




Summary
In high-dimensional multivariate regression problems, enforcing low rank in the coefficient matrix offers effective dimension reduction, which greatly facilitates parameter estimation and model interpretation. However, commonly used reduced-rank methods are sensitive to data corruption, as the low-rank dependence structure between response variables and predictors is easily distorted by outliers. We propose a robust reduced-rank regression approach for joint modelling and outlier detection. The problem is formulated as a regularized multivariate regression with a sparse mean-shift parameterization, which generalizes and unifies some popular robust multivariate methods. An efficient thresholding-based iterative procedure is developed for optimization. We show that the algorithm is guaranteed to converge and that the coordinatewise minimum point produced is statistically accurate under regularity conditions. Our theoretical investigations focus on non-asymptotic robust analysis, demonstrating that joint rank reduction and outlier detection leads to improved prediction accuracy. In particular, we show that redescending -functions can essentially attain the minimax optimal error rate, and in some less challenging problems convex regularization guarantees the same low error rate. The performance of the proposed method is examined through simulation studies and real-data examples.
1. Introduction
Although reduced-rank regression can substantially reduce the number of free parameters in multivariate problems, it is extremely sensitive to outliers, which are bound to occur; so in real-world data analysis, the low-rank structure could easily be masked or distorted. This is even more serious in high-dimensional or big-data applications. For example, in cancer genetics, multivariate regression is commonly used to explore the associations between genotypical and phenotypical characteristics (Vounou et al., 2010), where employing rank regularization can help to reveal latent regulatory pathways linking the two sets of variables; but pathway recovery should not be distorted by abnormal samples or subjects. As another example, financial time series, even after stationarity transformation, often contain anomalies or have heavier tails than those of a normal distribution, which may jeopardize the recovery of common market behaviours and asset return forecasting; see § 3 in the Supplementary Material.
We propose a novel robust reduced-rank regression method for concurrent robust modelling and outlier identification. We explicitly introduce a sparse mean-shift outlier component and formulate a shrinkage multivariate regression in place of (2), where and/or can be much larger than . The proposed robust reduced-rank regression provides a general framework and includes M-estimation and principal component pursuit (Huber, 1981; Hampel et al., 2005; Zhou et al., 2010; Candès et al., 2011). All the techniques developed in this work apply to high-dimensional sparse regression with a single response. In § 2 we show that low-rank estimation can be ruined by a single rogue point, and propose a robust reduced-rank estimation framework. A universal connection between the proposed robustification and conventional M-estimation is established, regardless of the size of , or . In § 3 we conduct finite-sample theoretical studies of the proposed robust estimators, with the aim of extending classical robust analysis to multivariate data with possibly large and/or . A computational algorithm developed in § 4 is easy to implement and leads to a coordinatewise minimum point with theoretical guarantees. Applications to real data are demonstrated in § 5. All the proofs and results of simulation studies, as well as a financial example, are given in the Supplementary Material.
The following notation will be used throughout the paper. We denote by the set of natural numbers. We use to denote and to denote the Euler constant. Let . Given any matrix , denotes the orthogonal projection matrix onto the range of , i.e., , where stands for the Moore–Penrose pseudo-inverse. When there is no ambiguity, we also use to denote the column space of . Let denote the Frobenius norm and the spectral norm, and let with denoting the cardinality of the enclosed set. For , and , which gives the number of nonzero rows of . Given , we often denote by . Threshold functions are defined as follows.
(Threshold function). A threshold function is a real-valued function defined for and such that (i) ; (ii) for; (iii) ; and (iv) for.
(Multivariate threshold function). Given any , is defined for any vector by for and otherwise. For any matrix , .
2. Robust reduced-rank regression
2.1 Motivation
Given any finite and with positive definite and , let be a reduced-rank regression estimator which solves (1). Then its finite-sample breakdown point is exactly . Furthermore, for any as in (4), still holds for any finite value of .
The result indicates that a single outlier can completely ruin low-rank matrix estimation, whether one applies a rank constraint or, say, a Schatten -norm penalty. This limits the use of ordinary rank reduction in big-data applications. Because with the low-rank constraint, directly using a robust loss function as in (2) may result in nontrivial computational and theoretical challenges, we will apply a novel additive robustification, motivated by She & Owen (2011).
2.2 The additive framework
We show that the proposed additive outlier characterization indeed comes with a robustness guarantee and, interestingly, generalizes M-estimation to the multivariate rank-deficient setting. We write and .
Theorem 2 holds for all thresholding rules, and commonly used convex and nonconvex penalties are all covered by (5). For example, the convex group penalty is associated with the soft-thresholding . The group penalty can be obtained from (5) with the hard-thresholding and with . Our - coupling framework also covers for , the smoothly clipped absolute deviation penalty (Fan & Li, 2001), the minimax concave penalty (Zhang, 2010a), and the capped penalty (Zhang, 2010b) as particular instances; see She (2012).
The universal link between (10) and (11) provides insight into the choice of regularization. It is easy to verify that the -norm penalty as commonly used in variable selection leads to Huber’s loss, which is prone to masking and swamping and may fail with even moderately leveraged outliers occurring. To handle gross outliers, redescending -functions are often advocated, which amounts to using nonconvex penalties in (10). For example, Hampel’s three-part (Hampel et al., 2005) can be shown to yield Fan and Li’s smoothly clipped absolute deviation penalty; the skipped mean corresponds to the exact penalty; and rank-constrained least trimmed squares can be rephrased as the -constrained form in (12). Our approach not only provides a unified way to robustify low-rank matrix estimation but also facilitates theoretical analysis and computation of reduced-rank M-estimators in high dimensions.
2.3 Connections and extensions
Our robust reduced-rank regression subsumes a special but important case, . This problem is perhaps less challenging than its supervised counterpart, but has wide applications in computer vision and machine learning (Wright et al., 2009; Candès et al., 2011).
Finally, our method can be extended to reduced-rank generalized linear models; see, for example, Yee & Hastie (2003) and She (2013) for computational details. In these scenarios, directly robustifying the loss can be messy, but a sparse outlier term can always be introduced without altering the form of the given loss, so that many algorithms designed for fitting ordinary generalized linear models can be seamlessly applied.
3. Non-asymptotic robust analysis
Theorem 2 provides robustness and some helpful intuition for the proposed method, but it might not be enough from a theoretical point of view. For example, can one justify the need for robustification in estimating a matrix of low rank? Is using redescending -functions still preferable in rank-deficient settings? Unlike in traditional robust analysis, we cannot assume an infinite sample size and a fixed number of predictors or response variables, because and/or can be much larger than in modern applications. Conducting non-asymptotic robust analysis would be desirable. The finite-sample results in this section contribute to this type of robust analysis.
This predictive learning perspective is always legitimate in evaluating the performance of an estimator, and requires no signal strength or model uniqueness assumptions. The -recovery of is fundamental, and such a bound, together with additional regularity assumptions, can easily be adapted to obtain estimation error bounds in different norms as well as selection consistency (Ye & Zhang, 2010; Lounici et al., 2011); see Theorem 10 in the Supplementary Material, for instance. Given a penalty function or, equivalently, a robust loss , we will study the performance of the set of global minimizers to show the ultimate power of the associated method; but our techniques of proof apply more generally (see, e.g., Theorem 7).
We let denote the rank of the true coefficient matrix, and the number of nonzero rows in , i.e., the number of outliers. Let .
On the other hand, the presence of the bias term ensures applicability of robust reduced-rank regression to weakly sparse , and similarly may also deviate from to some extent, as a benefit derived from the bias-variance trade-off.
Our scheme of proof can also be used to show similar conclusions for the doubly penalized form (13) and the doubly constrained form (12), under the general assumption that the noise matrix has sub-Gaussian marginal tails. The following theorem states the result for (12), which is one of our favoured forms in practical data analysis.
Theorem 4 reveals some breakdown point information as a by-product. Specifically, fixing , we contaminate in the set , where is sub-Gaussian and . Given any estimator which implicitly depends on , we define its risk-based finite-sample breakdown point by , where the randomness of the estimator is well accounted for by taking the expectation. Then, for the estimator defined by (12), it follows from Theorem 4 that .
We emphasize that neither Theorem 3 nor Theorem 4 places any requirement on , in contrast to Theorem 6 below.
Let be a nondecreasing loss function with ≢ 0.
We give some examples of to illustrate the conclusion. Using the indicator function , for any estimator , holds with positive probability. For , Theorem 5 shows that the risk is bounded from below by up to some multiplicative constant. Therefore, (17) attains the minimax optimal rate up to a mild logarithmic factor, showing the advantage of utilizing redescending -functions in robust low-rank estimation. The analysis is non-asymptotic and applies to any , and .
Convex methods are however sometimes useful. In some less challenging problems, where some incoherence regularity condition is satisfied by the augmented design matrix, Huber’s can achieve the same low error rate. The result of the following theorem can be extended to any subadditive penalties with the associated sandwiched between Huber’s and .
Compared with (16), (18) has an additional factor of on the right-hand side. Some numerical experiments on the magnitude of , presented in the Supplementary Material, show that the error bound obtained in Theorem 6 is comparable to (16) in some settings. Also, under a different regularity condition, an estimation error bound on can be obtained. See the Supplementary Material for more details.
Because has low rank, is not null in general. Notable outliers that can affect the projection subspace in performing rank reduction tend to occur in the orthogonal complement of the range of , and so (20) can be arbitrarily large, which echoes the deterministic breakdown-point conclusion in Theorem 1.
4. Computation and tuning
The penalties of interest may be nonconvex in light of the theoretical results in § 3, as stringent incoherence assumptions associated with convex penalties can be much relaxed or even removed. Assuming that is constructed by (5), a simple procedure for solving (22) is as described in Algorithm 1, where the two matrices and are alternately updated with the other held fixed until convergence. Here the multivariate thresholding, , is defined based on ; cf. Definitions 1 and 2.
A robust reduced-rank regression algorithm.
Input , , , , ,
Repeat
(a)
(b)
(c) , as defined in (3)
Until convergence
Step (b) performs simple multivariate thresholding operations and Step (c) performs reduced-rank regression on the adjusted response matrix . We need not explicitly compute to update in the iterative process. In fact, we need only , which depends on through , or when . The eigenvalue decomposition called in (3) has low computational complexity because the rank values of practical interest are often small. Algorithm 1 is simple to implement and cost-effective. For example, even for and , it takes only about 40 seconds to compute a whole solution path for a two-dimensional grid of 100 values and 10 rank values.
Let be an arbitrary thresholding rule, and let be as defined in (22), where is associated with through (5). Then, given any and , the proposed algorithm has the property that for all , and so converges as . Furthermore, under the assumptions that is continuous in the closure of and is uniformly bounded, any accumulation point of is a coordinatewise minimum point, and is a stationary point when ; hence converges monotonically to for some coordinatewise minimum point .
The algorithm can be slightly modified to deal with (8), (12), and (13). For example, we can replace by , applied componentwise, to handle elementwise outliers. The -penalized form with , as well as the constrained form (12), will be used in data analysis and simulation. In implementation, they correspond to applying hard-thresholding and quantile-thresholding operators (She et al., 2013).
In common with most high-breakdown algorithms in robust statistics, we recommend using the multi-sampling iterative strategy (Rousseeuw & van Driessen, 1999). In many practical applications, however, we have found that the initial values can be chosen rather freely. Indeed, Theorem 8 shows that if the problem is regular, our algorithm guarantees low statistical error even without the multi-start strategy.
In the following theorem, given , define where is the essential infimum. By definition, . We use as shorthand for and set with and .
Let be any solution satisfying and with of rank and continuous at . Let be associated with a bounded nonconvex penalty as described in Corollary 1 and let with being a large enough constant. Assume that holds for all satisfying , where , and are constants. Then .
Let , where and . Suppose that the true model is parsimonious in the sense that for some constant . Let where is a positive constant satisfying , and so . Then for sufficiently large values of and , any that minimizes subject to satisfies with probability at least for some constants .
Based on computer experiments, we set and .
5. Arabidopsis thaliana data
We performed extensive simulation studies to compare our method with some classical robust multivariate regression approaches and several reduced-rank methods (Reinsel & Velu, 1998; Tatsuoka & Tyler, 2000; Aelst & Willems, 2005; Roelant et al., 2009; Bunea et al., 2011; Mukherjee & Zhu, 2011) in both low and high dimensions. The results are reported in the Supplementary Material; our robust reduced-rank regression shows performance comparable or superior to the other methods in terms of both prediction and outlier detection.
Isoprenoids are diverse and abundant compounds in plants, where they serve many important biochemical functions and play roles in respiration, photosynthesis and the regulation of growth and development. To examine the regulatory control mechanisms in gene networks for isoprenoids in Arabidopsis thaliana, a genetic association study was conducted, with GeneChip microarray experiments performed to monitor gene expression levels under various experimental conditions (Wille et al., 2004). It was experimentally verified that strong connections exist between some downstream pathways and two isoprenoid biosynthesis pathways. We therefore considered a multivariate regression set-up, with the expression levels of genes from the two isoprenoid biosynthesis pathways serving as predictors, and the expression levels of genes from four downstream pathways, namely plastoquinone, carotenoid, phytosterol and chlorophyll, serving as the responses.
Because of the small sample size relative to the number of unknowns, we applied robust reduced-rank regression with the predictive information criterion for parameter tuning. The final model is of rank five, which means that the effective number of unknowns is reduced by about 80% compared with the least-squares model. Interestingly, our method also identified two outliers, samples 3 and 52. Figure 1 shows the detection paths by plotting the -norm of each row in the estimates for a sequence of values. The two unusual samples are distinctive. The outlyingness could be caused by different experimental conditions. In particular, sample 3 was the only sample with Arabidopsis tissue culture in a baseline experiment. The two outliers have a surprisingly large impact on both coefficient estimation and model prediction. This can be seen from and , where and denote, respectively, the robust reduced-rank regression and the plain reduced-rank regression estimates. In addition, Fig. 1 reveals that sample 27 could be a potential outlier meriting further investigation.
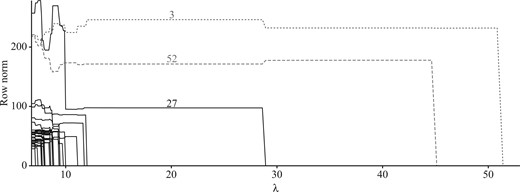
Arabidopsis thaliana data: outlier detection paths obtained by the robust reduced-rank regression. Sample 3 and sample 52 are captured as outliers, whose paths are shown as a dotted line and a dashed line, respectively. The path plot also suggests sample 27 as a potential outlier.
The low-rank model obtained reveals robust score variables, or factors, constructed from isoprenoid biosynthesis pathways, in response to the 62 genes in the four downstream pathways. Let denote the design matrix after removing the two detected outliers, and let be the singular value decomposition of . Then delivers five orthogonal factors, and gives the associated factor coefficients. Figure 2 plots the coefficients of the first three leading factors for all 62 response variables. Given the th factor (), the genes are grouped into the four pathways separated by vertical lines, and two horizontal lines are placed at heights . Therefore, the genes located beyond those two horizontal lines have relatively large-magnitude coefficients on the corresponding factor.
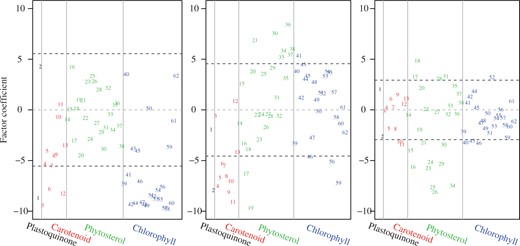
Arabidopsis thaliana data: factor coefficients of the 62 response genes from plastoquinone, carotenoid, phytosterol, and chlorophyll pathways. From left to right the panels correspond to the top three factors estimated by the robust reduced-rank regression. For the th factor (), two horizontal lines are plotted at heights , and three vertical lines separate the genes into four different pathways.
We also tested the significance of the factors in response to each of the 62 genes; see Table 1. Plastoquinone was excluded since it has only two genes and its behaviour couples with that of carotenoid most of the time. Even with the familywise error rate controlled at , the factors obtained are predictive overall according to the significance percentages, although they play very different roles in different pathways. In fact, according to Fig. 2 and Table 1, the genes that are correlated with the first factor are mainly from carotenoid and chlorophyll, and almost all the coefficients there are negative. It seems that the first factor interprets some joint characteristics of carotenoid and chlorophyll; the second factor differentiates phytosterol genes from carotenoid genes; and the third factor appears to contribute mainly to the phytosterol pathway. Therefore, by projecting the data onto a proper low-dimensional subspace in a supervised and robust manner, distinct behaviours of the downstream pathways and their potential subgroup structures can be revealed. Further biological insights could be gained by closely examining the experimental and background conditions.
Arabidopsis thaliana data: percentage of genes on each response pathway that show significance of a given factor, with the familywise error rate controlled at level
| Pathway | Number of genes | Factor 1 | Factor 2 | Factor 3 |
|---|---|---|---|---|
| Carotenoid | 11 | 55% | 73% | 9% |
| Phytosterol | 25 | 20% | 48% | 32% |
| Chlorophyl | 24 | 75% | 21% | 0% |
| Pathway | Number of genes | Factor 1 | Factor 2 | Factor 3 |
|---|---|---|---|---|
| Carotenoid | 11 | 55% | 73% | 9% |
| Phytosterol | 25 | 20% | 48% | 32% |
| Chlorophyl | 24 | 75% | 21% | 0% |
Arabidopsis thaliana data: percentage of genes on each response pathway that show significance of a given factor, with the familywise error rate controlled at level
| Pathway | Number of genes | Factor 1 | Factor 2 | Factor 3 |
|---|---|---|---|---|
| Carotenoid | 11 | 55% | 73% | 9% |
| Phytosterol | 25 | 20% | 48% | 32% |
| Chlorophyl | 24 | 75% | 21% | 0% |
| Pathway | Number of genes | Factor 1 | Factor 2 | Factor 3 |
|---|---|---|---|---|
| Carotenoid | 11 | 55% | 73% | 9% |
| Phytosterol | 25 | 20% | 48% | 32% |
| Chlorophyl | 24 | 75% | 21% | 0% |
Acknowledgement
The authors thank the editor, associate editor and referees for suggestions that have significantly improved the paper. The first author thanks Art Owen for his valuable comments on an earlier version of the manuscript, and Elvezio Ronchetti for inspiration. This work was partially supported by the U.S. National Science Foundation, National Institutes of Health and Department of Defense.
Supplementary material
Supplementary material available at Biometrika online includes all technical details of the proofs, a financial example and the simulation studies.
References

{kind=link}
{kind=link}