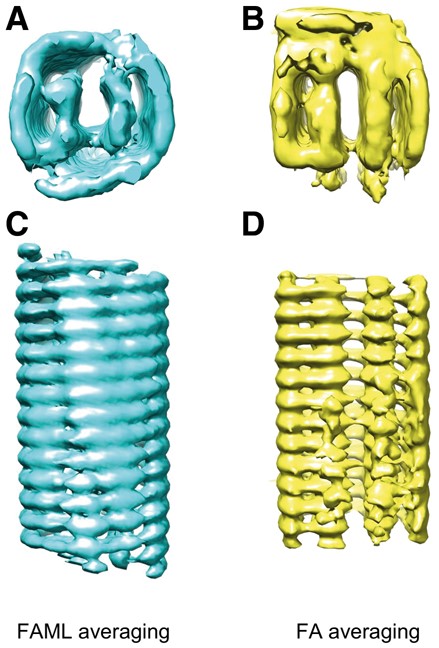
Averaging of experimental TMV subtomograms: (A) Isosurface of FAML subtomogram average (symmetry: 0.47). (B) FA subtomogram average (symmetry: 0.25)
It is known the TMV has seventeenfold symmetry. We measured the symmetry of FA and FAML averages. The symmetry was measured by the pair-wise correlation between the structure and its rotation along the principal axis with an angle corresponding to the seventeenfold symmetry. For each average, seventeen rotated structures were generated and the average pairwise correlation was computed.
FAML achieved an average pairwise correlation of 0.47. FA achieved an average pairwise correlation of 0.25. Therefore, the FAML average recovered better TMV symmetric features.
3.3 Reference-free classification and averaging tests
Frequently, subtomogram datasets contain heterogeneous structures. Simple averaging will result in recovering a mixed structure. In such case, unsupervised classification should be performed simultaneously with the subtomogram averaging process to recover multiple averages of different structures. Structural recovery accuracy, as well as classification accuracy, are both important for these tasks.
3.3.1 Classification and averaging of simulated GroEL and ribosome subtomograms
To test the performance of FAML on reference-free classification and averaging tasks, we simulated 100 GroEL (PDB ID: 1KP8) and 100 ribosome (PDB ID: 4V4A) subtomograms at SNR level 0.01 with tilt angle range . All 200 structures were randomly rotated and translated inside the subtomogram.
This dataset of 200 subtomograms was classified and averaged by both FAML and FA methods with K = 2. FAML method successfully classified the 200 subtomogram into 2 classes, of which class 1 contains 100 GroEL subtomograms and class 2 contains 100 ribosome subtomograms. No subtomogram was misclassified. The averaging results of the two classes were plotted alongside a true GroEL structure and a true ribosome structure (Fig. 7). The characteristic sevenfold symmetry feature of the GroEL structure was successfully recovered (Fig. 7B top). The ribosome average resembles the true structure in terms of structural details to a good extent (Fig. 7E).
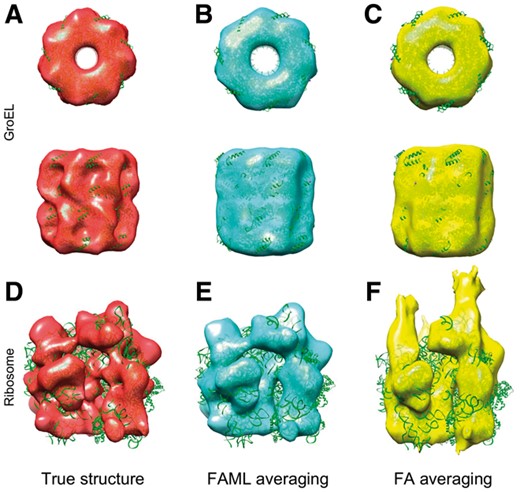
Classification and averaging of simulated GroEL and ribosome subtomograms: (A) Isosurface of true GroEL structure (PDB ID: 1KP8, filtered at 0.6 nm). (B) FAML average of GroEL subtomogram (r = 0.88). (C) FA average of GroEL subtomogram (r = 0.84). (D) True ribosome structure (PDB ID: 4V4A, filtered at 0.6 nm). (E) FAML average of ribosome subtomogram (r = 0.85). (F) FA average of ribosome subtomogram (r = 0.75)
By contrast, FA method classified the 200 subtomogram into 2 classes, of which class 1 contains 98 GroEL subtomograms and class 2 contains 100 ribosome subtomograms and 2 GroEL subtomograms. Two subtomograms were misclassified. The averaging results of the two classes were plotted alongside a true GroEL structure and a true ribosome structure (Fig. 7). The sevenfold symmetry of the GroEL structure was successfully recovered because the classified GroEL class contains 98 homogeneous GroEL structures (Fig. 7C top). However, additional structures were falsely generated in the top region of ribosome average (Fig. 7F). This is mainly due to the two GroEL subtomograms mixed into the ribosome subtomogram class. The fitted atomic model with FAML GroEL and ribosome averages achieved cross-correlation coefficients of 0.88 and 0.85, respectively whereas the fitted atomic model with FA GroEL and ribosome averages achieved cross-correlation coefficients of 0.84 and 0.75, respectively.
We measured the classification accuracy in terms of F1 score, which is the harmonic mean of precision and recall. Overall, the FAML method achieved an average F1 score of 1 and the FA method achieved an average F1 score of 0.99. The FAML method outperforms the FA method regarding both classification accuracy and structural recovery accuracy.
3.3.2 Averaging and classification of experimental capped proteasome and TRiC subtomograms extracted from a tomogram of rat neuron with expression of poly-GA aggregate
Furthermore, reference-free classification and averaging were tested on a dataset consisting of 125 TCP-1 ring complex (TRiC) subtomograms and 200 capped proteasome subtomograms extracted from a tomogram of rat neuron with expression of poly-GA aggregate (Guo et al., 2018). All subtomograms were two times binned to size 403 (voxel size: 1.368 nm). The tilt angle range was to .
The reference-free classification and averaging tasks were substantially more challenging due to the small number of input subtomograms. The TRiC&proteasome dataset was classified and averaged by both FAML and FA methods with K = 2.
The averaging results of the two classes were plotted alongside a true TRiC structure and a true capped proteasome structure (Fig. 8). The fitted atomic model with FAML TRiC and capped proteasome averages achieved cross-correlation coefficients of 0.41 and 0.45, respectively whereas the fitted atomic model with FA TRiC and capped proteasome averages achieved cross-correlation coefficients of 0.08 and 0.16, respectively.

Averaging and classification of experimental capped proteasome and TRiC subtomograms: (A) True TRiC structure (PDB ID: 4V94, filtered at 6 nm). (B) FAML subtomogram average (r = 0.41). (C) FA subtomogram average (r = 0.08). (D) True capped proteasome structure (PDB ID: 5MPA, filtered at 6 nm). (E) FAML subtomogram average (r = 0.45). (F) FA subtomogram average (r = 0.16)
FAML method classified the 325 subtomogram into 2 classes, of which class 1 contains 91 TRiC subtomograms and 6 capped proteasome subtomograms, and class 2 contains 194 capped proteasome subtomograms and 34 TRiC subtomograms. 40 subtomograms were misclassified. FAML recovered the spherical shape of TRiC to a similar size (Fig. 8B). The capped proteasome average resembles the true structure in terms of its cylindrical shape and the cap on the top (Fig. 8E).
On the other hand, the FA method classified the 325 subtomogram into 2 classes, of which class 1 contains 10 TRiC subtomograms, and class 2 contains 200 capped subtomograms and 115 TRiC subtomograms. 115 subtomograms were misclassified. The averaging results of the two classes were plotted alongside a true TRiC structure and a true capped proteasome structure (Fig. 8). The spherical shape of the TRiC structure was not recovered due to the low number of TRiC subtomograms classified in class 1. The capped proteasome structure was also not correctly recovered mainly due to the high number of TRiC subtomograms misclassified to class 2 (Fig. 8F).
Overall, the FAML method achieved an average F1 score of 0.863 and the FA method achieved an average F1 score of 0.462. The FAML method significantly outperformed the FA method in terms of accuracy.
3.3.3 Averaging and classification of experimental GroEL and GroEL-GroES subtomograms
We tested the performance of FAML method on classifying and averaging subtomograms with high structural similarity. Reference-free averaging and classification were tested using a dataset of experimental GroEL and GroEL-GroES subtomograms captured in (Förster et al., 2008). The dataset consists of 780 subtomograms belonging to two class: GroEL and GroEL-GroES. To show that the FAML method can achieve successful averaging and classification with a small number of input subtomograms, we substantially decreased the size of the GroEL/GroEL-GroES dataset by randomly selecting 400 subtomograms. All the 400 subtomograms are of size 323 with voxel size 1.2 nm and tilt angle range .
Both FAML and FA methods were applied to the selected subtomograms. The averaging results of the two classes were plotted alongside a true GroEL structure and a true GroEL-GroES structure (Fig. 9). Though the FA method was tested previously on the original dataset of 780 subtomograms and successfully recovered the GroEL and GroEL-GroES structure (Frazier et al., 2017), when decreasing the input subtomogram number to 400, the FA method could not fully recover either the GroEL structure (Fig. 9C) or the GroEL-GroES structure (Fig. 9F). Both structures are heavily distorted compared to the true structures.
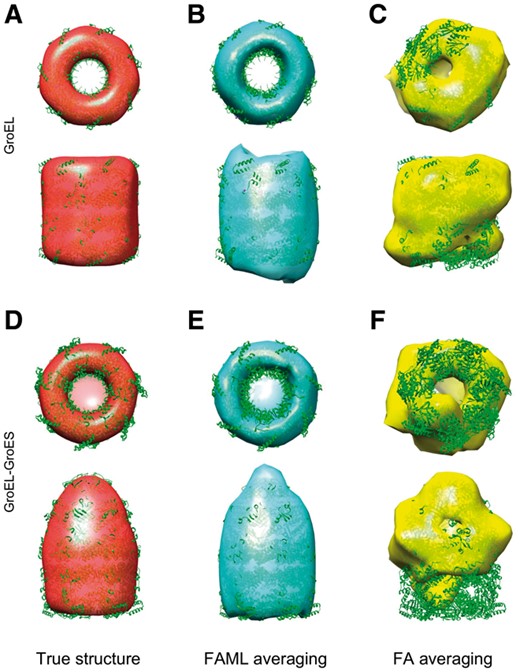
Averaging and classification of experimental GroEL and GroEL-GroES subtomograms: (A) Isosurface of true GroEL structure (PDB ID: 1KP8, filtered at 6 nm). (B) FAML subtomogram average (r = 0.87). (C) FA subtomogram average. (r = 0.40) (D) True GroEL-GroES structure (PDB ID: 2C7C, filtered at 6 nm). (E) FAML subtomogram average (r = 0.78). (F) FA subtomogram average (r = 0.24)
By contrast, the FAML method recovered both GroEL (Fig. 9B) and GroEL-GroES (Fig. 9E) structures as compared to the true structures regarding their size and symmetric shape. The averaged GroEL-GroES structure can be distinguished from the averaged GroEL structure by its characteristic enlarged chamber at its top (Fig. 9E bottom).
The fitted atomic model with FAML GroEL and GroEL-GroES averages achieved cross-correlation coefficient of 0.87 and 0.78, respectively whereas the fitted atomic model with FA GroEL and GroEL-GroES averages achieved cross-correlation coefficients of 0.40 and 0.24, respectively. The previously reported performance for method (Scheres et al., 2009) on the whole 780 subtomograms is 0.88 and 0.81 for GroEL and GroEL-GroES averages, which is only slightly higher than ours obtained from a significantly smaller number of only 400 subtomograms.
Therefore, the FAML method significantly outperformed the FA method in classification and averaging of similar structure with a substantially smaller number of input subtomograms. The FAML method achieved comparable averaging results to method (Scheres et al., 2009) on substantially fewer input subtomograms.
3.4 Computation time analysis
Similar to FA, the computational cost for all the components of FAML scales linearly with the number of voxels in the input subtomograms. The cost for the maximum-likelihood update functions is linear to the size of sampled rigid transformations taken to approximate the integrals. To give an estimation of how our method compares with those with exhaustive integration, we performed time profiling during execution of FAML. As we can see in the graph (Fig. 10), the steps for maximum-likelihood update in FAML cost 66% of the time. Using a uniform grid sampling to obtain instead of using fast alignment and aim for no more than a 10x increase of computational cost, we can at most afford to increase the size of by a factor of 20. Given that our method normally uses at most 50 samples for each integration, this gives a total of 1000 sample points, which is equivalent to a very sparse 6D sample grid of fewer than 4 points in each spacial translation, and an angular sampling interval of more than °. Such a sampling rate is too low for any competitive results, but about ten times slower than our FAML algorithm. The trade-off for computing fast alignment over more sample points is a highly efficient one.
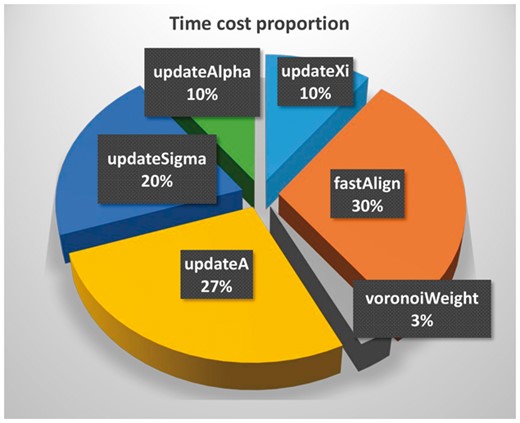
Pie chart of time cost proportions for major FAML steps for the averaging of subtomograms of size 1283 voxels in Table 1
In general, the scanning based accurate calculation of the integral in Equation 3 is in principle computationally infeasible, as the cost scales cubically with both the angular and translational sampling rates. For example, a sampling with a rotation angle interval of , and a translational offset of ±10 voxels with a step of 1 voxel will take more than sampled rigid transformations on the manifold . To our knowledge, in practice, adaptive oversampling similar to (Scheres, 2012) has been used for approximating such integrals. In the later stages of the iterative averaging process, local orientation searches are used, which may degenerate such methods to the alignment based method by only sampling in the vicinity of a single rigid transformation between a subtomogram and a subtomogram average. The limits of alignment based subtomogram averaging methods may carry to such adaptive oversampling based maximum-likelihood subtomogram averaging methods. Theoretically, the multiple rigid transformations produced by our global search (Section 2.1) would prevent the averaging process from sticking at such local optima.
The computational time is not directly comparable because FA is implemented mainly in C++ and FAML (maximum-likelihood updating steps) is implemented in python. However, from a utility perspective, we compared the computation time used for FA and FAML averaging tasks. For each task, 20 simulated ribosome subtomograms (PDB ID: 4V4A) of specified sizes were averaged by both methods (the practical input subtomogram size limit is 2563 for current typical computer hardware settings). All simulated subtomograms are of SNR 0.02. Ribosome structures were randomly rotated and translated before they were used to construct the simulated subtomograms. We also include computation time cost using RELION (implemented in C++), the most popular subtomogram classification and averaging software which implements method (Scheres et al., 2009). RELION was tested using its default sampling parameters: angular sampling interval without adaptive oversampling or local searches, and 5 pixels offset search range with 1 pixel search step. Using the default parameters gave us a rough estimation of the computation time cost. Note that in practice these sampling parameters should be modified accordingly with larger input subtomograms, which will further increase the computation time of the RELION method. All three methods were tested on the Intel Core I7 computer with 12 parallel computing processes.
We recorded in Table 1 the number of iterations it took to converge, time per iteration, and the total time it took to converge for each task. From Table 1, we found that though the FA method took less time per iteration, FAML generally took fewer iterations to converge. If the steps for maximum-likelihood update in FAML were implemented with C++, it would be expected to achieve several folds of speedup. Therefore, there is only a moderate increase of computation time of FAML compared to FA. Given that FA has achieved three magnitudes of speedup (Xu et al., 2012) compared to the orientation scanning exhaustive search based method (Förster et al., 2008), and that FAML requires a substantially smaller number of subtomograms with a faster convergence for successful structural recovery than FA does, we believe a moderate increase in time cost of FAML will not affect its efficacy for the systematic de novel recovery of large numbers of macromolecules with highly diverse structures and abundances captured by CECT.
Computing time used for FA, FAML and RELION methods
| Iterations to converge | Mean time per iteration | Total time | |
|---|---|---|---|
| FA (323) | 11 | 7 s | 78 s |
| FAML (323) | 10 | 56 s | 562 s |
| RELION (323) | 8 | 340 s | 2720 s |
| FA (643) | 4 | 27 s | 106 s |
| FAML (643) | 3 | 150 s | 451 s |
| RELION (643) | 6 | 340 s | 2041 s |
| FA (1283) | 5 | 143 s | 717 s |
| FAML (1283) | 4 | 449 s | 1794 s |
| RELION (1283) | 3 | 921 s | 2764 s |
| Iterations to converge | Mean time per iteration | Total time | |
|---|---|---|---|
| FA (323) | 11 | 7 s | 78 s |
| FAML (323) | 10 | 56 s | 562 s |
| RELION (323) | 8 | 340 s | 2720 s |
| FA (643) | 4 | 27 s | 106 s |
| FAML (643) | 3 | 150 s | 451 s |
| RELION (643) | 6 | 340 s | 2041 s |
| FA (1283) | 5 | 143 s | 717 s |
| FAML (1283) | 4 | 449 s | 1794 s |
| RELION (1283) | 3 | 921 s | 2764 s |
Note: 323 in parenthesis denotes the testing subtomograms are of size 323.
Computing time used for FA, FAML and RELION methods
| Iterations to converge | Mean time per iteration | Total time | |
|---|---|---|---|
| FA (323) | 11 | 7 s | 78 s |
| FAML (323) | 10 | 56 s | 562 s |
| RELION (323) | 8 | 340 s | 2720 s |
| FA (643) | 4 | 27 s | 106 s |
| FAML (643) | 3 | 150 s | 451 s |
| RELION (643) | 6 | 340 s | 2041 s |
| FA (1283) | 5 | 143 s | 717 s |
| FAML (1283) | 4 | 449 s | 1794 s |
| RELION (1283) | 3 | 921 s | 2764 s |
| Iterations to converge | Mean time per iteration | Total time | |
|---|---|---|---|
| FA (323) | 11 | 7 s | 78 s |
| FAML (323) | 10 | 56 s | 562 s |
| RELION (323) | 8 | 340 s | 2720 s |
| FA (643) | 4 | 27 s | 106 s |
| FAML (643) | 3 | 150 s | 451 s |
| RELION (643) | 6 | 340 s | 2041 s |
| FA (1283) | 5 | 143 s | 717 s |
| FAML (1283) | 4 | 449 s | 1794 s |
| RELION (1283) | 3 | 921 s | 2764 s |
Note: 323 in parenthesis denotes the testing subtomograms are of size 323.
4 Conclusion
CECT is a very promising tool for the systematic visualization of native structures and spatial organizations of large macromolecules inside single cells. Nevertheless, it remains one of the bottlenecks the efficient and accurate reference-free recovery and separation of large numbers of diverse macromolecular structures systematically through subtomogram averaging and classification. In this paper, building on existing work, we proposed a new method (FAML) that integrates fast subtomogram alignment (Xu et al., 2012) with maximum-likelihood (Scheres et al., 2009) methods to improve the recognition and recovery of initial structural models from input subtomograms. Our experiments showed a significant improvement compared with our previous methods (Frazier et al., 2017; Xu et al., 2012) in terms of i) the number of subtomograms needed for successful recovery and classification, and ii) robustness to the noise and missing wedge effects. FAML is favored especially with subtomogram datasets of low SNR or tilt angle range.
Due to its high scalability and accuracy, FAML is a very useful component for improved systematic structural pattern mining in CECT, thereby bridging the gap from microscopy to structure. A potential use of FAML is to combine it with other reference-free structural pattern mining techniques. For example, given millions of subtomograms extracted from cellular tomograms using reference-free particle picking (e.g. Voss et al., 2009), these macromolecules can be first filtered using our recently developed deep learning based coarse structural separation method (Section 3.2.2) (Zeng et al., 2017), then be classified and averaged using FAML. The resulting averages can be further refined by maximum-likelihood methods that take into account Contrast Transfer Functions (Bharat et al., 2015) or high-precision alignment (Xu and Alber, 2012) method. Besides CECT, FAML can be applied to similar data analysis tasks from cryo-tomograms of purified complexes or cell lysate.
Acknowledgements
We thank Dr. Robert F. Murphy for suggestions. We thank Dr. Zachary Freyberg and Dr. James Krieger for technical assistance. We thank Dr. Achilleas Frangakis and Dr. Michael Kunz for sharing the TMV subtomograms for the averaging test. We thank Dr. Friedrich Förster for sharing the GroEL and GroEL-ES subtomograms for the classification test.
Funding
This work was supported in part by the National Institutes of Health (NIH) [grant number P41GM103712]. MX was supported by the Samuel and Emma Winters Foundation.
Conflict of Interest: none declared.
References
Author notes
The authors wish it to be known that, in their opinion, Yixiu Zhao and Xiangrui Zeng authors should be regarded as Joint First Authors.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}