




Summary
Decompositions of the score of a forecast represent useful tools for assessing its performance. We consider local score decompositions permitting detailed forecast assessments across a spectrum of conditions of interest. We derive corrections to the bias of the decomposition components in the framework of point forecasts of quantile-type functionals, and illustrate their performance by simulation. Related bias corrections have thus far only been known for squared error criteria.
1. Introduction
The difficulty of making predictions about future data has led to a large literature on the assessment of forecasts. The squared distance between predicted and realized values provides a simple measure of the accuracy, and much existing work relies on quadratic error criteria. Our focus here is on point forecasts of some characteristic of the predictive distribution such as the mean or a quantile. Proper error quantification in this case depends on the concept of a loss type scoring function that is consistent for the given characteristic (Gneiting, 2011). Given such a consistent scoring function, forecaster |$X_1$| would be ranked better than forecaster |$X_2$| if the average score of |$X_1$| is less than that of |$X_2$|. Additional criteria include skill scores (Murphy & Winkler, 1987), calibration and sharpness measures (DeGroot & Fienberg, 1983; Gneiting et al., 2007), as well as decompositions of the average score into three components commonly referred to as reliability, resolution and uncertainty (Murphy & Winkler, 1987; Bröcker, 2009, 2012; Weijs et al., 2010; Christensen, 2015). Comprehensive assessment of forecast schemes requires further information not provided by such summary statistics. Graphical tools such as verification rank histograms are particularly useful for checking the correct calibration of the predictions, but accuracy is also an issue (Gneiting et al., 2007).
We consider score decompositions permitting an assessment of both these aspects. To that end, the data are split into strata according to the values of a variable |$W$|. Usually, only the special case |$W=X$|, where |$X$| is the forecast, is considered. A. Tsyplakov, in the 2014 working paper ‘Theoretical guidelines for a partially informed forecast examiner’ posted at https://mpra.ub.uni-muenchen.de/67333/, points out that the information available to forecasters and assessors may differ, and assessments may be carried out on the basis of any relevant information, encoded here by |$W$|. We specifically consider the case where |$X$| is |$W$|-measurable. Then |$W$| is best thought of as a pair |$W=(X,A)$| where |$A$| represents auxiliary information or indexes domains calling for a separate forecast evaluation, such as season and latitude in weather forecasts (Murphy, 1995). In any case, conditionally on |$W$| the score decomposes into components measuring calibration and entropy locally, in contrast with the common three-term decomposition which involves the intrinsically global resolution and uncertainty terms. Taking up previous findings of a potentially serious bias in estimators of these criteria (Bröcker, 2012; Bentzien & Friederichs, 2014), we derive corrections removing this bias to a first order of approximation. Related results have so far been obtained for mean-value-type functionals and squared error (Ferro & Fricker, 2012). The latter permits algebraic calculations that are not feasible with the scoring functions relevant to quantiles or expectiles. We instead build on a recently established mixture representation of such scoring functions (Ehm et al., 2016) and on the local behaviour of empirical distribution functions. Our bias corrections apply to a broad class of generalized quantiles and the associated consistent scoring functions, making it possible to treat quantiles and expectiles in a unified manner. Likewise, they yield immediate corrections to the bias of global score components such as the resolution.
2. Score decompositions
A characteristic such as a quantile or mean value corresponds to a functional |$F \mapsto T(F)$| on some class |$\mathcal{F}$| of right-continuous distribution functions on the real line, the predictive distributions (Gneiting, 2011). Given |$T$|, a nonnegative scoring function |$S=S(x,y)$| of the point forecast |$x$| of |$T(F)$| and the future observation |$y$| is consistent for |$T$| if for every |$F \in \mathcal{F}$| the expression |$S(x,F) = E_{Y \sim F} S(x,Y)$| is minimized when |$x = T(F)$|; it is strictly consistent if |$x=T(F)$| is the unique minimizer of |$S(x,F)$|. For example, the piecewise linear score |$S(x,y) = |\mathrm{1}_{x<y} - \alpha|\, |x-y|$| is strictly consistent for the lower |$\alpha$|-quantile, |$T(F) = \inf \{t:\, F(t) \ge \alpha\}$|, and the asymmetric quadratic score |$S(x,y) = |\mathrm{1}_{x<y} - \alpha|\, (x-y)^2$| is strictly consistent for the |$\alpha$|-expectile, the solution |$t \equiv T(F)$| of the equation |$(1-\alpha)\int_{-\infty}^t (t-y){\rm d}F(y) = \alpha \int_t^{\infty} (y-{t}){\rm d}F(y)$| (Newey & Powell, 1987). Here |$\mathrm{1}_A$| denotes the indicator function of the event |$A$|, and the respective moments are supposed to be finite for |$F \in \mathcal{F}$|. The case |$\alpha=1/2$| retrieves the median and the mean, which minimize the expected absolute and squared error, respectively.
Throughout the following, |$S$| stands for a fixed scoring function that is consistent for the given functional |$T$| on |$\mathcal{F}$|. The minimum expected score, |$\inf\nolimits_x\, S(x,F) = S\{T(F),F\}$|, is called the entropy of |$F$|, and the overshoot |$d(x,F) = S(x,F) - S\{T(F),F\}$| is called the divergence between |$x$| and |$T(F)$|. In the median and the mean value cases, the entropy reduces to one half times the mean absolute deviation and the variance, respectively, and quite generally it makes sense to think of the entropy as a generalized variance and the divergence as a bias term.
This results from (2) on writing |$S\{T(G_W),G_W\} = S\{T(G),G_W\} - d\{T(G),G_W\}$| and taking expectations. The global entropy term |$S\{T(G),G\}$| traditionally is called uncertainty, the resolution |$E\, [d\{T(G),G_W\}]$| measures the average variability of |$T(G_W)$|, and the global miscalibration |$\small{\text{MCB}}$| commonly is referred to as the reliability or conditional bias. We deviate from this terminology because we feel that miscalibration is more appropriate than reliability, and because in our setting the term conditional bias is needed for a different purpose.
3. Correcting the bias of the decomposition components
If the empirical distributions |$\hat G_n$| and |$\hat G_{n,k}$| are close to |$G$| and |$G_k$|, the empirical calibration, resolution, and uncertainty or entropy terms should give useful approximations to their theoretical counterparts. However, there could be a finite sample bias. To study conditional biases given the |$w_i$|, it is convenient to introduce the |$\sigma$|-algebra |$\mathcal{W}$| generated by all indicator variables |$\mathrm{1}_{w_i = k} (i = 1,\ldots,n;\, k = 1,\ldots,m)$|. Frequent use will be made of the following fact.
Conditionally on |$\mathcal{W}$| the random variables |$y_i$| with |$w_i = k$| are independent and identically distributed with distribution |$G_k$|.
Clearly, a correction for the conditional bias corrects for the unconditional bias.
Henceforth we consider score decompositions and bias corrections within the setting of Proposition 1. Functionals |$T$| of the specified type will be referred to as generalized quantiles. For our main result we need to suppose the following.
The class |$\mathcal{F}$| contains each conditional distribution |$G_k$|, and for any |$F \in \mathcal{F}$|,
(i) |$I_\theta^2(F) = \int I_\theta(\,y)^2\,{\rm d}F(y) < \infty$| for every |$\theta$|;
(ii) |$\theta \mapsto I_\theta(F)$| is continuously differentiable with derivative |$\dot I_\theta(F)> 0 $| at |$\theta = T(F)$|;
(iii) if |$F_n$| is the empirical distribution function of a sample of size |$n$| from |$F$|, then as |$n \to \infty$| the process |$\theta \mapsto U_{\theta,n} = n^{1/2} \{I_\theta(F_n) - I_\theta(F)\}$|, converges weakly in the Skorohod space |$D(-\infty,\infty)$| to a mean zero Gaussian process |$\{U_\theta\}$| with continuous sample paths (van der Vaart, 1998, Sect. 18.3).
The above assumptions are weak. For |$\alpha$|-quantiles, e.g., |$U_{\theta,n}$| converges weakly to the Brownian bridge process |$B\{F(\theta)\}$| (van der Vaart, 1998, p. 266), which has continuous sample paths since |$\theta \mapsto F(\theta) = I_\theta(F) + \alpha$| is continuous, by (ii).
As in McCullagh (1987, p. 209) we take the expression (10) for |$E^\mathcal{W} (\Delta_k)$| as our approximation to |$\beta_k = E^\mathcal{W} (\hat\Delta_k)$|. Estimates |$\hat \beta_k$| of the local conditional biases to be used with (7), (8) are obtained on substituting the unknown distributions |$G_k$| in (10) by their empirical counterparts |$\hat G_{n,k}$|. The estimate |$\hat \beta$| of the global conditional bias is of the same form, only that |$G_k\, ,\hat G_{n,k}$| have to be replaced by |$G,\, \hat G_n$|, and |$n_k$| by |$n$|. We therefore focus on the local biases.
Most prominent among the mixture scores are those with a constant mixture density |$m$|. For quantiles, |$m\equiv 1$| yields the piecewise linear score, |$S(x,y) = |\mathrm{1}_{x<y} - \alpha|\, |x-y|$|, while for expectiles |$m\equiv 2$| yields the asymmetric quadratic score, |$S(x,y) = |\mathrm{1}_{x<y} - \alpha|\, (x-y)^2$|. These standard choices are presupposed in the following. We first consider the quantile case. Since by condition (ii) every |$F\in \mathcal{F}$| has a continuous density |$f = F'$|, we find that |$I_\theta^2(F) = (1-2\alpha) F(\theta) + \alpha^2,\ \dot I_\theta(F) = f(\theta)$|. When evaluated at |$\theta=q_F$|, |$q_F$| the |$\alpha$|-quantile of |$F$|, this becomes |$I_{q_F}^2(F) = \alpha(1-\alpha),\ \dot I_{q_F}(F) = f(q_F)$|, whence our bias correction assumes the form |$\hat \beta_k = -\alpha(1-\alpha)/\{2 n_k \hat g_k(\hat q_k)\}$| where |$\hat g_k$| and |$\hat q_k$| are estimates of the density |$g_k$| of |$G_k$| and of its |$\alpha$|-quantile, respectively. This is unfortunate in two respects: first, density estimates tend to be unstable; secondly, the crucial term appears in the denominator. Thus unless |$n_k$| is large enough for a kernel estimate to be useful, it appears wise to consider a bias correction only in connection with a parametric model, where |$\hat g_k$| can be estimated by plugging in the parameter estimates. The expectile case presents no such problems. One simply may replace |$G_k$| by |$\hat G_{n,k}$| and |$t_k$| by the empirical |$\alpha$|-expectile |$\hat \eta_k$| of |$\hat G_{n,k}$| in (10). The correction is fully nonparametric as well as local, as it depends only on the empirical distribution of the verifying observations in the respective bin. For |$\alpha=1/2$| the correction simplifies to |$\hat \beta_k = -s_k^2/(2n_k)$|, with |$s_k^2$| the variance of |$\hat G_{n,k}$|. Related results for this case were obtained by Bröcker (2012) and Ferro & Fricker (2012).
4. Simulations
Figure 1 presents simulation results for a normalized miscalibration measure we call deviation, |$\hat {\small{\text{DEV}}}_k = (1 + \hat {\small{\text{MCB}}}_k/ \hat {\small{\text{ENT}}}_k)^{1/2} - 1$|, and its bias-corrected analog |$\hat {\small{\text{DEV}}}_k^*$|, compared against the theoretical quantities |${\small{\text{DEV}}}_k = (1 + {\small{\text{MCB}}}_k/ {\small{\text{ENT}}}_k)^{1/2} - 1$|. Evidently, the local biases were quite large, and the bias reduction moderate to substantial. Similar results hold for the global biases. The bias of the simulated global miscalibration estimates |$\hat {\small{\text{MCB}}}$| normalized by their standard deviation ranged from |$2.4$| to 5 in the important special case |$\alpha = 0.5$|. With bias correction, the corresponding values were between |$0.25$| and |$0.87$|. They were never larger than one half times the uncorrected ones and often substantially smaller.
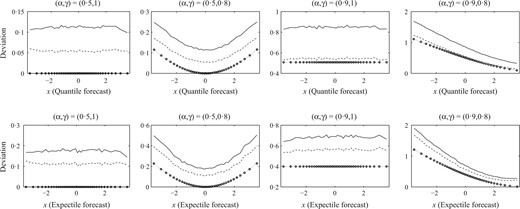
Deviation, i.e., normalized local miscalibration: empirical deviation |$\hat {\small{\text{DEV}}}_k$| averaged across simulations plotted versus likewise averaged forecast bin means |$\bar x_k$| (solid), for four choices of parameters |$\alpha, \gamma$|; same for bias-corrected deviation |$\hat{\small{\text{DEV}}}_k^*$| (dashes) and truth |${\small{\text{DEV}}}_k$| (circles, dots).
5. Discussion
Average scores are widely used to assess forecasts. Conditioning on a third variable yields a decomposition of the average score into local calibration and entropy terms permitting refined assessments. For example, graphical displays of the local decomposition terms can serve as diagnostic tools. The components of the empirical decomposition suffer from a systematic, potentially serious bias. Interestingly, Bentzien & Friederichs (2014) found that these components depend less on the binning when corrected for bias. Our bias correction works binwise, but it can also be used to reduce the bias of the global decomposition terms, where the bias can considerably exceed the dispersion. Throughout the paper it was assumed that the data triplets |$(x_i,y_i,w_i)$| are independent and identically distributed. In fact, the proof of Theorem 1 only requires such an assumption conditionally given |$\mathcal{W}$|, which is weaker.
Acknowledgement
This work was funded by the European Union Seventh Framework Programme. We thank the Klaus Tschira Foundation for infrastructural support at the Heidelberg Institute for Theoretical Studies, and Tilmann Gneiting, the referees, and the editors for their constructive comments.
Appendix
Proof of Theorem 1
In our original notation, the last expression reads |$\, m(t_k) V_{n,k}^2/ \{2n_k \, \dot I_{t_k}(G_k)\} \equiv D_k$| where |$t_k = T(G_k)$|, |$V_{n,k} = n_k^{1/2}\{I_{t_k}(\hat G_{n,k}) - I_{t_k}(G_k)\}$|. Now, let |$\Delta_k = -D_k + S\{T(G_k),\hat G_{n,k}\} - S\{T(G_k),G_k\}$|. Then |$\hat\Delta_k = \Delta_k + o_p(n_k^{-1})$| by (A1) to (A3), and since |$E^\mathcal{W} (\Delta_k) = -E^\mathcal{W} (D_k)$| and |$E^\mathcal{W} (V_{n,k}^2) = I_{t_k}^2(G_k)$|, the theorem follows.
References

{kind=link}