




SUMMARY
Commonly used interval procedures for multigroup data attain their nominal coverage rates across a population of groups on average, but their actual coverage rate for a given group will be above or below the nominal rate, depending on the group mean. While correct coverage for a given group can be achieved with a standard |$t$|-interval, this approach is not adaptive to the available information about the distribution of group-specific means. In this article we construct confidence intervals that have a constant frequentist coverage rate and that make use of information about across-group heterogeneity, resulting in constant-coverage intervals that are narrower than standard |$t$|-intervals on average across groups. Such intervals are constructed by inverting biased Bayes-optimal tests for the mean of each group, where the prior distribution for a given group is estimated with data from the other groups.
1. Introduction
A commonly used experimental design is the one-way layout, in which a random sample |$Y_{1,j},\ldots, Y_{n_j,j}$| is obtained from each of several related groups |$j\in \{1,\ldots, p\}$|. The standard normal-theory model for data from such a design is that |$Y_{i,j} \sim N(\theta_j,\sigma^2)$| independently within and across groups. Inference for the |$\theta_j$| typically proceeds in one of two ways. The classical approach is to use the sample mean |$\bar y_j$| as an estimator of |$\theta_j$|, and to use the standard |$t$|-interval as a confidence interval. Such an approach essentially makes inference for each |$\theta_j$| using only data from group |$j$|, although a pooled estimate of |$\sigma^2$| is often used. The estimator of each |$\theta_j$| is unbiased, and the confidence interval for each |$\theta_j$| has the desired coverage rate.
The intuition behind our procedure is as follows: while the standard |$t$|-interval for a single group is uniformly most accurate among unbiased interval procedures, it is not uniformly most accurate among all procedures. We define classes of biased hypothesis tests for a normal mean, inversion of which generates |$1-\alpha$| frequentist |$t$|-intervals that are more accurate than the standard |$t$|-interval for some values of the parameter space, but are less accurate elsewhere. The class of tests can be chosen to minimize an expected width with respect to a prior distribution for the population mean, yielding a confidence interval procedure that is Bayes-optimal among all procedures that have |$1-\alpha$| frequentist coverage. Such a procedure may be viewed as frequentist but assisted by Bayes. In a multigroup setting, the prior for a group mean is replaced by a model for across-group heterogeneity. The parameters in this model can be estimated using data from all of the groups, yielding an empirical Bayes-optimal confidence interval procedure that maintains a coverage rate which is constant as a function of the group means.
Several authors have studied constant-coverage interval procedures in the single-group case that differ from the standard procedure. Such alternative procedures generally make use of some sort of prior knowledge about the population mean. In particular, our work builds upon that of Pratt (1963), who studied the Bayes-optimal |$z$|-interval for the case where |$\sigma^2$| is known. Other related work includes that of Puza & O’Neill (2006), Farchione & Kabaila (2008) and Kabaila & Tissera (2014), who developed procedures which make use of prior knowledge that the mean is near a prespecified parameter value, such as zero. The procedures developed in the latter two articles have shorter expected widths near this special value, but revert to standard procedures when the data are far from this point. The former work was extended in Puza & O’Neill (2009) and Puza & Yang (2011) to provide confidence intervals for the means of Poisson and binomial populations in cases where there are known constraints on the parameter. Related to this, Evans et al. (2005) obtained minimax interval procedures for cases where prior knowledge takes the form of bounds on the parameter values.
2. Bayes-optimal frequentist intervals
2.1. Pratt’s |$z$|-interval
For our current model of interest, |$Y\sim N(\theta,\sigma^2)$| with |$\sigma^2$| known, there does not exist a procedure that uniformly minimizes this risk over all values of |$\theta$|. However, there exist optimal procedures within certain subclasses of procedures. For example, the standard |$z$|-interval, given by |$C_z(y) =( y+\sigma z_{\alpha/2} ,\, y+\sigma z_{1-\alpha/2})$|, minimizes the risk among all unbiased procedures derived by inversion of unbiased tests of |$H_\theta$| versus |$K_\theta$|, and so is the uniformly most accurate unbiased procedure.
The Bayes-optimal |$1-\alpha$| procedure is obtained by choosing |$A(\theta)$| to minimize |${\rm pr}\{Y\in A(\theta)\}$| for each |$\theta\in\mathbb R$| or, equivalently, to maximize the probability of |$H_\theta$| being rejected under the marginal distribution |$P_\pi$| for |$Y$| that is induced by |$\pi$|. This means that the optimal |$A(\theta)$| is the acceptance region of the most powerful test of the simple hypothesis |$H_\theta: Y \sim P_\theta$| versus the simple hypothesis |$K_\pi: Y \sim P_\pi$|. The confidence region obtained by inversion of this collection of acceptance regions is Bayes-optimal among all procedures having |$1-\alpha$| frequentist coverage.
Using this logic, Pratt (1963) derived and studied the Bayes-optimal frequentist procedure for the model |$Y\sim N(\theta,\sigma^2)$| with |$\sigma^2$| known and prior distribution |$\theta\sim N(\mu,\tau^2)$|. Under this distribution for |$\theta$|, the marginal distribution of |$Y$| is |$N(\mu,\tau^2+\sigma^2)$|. The Bayes-optimal procedure is therefore obtained by inverting acceptance regions |$A(\theta)$| of the most powerful tests of |$H_\theta: Y\sim N(\theta,\sigma^2)$| versus |$K_\pi: Y\sim N(\mu,\tau^2+\sigma^2)$| for each |$\theta$|. This optimal procedure is an interval, the endpoints of which may be obtained by solving two nonlinear equations.
The procedure used to obtain Pratt’s |$z$|-interval and the form used by Pratt are not immediately extendable to the more realistic situation in which |$Y_1,\ldots, Y_n$| is a random sample from a |$N(\theta, \sigma^2)$| population where both |$\theta$| and |$\sigma^2$| are unknown. The primary reason is that in this case the Bayes-optimal acceptance region depends on the unknown value of |$\sigma^2$| or, to put it another way, the null hypothesis |$H_\theta$| is composite. However, the situation is not too difficult to remedy. Below we re-express Pratt’s |$z$|-interval in terms of a function that controls where the Type I error is spent. We then define a class of |$t$|-intervals based on such functions, from which we obtain the Bayes-optimal |$t$|-interval for the case where |$\sigma^2$| is unknown.
2.2. The Bayes-optimal |$w$|-function
For the model |$\{Y\sim N(\theta,\sigma^2), \, \theta\in \mathbb R\}$|, we may limit consideration of confidence procedures to those obtained by inverting collections of two-sided tests.
Suppose that the distribution of |$Y$| belongs to a one-parameter exponential family with parameter |$\theta \in \mathbb{R}$|. For any confidence region procedure |$\tilde C$| there exists a procedure |$C$|, obtained by inverting a collection of two-sided tests, that has the same coverage as |$\tilde C$| and a risk less than or equal to that of |$\tilde C$|.
This proposition follows from Ferguson (1967, § 5.3), which says that for any level-|$\alpha$| test of a point null hypothesis for a one-parameter exponential family, there exists a two-sided test of equal or greater power.
That this procedure has |$1-\alpha$| constant coverage follows from the fact that it is obtained from the inversion of a class of level-|$\alpha$| tests. Alternatively, the constant-coverage property of (3) can be shown directly, as was done in Puza & O’Neill (2006). This calculation is provided for clarity here.
If |$w:\mathbb R \rightarrow [0,1]$|, then |$C_w$| as given by (3) has constant coverage, that is, |${\rm pr}\{ \theta \in C_w(Y) \mid \theta,\sigma^2 \} =1-\alpha$| for every |$\theta\in\mathbb R$| and |$\sigma^2>0$|.
The coverage probability is |$ {\rm pr}\{ -z_{1-\alpha w(\theta) } < (Y-\theta)/\sigma < -z_{\alpha\{1- w(\theta)\} } \mid \theta,\sigma^2 \} \text{.} $| Since |$(Y-\theta)/\sigma$| is standard normal, this reduces to |$ [ 1 - \alpha\{1-w(\theta)\} ] - \alpha w(\theta) = 1-\alpha $|. □
Every such |$w$|-function corresponds to a confidence procedure that has exact |$1-\alpha$| constant coverage; |$w$| can even be stochastic if it is independent of |$Y$|.
The usual |$z$|-interval is |$ C_{1/2}(y) = \{ \theta : y+\sigma z_{\alpha /2 } < \theta < y+\sigma z_{1-\alpha/2} \}$|, corresponding to a constant |$w$|-function of |$w(\theta)=1/2$|. For the prior distribution |$\theta\sim N(\mu,\tau^2)$| considered by Pratt, the optimal |$w$|-function depends on |$\psi=(\mu,\tau^2,\sigma^2)$| and is given as follows.
Let |$Y\sim N(\theta,\sigma^2)$| with |$\theta\sim N(\mu,\tau^2)$|, and let |$w:\mathbb R \rightarrow [0,1]$|. Then |$R(\psi , C_{w_\psi} ) \leqslant R(\psi ,C_w)$| where |$ w_\psi(\theta) = g^{-1} \{ 2\sigma(\theta-\mu)/\tau^2 \} $| with |$g(w) = \Phi^{-1}(\alpha w) - \Phi^{-1}\{\alpha(1-w) \}$|. The function |$w_\psi(\theta)$| is a continuous strictly increasing function of |$\theta$|.
As stated in Pratt (1963) but not proven, |$C_{w_{\psi}}(y)$| is actually an interval for each |$y\in \mathbb R$|, and so |$C_{w_\psi}$| is a confidence interval procedure. In fact, a confidence procedure |$C_w$| will be an interval procedure as long as the |$w$|-function is continuous and nondecreasing.
Let |$w: \mathbb R \rightarrow [0,1]$| be a continuous nondecreasing function. Then the set |$C_w(y) = \{ \theta : y+\sigma z_{\alpha \{1-w(\theta)\}} < \theta < y+\sigma z_{1-\alpha w(\theta)} \} $| is the interval |$(\theta^{\rm L},\theta^{\rm U})$|, where to |$\theta^{\rm L} = y+ \sigma z_{\alpha\{1-w(\theta^{\rm L})\}}$| and |$\theta^{\rm U} = y+ \sigma z_{1-\alpha w(\theta^{\rm U})}$|.
Some aspects of Pratt’s |$z$|-interval are displayed in Fig. 1. Panel (a) plots the |$w$|-functions corresponding to the Bayes-optimal 95% confidence interval procedures for |$\sigma^2=1$|, |$\mu=0$| and |$\tau^2 \in \{1/4,1,4\}$|. At varying rates depending on |$\tau^2$|, the |$w$|-functions approach 0 and 1 as |$\theta$| moves towards |$-\infty$| and |$\infty$|, respectively. The level-|$\alpha$| tests corresponding to these |$w$|-functions are spending more of their Type I error on |$y$|-values that are likely under the |$N(\mu,\sigma^2+\tau^2)$| prior predictive distribution of |$Y$|. This makes the intervals narrower than the usual interval when |$y$| is near |$\mu$|, and wider when |$y$| is far from |$\mu$|, as shown in Fig. 1(b). In particular, at |$y=\mu$|, the 95% interval with |$\tau^2=1/4$| has a width of 3|$\cdot$|29, which is about 84% that of the standard interval. If |$\tau^2=0$|, then |$w(\theta)=1$| if |$\theta>\mu$| and |$w(\theta)=0$| if |$\theta< \mu$|. The value of |$w(\mu)$| when |$\tau^2=0$| does not affect the width of the confidence interval, but can affect whether or not |$\mu$| is included in the interval as an endpoint. We suggest taking |$w(\mu)$| to be |$1/2$| when |$\tau^2=0$|, as it is in the case of |$\tau^2>0$|.
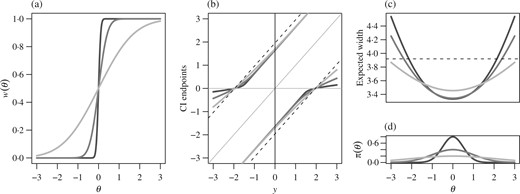
Descriptions of Pratt’s 95% |$z$|-interval procedure: (a) Bayes-optimal |$w$|-functions for |$\tau^2=1/4,1,4$| in decreasingly dark lines; (b) the corresponding confidence interval, CI, procedures, with the standard procedure represented by dashed lines; (c) the expected widths of the 95% |$z$|-intervals for the three values of |$\tau^2$|, along with (d) the corresponding prior densities. Dashed lines in (b)–(d) correspond to the usual |$z$|-interval.
Average performance across |$y$|-values, or the expected confidence interval width, is displayed in Fig. 1(c). The expected widths of Pratt’s |$z$|-intervals are smaller than those of the usual intervals for values of |$\theta$| near |$\mu$|, 15% less for |$\theta=\mu$| and |$\tau^2=1/4$|, but can be much greater for |$\theta$|-values far away from |$\mu$|, particularly for small values of |$\tau^2$|. Relative to small values of |$\tau^2$|, the larger value |$\tau^2=4$| enjoys better performance than the standard interval over a wider range of |$\theta$|-values, but the improvement is not as large near |$\mu$|. Additional calculations show that the performance of Pratt’s |$z$|-interval near |$\mu$| improves as |$\alpha$| increases, as compared to the usual interval. For example, with |$\tau^2=1/4$| and |$\alpha=0{\cdot}50$|, the width of Pratt’s interval at |$y=\mu$| is about 25% that of the usual interval, and its risk at |$\theta=\mu$| is 60% that of the usual interval.
2.3. Bayes-optimal |$t$|-intervals
If |$w:\mathbb R \rightarrow [0,1]$|, then |$C_w$| as defined by (4) has constant coverage, that is, |${\rm pr}\{ \theta \in C_w(\bar Y,S^2) \mid \theta,\sigma^2 \} =1-\alpha$| for every |$\theta\in\mathbb R$| and |$\sigma^2>0$|.
Additionally, |$C_w$| is an interval as long as |$w$| is a continuous nondecreasing function.
Let |$w: \mathbb R \rightarrow [0,1]$| be a continuous nondecreasing function. Then the set |$C_w(\bar y,s^2) = \{ \theta: \bar y + n^{-1/2}s t_{\alpha\{1-w(\theta)\}} < \theta < \bar y + n^{-1/2}s t_{1-\alpha w(\theta)} \}$| is the interval |$(\theta^{\rm L},\theta^{\rm U})$|, where |$\theta^{\rm L} = \bar y+ n^{-1/2} s t_{\alpha\{1-w(\theta^{\rm L})\}}$| and |$\theta^{\rm U} = \bar y+ n^{-1/2} s t_{1-\alpha w(\theta^{\rm U})}$|.
We provide R code in the Supplementary Material for obtaining |$w_{\pi}(\theta)$| and the corresponding Bayes-optimal |$t$|-interval |$C_{\pi}( \bar y,s^2)$| for |$\theta$| and |$\sigma^2$| being a priori independently distributed as normal and inverse-gamma random variables. For comparison with Pratt’s |$z$|-interval, one can consider the case where |$n=10$|, |$1/\sigma^2 \sim {\rm Ga}(1,10)$| and |$\theta\sim N(0,\tau^2)$| for |$\tau^2 \in \{1/4,1,4\}$|. This makes the prior median of |$\sigma^2$| near 10 and the variance of |$\bar Y$| near 1, and so the variance of |$\bar Y$| here is comparable to the variance of |$Y$| in § 2.1. Plots analogous to the panels of Fig. 1 are very similar to those in the |$z$|-interval case. In particular, the |$t$|-intervals resemble the corresponding |$z$|-intervals, but are slightly wider due to the use of |$t$|-quantiles instead of |$z$|-quantiles.
3. Empirical Bayes-optimal frequentist intervals for multigroup data
3.1. Constant-coverage empirical Bayes intervals via data splitting
A potential obstacle to the adoption of Bayes-optimal frequentist confidence intervals is the aversion that many researchers have to specifying a distribution over |$\theta$|. However, in multigroup data settings, probabilistic information about the mean of one group may be obtained from data on the other groups. This information can be used to choose a |$w$|-function with which to construct a confidence interval. For example, suppose we have a class of |$w$|-functions |$\{ w_\psi : \psi\in \Psi\}$| we wish to select from, such that |$w_\psi:\mathbb R\rightarrow [0,1]$| for each |$\psi\in \Psi$|. Let |$Y_1,\ldots, Y_n$| be a random sample from a |$N(\theta,\sigma^2)$| population, and let |$\hat\psi$| be a random variable, independent of |$Y_1,\ldots, Y_n$| and taking values in |$\Psi$|. Then the random interval procedure given by |$C_{w_{\hat\psi}}$| will still have constant |$1-\alpha$| coverage, even though the |$w$|-function is stochastic.
If |$\bar Y \sim N(\theta, \sigma^2/n)$| and |$ (n-1) S^2/\sigma^2 \sim \chi^2_{n-1}$|, and if |$\bar Y$|, |$S^2$| and |$\hat\psi$| are independent, then |${\rm pr}\{ \theta\in C_{w_{\hat\psi}}(\bar Y, S^2) \mid \theta,\sigma^2\}=1-\alpha$|.
Because |$\hat\psi$| is independent of |$(\bar Y, S^2)$|, the coverage of |$C_{w_{\hat\psi}}$| conditional on |$\hat\psi= \psi$| is the same as that of |$C_{w_{\psi}}$|, which has coverage |$1-\alpha$| for all |$\psi\in \Psi$| by Proposition 5. □
In the multigroup setting, an adaptive procedure |$C_{w_{\hat\psi}}$| for the mean |$\theta_j$| of one group may be constructed by estimating the parameters |$\hat\psi$| in the hierarchical normal model using data from the other groups. Such an interval will have exact |$1-\alpha$| coverage for every value of |$\theta_j$| by Proposition 7, but will also have a shorter expected width for values of |$\theta_j$| that are deemed likely by |$\hat\psi$|.
3.2. Asymptotically optimal procedure for homoscedastic groups
Consider the case of |$p$| normal populations with means |$\theta_1,\ldots, \theta_p$| and with common variance |$\sigma^2$| and sample size |$n$|, so that |$Y_{i,j} \sim N(\theta_j,\sigma^2)$| independently within and across groups. We use a common sample size solely to simplify notation. The standard hierarchical normal model posits that the heterogeneity across groups can be described by a normal distribution, so that |$\theta_1,\ldots, \theta_p$| are a random sample from a |$N(\mu,\tau^2)$| population. In the multigroup setting, this normal distribution is not considered to be a prior distribution for a single |$\theta_j$|, but instead is a statistical model for the across-group heterogeneity of |$\theta_1,\ldots, \theta_p$|. The parameters describing the across- and within-group heterogeneity are |$\psi=(\mu,\tau^2,\sigma^2)$|.
The random interval |$C_{w_{\hat\psi}}(\bar Y,S^2)$| differs from the optimal interval |$C_{w_\psi}(\bar Y)$| in three ways: first, the former uses |$S^2$| instead of |$\sigma^2$| to scale the endpoints of the interval; second, the former uses |$t$|-quantiles instead of standard normal quantiles; third, the former uses |$\hat \psi$| to define the |$w$|-function, instead of |$\psi$|. Now, as |$q$| increases, |$S^2 \rightarrow \sigma^2$| almost surely, and the |$t$|-quantiles in (7) converge to the corresponding |$z$|-quantiles. If we are also in a scenario where |$\hat \psi$| can be indexed by |$q$| and |$\hat \psi \rightarrow \psi$| almost surely, then we expect that |$w_{\hat \psi}$| converges to |$w_{\psi}$| and that the risk of |$C_{w_{\hat\psi}}$| converges to the oracle risk of |$C_{w_{\psi}}$|.
Let |$\bar Y\sim N(\theta,\sigma^2/n)$| and |$q S^2/\sigma^2 \sim \chi^2_q$|, and let |$\hat \psi$| be independent for each value of |$q$|, with |$\hat \psi \rightarrow \psi$| almost surely as |$q\rightarrow \infty$|. Then:
(i) |$C_{w_{\hat\psi}}$| defined in (7) is a |$1-\alpha$| confidence interval procedure for each value of |$\theta$| and |$q$|;
(ii) |${E}{ | C_{w_{\hat\psi}}|} \rightarrow {E}{ | C_{w_{\psi}}|}$| as |$q\rightarrow \infty$|.
In practice, for finite |$p$|, different choices of |$p_1$| and |$p_2$| will affect the resulting confidence intervals. Since the minimal width of each interval is directly tied to the degrees of freedom |$p_1(n-1)$| of the variance estimate |$\tilde S_j^2$|, we suggest choosing |$p_1$| to ensure that the quantiles of the |$t_{p_1(n-1)}$| distribution are reasonably close to those of the standard normal distribution. If either |$p$| or |$n$| is large, this can be done while still allowing |$p_2$| to be large enough for |$\hat \psi_{-j}= (\hat \mu_{-j},\hat\tau^2_{-j},\hat\sigma^2_{-j}/n)$| to be useful.
By constructing |$\hat\psi_{-j}$| from data that are independent of data from group |$j$|, we have ensured that the conditions of Proposition 7 are met and that exact constant coverage is maintained regardless of the values of |$n_j$| and |$p$|. However, if the number of groups is large, then calculating a separate |$\hat\psi_{-j}$| for each group |$j$| may be quite time-consuming. One alternative is to simply compute a single |$\hat\psi$| using data from all of the groups, to be used for the adaptive confidence intervals for all groups. If |$p$| is large, then the dependence between |$\hat\psi$| and the data in any one group should be small, and so using a single |$\hat\psi$| for all groups should yield close to correct coverage rates for large |$p$|, and asymptotically correct coverage rates as |$p\rightarrow \infty$|.
3.3. Procedure for heteroscedastic groups
To create an adaptive |$t$|-interval for a given group |$j$|, we obtain estimates |$(\hat \mu_{-j},\hat \tau^2_{-j},\hat a_{-j},\hat b_{-j})$| using the procedure described above with data from all groups except group |$j$|. The |$w$|-function |$w_j$| for group |$j$| is taken to be the Bayes-optimal |$w$|-function defined by (6), under the estimated prior |$\theta_j \sim N(\hat \mu_{-j} ,\hat \tau^2_{-j})$| and |$1/\sigma^2_j \sim \text{Ga}(\hat a_{-j} ,\hat b_{-j})$|. The independence of |$(\bar Y_j,S^2_j)$| and |$(\hat \mu_{-j},\hat \tau^2_{-j} ,\hat a_{-j},\hat b_{-j})$| ensures that the resulting |$t$|-interval has exact |$1-\alpha$| coverage, conditional on |$\theta_1,\ldots, \theta_p$| and |$\sigma_1^2,\ldots, \sigma_p^2$|.
We speculate that this procedure enjoys similar optimality properties to those of the approach for homoscedastic groups described in § 3.1: if the heteroscedastic hierarchical model is correct, then as the number |$p$| of groups increases, the estimates |$(\hat \mu_{-j},\hat \tau^2_{-j},\hat a_{-j},\hat b_{-j})$| will converge to |$(\mu,\tau^2,a,b)$| and the interval for a given group will converge to the corresponding Bayes-optimal interval. So far we have been unable to prove this, the primary difficulty being that the Bayes-optimal |$w$|-function given by (6) is not easily studied analytically.
4. Radon data example
4.1. County-specific confidence intervals
Price et al. (1996) used data from a U.S. Environmental Protection Agency study to estimate county-specific mean radon levels in the state of Minnesota. For each county in Minnesota, a simple random sample of homes was obtained and their radon levels were measured. This resulted in a dataset consisting of log radon levels measured in 919 homes, each located in one of 85 counties. County-specific sample sizes ranged from 1 to 116 homes.
Since the number of homes in each county |$j$| is generally much larger than its sample size, we treat the simple random sample from county |$j$| as a random sample with replacement. As the observed data on log radon levels appear roughly normally distributed in each county, we assume throughout this section that |$Y_{i,j} \sim N(\theta_j, \sigma^2_j)$| independently within and across groups, where |$Y_{i,j}$| is the log radon level of the |$i$|th home sampled from the |$j$|th county. In this model, |$\theta_j$| and |$\sigma^2_j$| represent the mean and variance of home-level radon levels in county |$j$|, that is, the mean and variance of the log radon levels that would have been obtained had all homes in the county been included in the study.
Under the assumptions of a constant across-counties variance |$\sigma^2$| and the normal hierarchical model |$\theta_j\sim N(\mu,\tau^2)$|, the maximum likelihood estimates of |$\sigma^2$|, |$\mu$| and |$\tau^2$| are |$\hat \sigma^2 = 0{\cdot}637$|, |$\hat \mu =1{\cdot}313$| and |$\hat \tau^2 =0{\cdot}096$|. The estimate of the across-counties variability is substantially smaller than the estimate of within-county variability, suggesting that there is useful information to be shared across the groups. However, Levene’s test rejects homoscedasticity with a |$p$|-value of |$0{\cdot}011$|. For this reason, we use the adaptive |$t$|-interval procedure described in § 3.2 for each group, having the form |$\{ \theta_j: \bar y_j + n_j^{-1/2} s_jt_{\alpha\{1-w_j(\theta_j)\}} < \theta_j < \bar y_j + n_j^{-1/2}s_j t_{1-\alpha w_j(\theta_j)} \}$| where |$\alpha=0{\cdot}05$|, |$\bar y_j$| and |$s^2_j$| are the sample mean and variance of county |$j$|, and |$w_j$| is the optimal |$w$|-function assuming |$\theta_j \sim N( \hat \mu_{-j}, \hat \tau^2_{-j})$| and |$1/\sigma^2_j \sim $| Ga |$(\hat a_{-j},\hat b_{-j})$|, with |$\hat\mu_{-j},\hat \tau^2_{-j},\hat a_{-j}$| and |$\hat b_{-j}$| estimated from the counties other than county |$j$|. These intervals have 95% coverage for each county, assuming only within-group normality.
We constructed the adaptive and standard intervals for each of the 82 counties that had a sample size greater than 1, i.e., counties for which we could obtain an unbiased within-sample variance estimate. Intervals for counties with sample sizes greater than 2 are displayed in Fig. 2. Intervals based on a sample size of 2 were excluded from the figure because their widths make smaller intervals difficult to visualize. The standard intervals are wider than the adaptive intervals for 77 of the 82 counties, and are 30% wider on average across counties. Generally speaking, the counties for which the adaptive intervals provide the biggest improvement are those with smaller sample sizes and with sample means near the across-group average. Conversely, the five counties for which the standard intervals are narrower than the adaptive intervals are those with moderate to large sample sizes and with sample means somewhat distant from the across-group average.
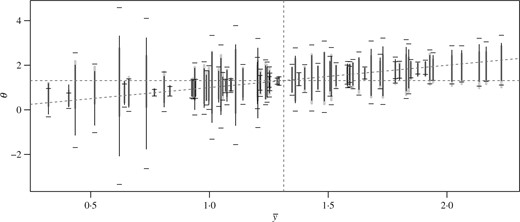
Adaptive, standard and empirical Bayes 95% confidence intervals for the radon dataset: the empirical Bayes intervals are plotted as wide grey lines and the adaptive intervals as narrow black lines, and the horizontal bars represent the endpoints of the standard intervals; vertical and horizontal lines are drawn at |$\sum \bar y_j/p$|.
Also displayed in Fig. 2 are empirical Bayes intervals of the form |$\hat \theta_j \pm t_{1-\alpha/2 } \times (1/\hat \tau_{-j}^2 +n_j/ s^2_j )^{-1/2}$|, where the empirical Bayes estimator is |$\hat\theta_j = (\hat \mu_{-j}/ \hat \tau_{-j}^2 + \bar y_j n_j/ s_j^2)/ ( 1/\hat\tau_j^2 + n_j/ s_j^2 )$| and |$t_{1-\alpha/2}$| is the |$1-\alpha/2$| quantile of the |$t_{n_j-1}$| distribution. As discussed in § 1, such intervals are always narrower than the corresponding standard intervals. For the radon data, they were narrower than the adaptive intervals for 46 of the 82 counties, although about 2% wider on average across counties. However, unlike the adaptive and standard intervals, the empirical Bayes intervals do not have constant coverage: the actual coverage rate of an empirical Bayes interval for a group |$j$| will depend on the unknown value of |$\theta_j$|. We explore this further in the next subsection.
4.2. Risk performance and comparison with posterior intervals
Assuming within-group normality, the adaptive interval procedure described above has 95% coverage for each group |$j$| and for all values of |$\theta_1,\ldots, \theta_p$|. Furthermore, the procedure is designed to approximately minimize the expected risk under the normal hierarchical model among all 95% confidence interval procedures. However, one may wonder how well the adaptive procedure works for fixed values of |$\theta_1,\ldots, \theta_p$|. This question is particularly relevant in cases where the hierarchical model is misspecified, or when a hierarchical model is not appropriate, for example if the groups are not sampled. We investigate this for the radon data with a simulation study in which we take the county-specific sample means and variances as the true county-specific values, that is, we set |$\theta_j = \bar y_j$| and |$\sigma^2_j = s_j^2$| for each county |$j$|. We then simulate |$n_j$| observations for each county |$j$| from the model |$Y_{i,j} \sim N(\theta_j,\sigma^2_j)$|, independently within and across groups.
We generated 25 000 such simulated datasets. For each dataset, we computed the widths of the 95% adaptive, standard and empirical Bayes confidence intervals for each county having a sample size greater than 1. The results of this simulation study are displayed in Fig. 3. Panel (a) shows the expected widths of the adaptive and empirical Bayes procedures relative to those of the standard procedure. Based on the 25 000 simulated datasets, the estimated expected widths across counties were about 2|$\cdot$|28, 1|$\cdot$|60 and 1|$\cdot$|61 for the standard, adaptive and empirical Bayes procedures, respectively. As with the actual interval widths for the nonsimulated data, expected widths of the adaptive intervals are smaller than those of the standard intervals for 79 out of 82 counties. The empirical Bayes intervals are always narrower than the standard intervals for all groups by construction. However, while they tend to be narrower than the adaptive intervals for |$\theta_j$| far from |$\bar\theta=\sum_{j=1}^p \theta_j/p$|, near this average they are often wider than the adaptive intervals. This is not too surprising, as the adaptive intervals are at their narrowest near this overall average, while the empirical Bayes intervals tend to over-cover here. This is illustrated in Fig. 3(b), which shows how the empirical Bayes credible intervals do not have constant coverage across groups, because they are centred around biased estimates that are shrunk towards the estimated overall mean |$\bar \theta$|. If |$\theta_j$| is far from |$\bar\theta$| then the bias is high and the coverage too low, whereas if |$\theta_j$| is near |$\bar\theta$| then the coverage is too high since the variability of the shrinkage estimate |$\hat\theta_j$| is lower than that of |$\bar y_j$|. The group-specific coverage rates of these intervals vary from about 91% to 98%, although the average coverage rate across groups is approximately 95%. In summary, the standard procedure has constant |$1-\alpha$| coverage across groups, but has wider intervals than those obtained from the adaptive and empirical Bayes procedures. The empirical Bayes procedure has narrower intervals but nonconstant coverage. The adaptive procedure has both narrower intervals and constant coverage.
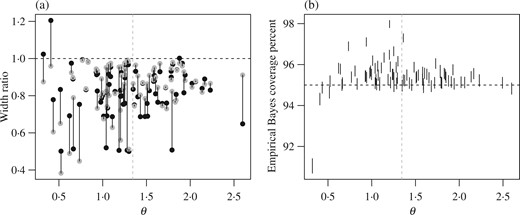
Simulation results: (a) expected interval widths of the adaptive (black) and empirical Bayes (grey) procedures, relative to the standard procedure; (b) empirical Bayes coverage rates, which can be seen to be nonconstant across groups. Error bars are 95% Clopper–Pearson intervals for the coverage rates, based on 25 000 simulated datasets; vertical lines are drawn at |$\sum \theta_j/p$| in each panel.
5. Discussion
Like standard |$t$|-intervals, the coverage properties of our adaptive intervals are based on the assumption that |$n^{1/2} (\bar Y_j - \theta_j)/S_j$| has a |$t$| distribution. Therefore, in terms of coverage rates, the robustness of these adaptive intervals with respect to deviations from within-group normality will be similar to the robustness of the standard |$t$|-interval. On the other hand, if the within-group distributions are normal but the across-group distribution is not, then the adaptive procedure will still maintain the chosen constant coverage rate but will not be optimal. We speculate that in such cases, the adaptive procedure based on a hierarchical normal model, while not optimal, will still asymptotically dominate the standard procedure in terms of risk, because the standard procedure is a limiting case of the adaptive procedure as the across-group variance goes to infinity.
The basic idea behind the adaptive procedure could be implemented with alternative models describing across-group heterogeneity, such as multivariate models that assume a nonexchangeable relationship among the group-level parameters. For example, given spatial information of the counties in the radon example, we could construct a |$w$|-function for each county that depends on data from spatially proximal counties. Such a |$w$|-function would result from using a spatial autoregressive model for the group-level parameters. Another extension would be to use a nonnormal across-group model for the group-level parameters. However, if the within-group and across-group models are not conjugate, then obtaining the Bayes-optimal intervals may require numerical integration and optimization.
Adaptive confidence intervals may also be constructed for contrasts between groups or other linear combinations of parameters. For example, if we are interested in |$\delta_{j,k} = \theta_j - \theta_k$|, then we can construct an adaptive interval from |$\skew3\bar{d}_{j,k} = \bar y_j -\bar y_k$| based on |$\skew3\bar{d}_{j,k} \sim N( \delta_{j,k} , 2 \sigma^2/n )$| and use the model |$\delta_{j,k} \sim N(0 ,2\tau^2)$| to form the |$w$|-function. As long as the estimate of |$\tau^2$| used to form the |$w$|-function is not based on data from group |$j$| or group |$k$|, then such an adaptive procedure will have |$1-\alpha$| constant coverage.
Acknowledgement
We thank the editor, associate editor and reviewers for their consideration of and comments on our paper. This research was supported by the U.S. National Science Foundation.
Supplementary material
Supplementary material available at Biometrika online includes replication code for the numerical results in this article.
Appendix
Setting |$H'(w)=0$| and simplifying shows that a critical point satisfies |${2\theta }/{\tau ^2} = \Phi^{-1}(w\alpha) - \Phi^{-1}\{(1-w)\alpha\} \equiv g(w)$|. It is not difficult to verify that |$g(w)$| is a continuous and strictly increasing function of |$w$|, with range |$(-\infty, \infty)$|. Thus, for each |$\theta$| there is a unique solution to |$H'(w)=0$|, given by |$w_{\psi}(\theta) = g^{-1}({2\theta / \tau ^2})$|, which is a continuous and strictly increasing function of |$\theta$|. Since |$H'(w)$| is continuous on |$[0,1]$| with only one root, and |$\lim_{w \rightarrow 0} H'(w)= -\infty$| and |$\lim_{w \rightarrow 1} H'(w) = \infty$|, we have that |$H(w)$| is minimized by |$w_{\psi}(\theta)$|. Therefore |$w_{\psi}(\theta)$| minimizes the Bayes risk, and |$C_{w_{\psi}}$| is the Bayes-optimal procedure. □
We can write |$C_w(y) = \{ \theta : y< \theta - \sigma l(\theta) , \, \theta - \sigma u(\theta) < y \}$|. Letting |$f_1(\theta) = \theta - \sigma u(\theta)$| and |$f_2(\theta) = \theta - \sigma l(\theta)$|, we first prove that |$C_w(y)$| can also be written as |$C_w(y) = \{ \theta : f_2^{-1}(y)<\theta < f_1^{-1}(y) \}$|. Both |$\Phi^{-1}$| and |$w(\theta)$| are continuous nondecreasing functions. Therefore |$f_1(\theta) = \theta - \Phi^{-1} \{ 1-\alpha w(\theta)\}$| is a strictly increasing continuous function, with |$\lim_{\theta \to -\infty} \theta - \Phi^{-1} \{ 1-\alpha w(\theta)\} = -\infty$| and |$\lim_{\theta \to +\infty} \theta - \Phi^{-1} \{ 1-\alpha w(\theta)\}= +\infty$|. Hence |$f_1^{-1}$| exists and is a strictly increasing continuous function with range |$(-\infty, \infty)$|. Thus |$f_1(\theta) < y$| can also be expressed as |$\theta < f_1^{-1}(y)$|. Similarly, |$y < f_2(\theta) $| can be expressed as |$ f_2^{-1}(y) < \theta$|. Next, in order to show that |$C_w(y)$| is an interval, we need to show that |$f_2^{-1}(y) < f_1^{-1}(y)$|. To see this, we only need to verify that |$ \theta - \sigma \Phi^{-1}\{1-\alpha w(\theta)\} < \theta - \sigma \Phi^{-1}[\alpha\{1-w(\theta)\}]$| or, equivalently, |$\Phi^{-1}\{\alpha w(\theta)\} < \Phi^{-1}[1-\alpha\{1-w(\theta)\}]$|. This follows since |$\Phi^{-1}(x)$| is strictly increasing. Thus |$C_w(y) = \{ \theta : f_2^{-1}(y)<\theta < f_1^{-1}(y) \}$|, which is an interval. □
These proofs are essentially the same as those of Propositions 2 and 4. □
For notational convenience, we write the |$\alpha$|-quantile of the |$t_q$| distribution as |$t_q(\alpha)$|. We first prove a lemma bounding the width of the adaptive |$t$|-interval.
The width of |$C_{w_{\psi }}(\bar y, s^2)$| is less than |$|\bar y-\mu| + sn^{-1/2}\{ |t_q(\alpha/2)|+|t_q(1-\alpha/2)|\}$|.
The first term in (A1) converges to zero because the convergence of |$G_q \to G$| is uniform, and the second term converges to zero because |$(\hat \psi, S^2) \rightarrow (\psi,\sigma^2)$| almost surely. Elaborating on the convergence of the first term, note that |$G_q$| is a monotone sequence of continuous functions: given |$q_2 > q_1$|, we have |$t_{q_2}(1-\alpha w) < t_{q_1}(1- \alpha w)$|; hence |$\theta - Sn^{-1/2}t_{q_2}\{1-\alpha w_{\hat \psi}(\theta)\} > \theta - Sn^{-1/2}t_{q_1}\{1-\alpha w_{\hat \psi}(\theta)\}$| and so |$G_{q_2}(\hat \psi, \bar Y, S^2) < G_{q_1}(\hat \psi, \bar Y, S^2)$|. Therefore, by Dini’s theorem, |$G_q \rightarrow G$| uniformly on a compact set of |$(\hat \psi,S^2)$| values. Since |$(\hat \psi, S^2) \rightarrow (\psi,\sigma^2)$| almost surely, with probability 1 there is an integer |$Q$| such that when |$q> Q$|, |$\:|\hat \psi -\psi| \leqslant c_1$| and |$|S^2 - \sigma^2| \leqslant c_2$| for any two positive constants |$c_1$| and |$c_2$|. Thus, |$G_q$| converges to |$G$| uniformly on this compact set and the first term in (A1) converges to zero.
Since |$|\bar Y|$| is a folded normal random variable with finite mean, it is easy to see that this dominating function is integrable. Therefore, by the dominated convergence theorem we have |$ \lim_{q\rightarrow \infty} {E}{ | C_{w_{\hat\psi}}|} = {E}{ | C_{w_{\psi}}|}$|, which completes the proof of Proposition 8. □

{kind=link}
{kind=link}
{kind=link}