




Summary
This paper concerns numerical assessment of Monte Carlo error in particle filters. We show that by keeping track of certain key features of the genealogical structure arising from resampling operations, it is possible to estimate variances of a number of Monte Carlo approximations that particle filters deliver. All our estimators can be computed from a single run of a particle filter. We establish that, as the number of particles grows, our estimators are weakly consistent for asymptotic variances of the Monte Carlo approximations and some of them are also non-asymptotically unbiased. The asymptotic variances can be decomposed into terms corresponding to each time step of the algorithm, and we show how to estimate each of these terms consistently. When the number of particles may vary over time, this allows approximation of the asymptotically optimal allocation of particle numbers.
1. Introduction
Particle filters, or sequential Monte Carlo methods, provide approximations of integrals with respect to sequences of measures. In popular statistical inference applications, these measures arise naturally from conditional distributions in hidden Markov models, or are constructed artificially to bridge between target distributions in Bayesian analysis. The number of particles used controls the trade-off between computational complexity and accuracy. Theoretical properties of this relationship have been the subject of intensive research; the literature includes central limit theorems (Del Moral & Guionnet, 1999; Chopin, 2004; Künsch, 2005; Douc & Moulines, 2008) and a variety of refined asymptotic (Douc et al., 2005; Del Moral et al., 2007) and non-asymptotic (Del Moral & Miclo, 2001; Cérou et al., 2011) results. These studies provide a wealth of insight into the mathematical behaviour of particle filter approximations and validate them theoretically, but considerably less is known about how, in practice, to extract information from a realization of a single particle filter in order to report numerical measures of Monte Carlo error. This is in notable contrast to other families of Monte Carlo techniques, especially Markov chain Monte Carlo, for which an extensive literature on variance estimation exists. Our main aim is to address this gap.
We introduce particle filters via a framework of Feynman–Kac models (Del Moral, 2004). This allows us to identify the key ingredients of particle filters and the measures they approximate. Based on a single realization of a particle filter, we provide unbiased estimators of the variance and individual asymptotic variance terms for a class of unnormalized particle approximations. No estimators of these quantities based on a single run of a particle filter have previously appeared in the literature, and all of our estimators ultimately arise from particle approximations of quantities appearing in a non-asymptotic second-moment expression. Upon suitable rescaling, we establish that our estimators are weakly consistent for asymptotic variances associated with a larger class of particle approximations. One of these rescaled estimators is closely related to that of Chan & Lai (2013), which is the only other consistent asymptotic variance estimator based on a single realization of a particle filter in the literature. We also demonstrate how one can use the estimators to inform the choice of algorithm parameters in an attempt to improve performance.
2. Particle filters
2.1. Notation and conventions
For a generic measurable space |$(\mathsf{E},\mathcal{E})$|, we denote by |$\mathcal{L}(\mathcal{E})$| the set of |$\mathbb{R}$|-valued, |$\mathcal{E}$|-measurable and bounded functions on |$\mathsf{E}$|. For |$\varphi\in\mathcal{L}(\mathcal{E})$|, |$\mu$| a measure and |$K$| an integral kernel on |$(\mathsf{E},\mathcal{E})$|, we write |$\mu(\varphi)=\int_{\mathsf{E}}\varphi(x)\mu({\rm d}x)$|, |$K(\varphi)(x)=\int_{\mathsf{E}}K(x,{\rm d}x^{\prime})\varphi(x^{\prime})$| and |$\mu K(A)=\int_{\mathsf{E}}\mu({\rm d}x)K(x,A)$|. Constant functions |$x\in E\mapsto c\in\mathbb{R}$| are denoted simply by |$c$|. For |$\varphi\in\mathcal{L}(\mathcal{E})$|, |$\varphi^{\otimes2}(x,x^{\prime})=\varphi(x)\varphi(x^{\prime})$|. The Dirac measure located at |$x$| is denoted by |$\delta_{x}$|. For any sequence |$(a_{n})_{n\in\mathbb{Z}}$| and |$p\leq q$|, |$a_{p:q}=(a_{p},\ldots,a_{q})$| and by convention |$\prod_{p=0}^{-1}a_{p}=1$|. For any |$m\in\mathbb{N}$|, |$[m]=\{1,\ldots,m\}$|. For any |$c\in\mathbb{R}$|, |$\lceil c\rceil$| is the smallest integer greater than or equal to |$c$|. For a vector of positive values |$(a_{1},\ldots,a_{m})$|, we denote by |$\mathcal{C}(a_{1},\ldots,a_{m})$| the categorical distribution over |$\{1,\ldots,m\}$| with probabilities |$(a_{1}/\sum_{i=1}^{m}a_{i},\ldots,a_{m}/\sum_{i=1}^{m}a_{i})$|. When a random variable is indexed by a superscript |$N$|, a sequence of such random variables is implicitly defined by considering each value |$N\in\mathbb{N}$|, and limits will always be taken along this sequence.
2.2. Discrete time Feynman–Kac models
The representation |$\gamma_{n}(\varphi)=E\{\varphi(X_{n})\prod_{p=0}^{n-1}G_{p}(X_{p})\}$|, where the expectation is taken with respect to the Markov chain with initial distribution |$X_{0}\sim M_{0}$| and transitions |$X_{p}\sim M_{p}(X_{p-1},\cdot)$|, establishes the connection to Feynman–Kac formulae. Measures with the structure in (1)–(2) arise in a variety of statistical contexts.
2.3. Motivating examples of Feynman–Kac models
As a first example, consider a hidden Markov model: a bivariate Markov chain |$(X_{p},Y_{p})_{p=0,\ldots,n}$| where |$(X_{p})_{p=0,\ldots,n}$| is itself Markov with initial distribution |$M_{0}$| and transitions |$X_{p}\sim M_{p}(X_{p-1},\cdot)$|, and such that each |$Y_{p}$| is conditionally independent of |$(X_{q},Y_{q};q\neq p)$| given |$X_{p}$|. If the conditional distribution of |$Y_{p}$| given |$X_{p}$| admits a density |$g_{p}(X_{p},\cdot)$| and one fixes a sequence of observed values |$y_{0},\ldots,y_{n-1}$|, then with |$G_{p}(x_{p})=g_{p}(x_{p},y_{p})$|, |$\eta_{n}$| is the conditional distribution of |$X_{n}$| given |$y_{0},\ldots,y_{n-1}$|. Hence, |$\eta_{n}(\varphi)$| is a conditional expectation and |$\gamma_{n}(\mathsf{X})=\gamma_{n}(1)$| is the marginal likelihood of |$y_{0},\ldots,y_{n-1}$|.
2.4. Particle approximations
We now introduce particle approximations of the measures in (1)–(2). Let |$c_{0:n}$| be a sequence of positive real numbers and let |$N\in\mathbb{N}$|. We define a sequence of particle numbers |$N_{0:n}$| by |$N_{p}=\lceil c_{p}N\rceil$| for |$p\in\{0,\ldots,n\}$|. To avoid notational complications, we shall assume throughout that |$c_{0:n}$| and |$N$| are such that |$\text{min}_{p}N_{p}\geq2$|. The particle system consists of a sequence |$\zeta=\zeta_{0:n}$| where for each |$p$|, |$\zeta_{p}=(\zeta_{p}^{1},\ldots,\zeta_{p}^{N_{p}})$| and each |$\zeta_{p}^{i}$| is valued in |$\mathsf{X}$|. To describe the resampling operation we also introduce random variables denoting the indices of the ancestors of each random variable |$\zeta_{p}^{i}$|. That is, for each |$i\in[N_{p}]$|, |$A_{p-1}^{i}$| is a |$[N_{p-1}]$|-valued random variable and we write |$A_{p-1}=(A_{p-1}^{1},\ldots,A_{p-1}^{N_{p}})$| for |$p\in[n]$| and |$A=A_{0:n-1}$|.
A simple description of the particle system is given in Algorithm 1. An important and non-standard feature is that we keep track of a collection of indices |$E_{0:n}$| with |$E_{p}=(E_{p}^{1},\ldots,E_{p}^{N_{p}})$| for each |$p$|, which will be put to use in our variance estimators. We call these Eve indices because |$E_{p}^{i}$| represents the index of the time-|$0$| ancestor of |$\zeta_{p}^{i}$|. The fact that |$N_{p}$| may vary with |$p$| is also atypical, and allows us to address asymptotically optimal particle allocation in § 5.1. On a first reading, one may wish to assume that |$N_{0:n}$| is not time-varying, i.e., |$c_{p}=1$| so |$N_{p}=N$| for all |$p\in\{0,\ldots,n\}$|. Figure 1 is a graphical representation of a realization of a small particle system.
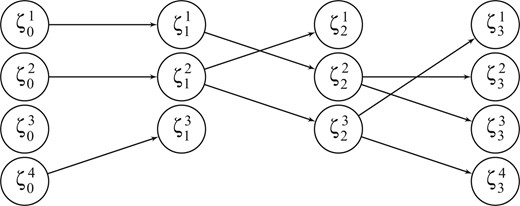
A particle system with |$n=3$| and |$N_{0:3}=(4,3,3,4)$|. An arrow from |$\zeta_{p-1}^{i}$| to |$\zeta_{p}^{j}$| indicates that the ancestor of |$\zeta_{p}^{j}$| is |$\zeta_{p-1}^{i}$|, i.e., |$A_{p-1}^{j}=i$|. In the realization shown, the ancestral indices are |$A_{0}=(1,2,4)$|, |$A_{1}=(2,1,2)$| and |$A_{2}=(3,2,2,3)$|, while |$E_{0}=(1,2,3,4)$|, |$E_{1}=(1,2,4)$|, |$E_{2}=(2,1,2)$| and |$E_{3}=(2,1,1,2)$|.
The particle filter.
At time |$0$|: for each |$i\in[N_{0}]$|, sample |$\zeta_{0}^{i}\sim M_{0}(\cdot)$| and set |$E_{0}^{i}\leftarrow i$|.
At each time |$p=1,\ldots,n$|: for each |$i\in[N_{p}]$|,
a.sample |$A_{p-1}^{i}\sim\mathcal{C}\{G_{p-1}(\zeta_{p-1}^{1}),\ldots,G_{p-1}(\zeta_{p-1}^{N_{p-1}})\}$|.
b.sample |$\zeta_{p}^{i}\sim M_{p}(\zeta_{p-1}^{A_{p-1}^{i}},\cdot)$| and set |$E_{p}^{i}\leftarrow E_{p-1}^{A_{p-1}^{i}}$|.
There exists a map |$\sigma_{n}^{2}:\mathcal{L}(\mathcal{X})\rightarrow[0,\infty)$| such that for any |$\varphi\in\mathcal{L}(\mathcal{X})$|:
(i)|$E\left\{ \gamma_{n}^{N}(\varphi)\right\} =\gamma_{n}(\varphi)$| for all |$N\geq1$|;
(ii)|$\gamma_{n}^{N}(\varphi)\to\gamma_{n}(\varphi)$| almost surely and |$N{\rm var}\left\{ \gamma_{n}^{N}(\varphi)/\gamma_{n}(1)\right\} \to\sigma_{n}^{2}(\varphi)$|;
(iii)|$\eta_{n}^{N}(\varphi)\to\eta_{n}(\varphi)$| almost surely and |$NE\left[\left\{ \eta_{n}^{N}(\varphi)-\eta_{n}(\varphi)\right\} ^{2}\right]\to\sigma_{n}^{2}\{\varphi-\eta_{n}(\varphi)\}$|.
If the number of particles is constant over time, |$N_{p}=N$|, these properties are well known and can be deduced, for example, from various results of Del Moral (2004). The arguments used to treat the general |$N_{p}=\left\lceil c_{p}N\right\rceil$| case are not substantially different, but since they seem not to have been published anywhere in exactly the form we need, we include a proof of Proposition 1 in the Supplementary Material.
2.5. A variance estimator
The following hold for any |$\varphi\in\mathcal{L}(\mathcal{X})$|, with |$\sigma_{n}^{2}(\cdot)$| as in Proposition 1:
(i)|$E\left\{ \gamma_{n}^{N}(1)^{2}V_{n}^{N}(\varphi)\right\} ={\rm var}\left\{ \gamma_{n}^{N}(\varphi)\right\}$| for all |$N\geq1$|;
(ii)|$NV_{n}^{N}(\varphi)\to\sigma_{n}^{2}(\varphi)$| in probability;
(iii)|$NV_{n}^{N}\{\varphi-\eta_{n}^{N}(\varphi)\}\to\sigma_{n}^{2}\{\varphi-\eta_{n}(\varphi)\}$| in probability.
Observe the resemblance between the right-hand sides of (4) and (5): the role of |$X_{i}^{2}$| is played by |$\sum_{j:E_{n}^{j}=i}\varphi(\zeta_{n}^{j})^{2}$|, the sum of |$\varphi^{2}$| evaluated at the descendants of |$\zeta_{0}^{i}$|. This change, and the product term |$\prod_{p=0}^{n}N_{p}/(N_{p}-1)$| replacing |$N/(N-1)$|, arise from the nontrivial dependence structure associated with |$\zeta_{0},\ldots,\zeta_{n}$|. One of the main difficulties we face is to develop a suitable mathematical perspective from which to account for this dependence and establish Theorem 1.
The main statistical implication of Theorem 1 is that the variance estimators are weakly consistent as |$N\rightarrow\infty$| with |$n$| fixed. In the opposite regime, where |$N$| is fixed and |$n\rightarrow\infty$|, the estimators degenerate because the resampling operations cause |$E_{n}^{1},\ldots,E_{n}^{N}$| to eventually become equal. Using results reported here, Olsson & Douc (2018) address the degeneracy issue by modifying |$\hat{\sigma}_{{\rm CL}}^{2}$| so that ancestries are traced only over a fixed time horizon.
3. Moment properties of the particle approximations
3.1. Genealogical tracing variables
Our next step is to introduce some auxiliary random variables associated with the genealogical structure of the particle system. These variables are introduced only for purposes of analysis: they will assist in deriving and justifying our variance estimators. Given |$(A,\zeta)$|, the first collection of variables, |$K^{1}=(K_{0}^{1},\ldots,K_{n}^{1})$|, is conditionally distributed as follows: |$K_{n}^{1}$| is uniformly distributed on |$[N_{n}]$| and for each |$p=n-1,\ldots,0$|, |$K_{p}^{1}=A_{p}^{K_{p+1}^{1}}$|. Given |$(A,\zeta)$| and |$K^{1}$|, the second collection of variables, |$K^{2}=(K_{0}^{2},\ldots,K_{n}^{2})$|, is conditionally distributed as follows: |$K_{n}^{2}$| is uniformly distributed on |$[N_{n}]$| and for each |$p=n-1,\ldots,0$| we have |$K_{p}^{2}=A_{p}^{K_{p+1}^{2}}$| if |$K_{p+1}^{2}\neq K_{p+1}^{1}$| and |$K_{p}^{2}\sim\mathcal{C}\{G_{p}(\zeta_{p}^{1}),\ldots,G_{p}(\zeta_{p}^{N_{p}})\}$| if |$K_{p+1}^{2}=K_{p+1}^{1}$|. The interpretation of |$K^{1}$| is that it traces backwards in time the ancestral lineage of a particle chosen randomly from the population at time |$n$|. The interpretation of |$K^{2}$| is slightly more complicated: it traces backwards in time a sequence of broken ancestral lineages, where breaks occur when components of |$K^{1}$| and |$K^{2}$| coincide.
3.2. Lack of bias and second moment of |$\gamma_{n}^{N}(\varphi)$|
We now give expressions for the first two moments of |$\gamma_{n}^{N}(\varphi)$|.
For any |$\varphi\in\mathcal{L}(\mathcal{X})$|, |$E\left\{ \gamma_{n}^{N}(1)\varphi(\zeta_{n}^{K_{n}^{1}})\right\} =\gamma_{n}(\varphi)$| and |$E\left\{ \gamma_{n}^{N}(\varphi)\right\} =\gamma_{n}(\varphi)$|.
The proof is in the Supplementary Material. The lack-of-bias property |$E\{ \gamma_{n}^{N}(\varphi)\} =\gamma_{n}(\varphi)$| is well known and a martingale proof for the |$N_{p}=N$| case can be found in Del Moral (2004, Ch. 9).
Recalling that |$\gamma_{n}(\varphi)=E\{\varphi(X_{n})\prod_{p=0}^{n-1}G_{p}(X_{p})\}$| for |$\varphi\in\mathcal{L}(\mathcal{X})$|, we write |$\mu_{b}(\phi)=E_{b}\{ \phi(X_{n},X_{n}')\prod_{p=0}^{n-1}G_{p}(X_{p})G_{p}(X_{p}')\}$| for |$\phi\in\mathcal{L}(\mathcal{X}^{\otimes2})$| and |$b\in B_{n}$|, and can view |$\mu_{b}$| as defining a Feynman–Kac model on |$\mathcal{X}^{\otimes2}$|.
Observe that with |$0_{n}\in B_{n}$| denoting the zero string, |$\mu_{0_{n}}(\varphi^{\otimes2})=\gamma_{n}(\varphi)^{2}$|.
The proof of Lemma 2 uses an argument involving the law of a doubly conditional sequential Monte Carlo algorithm (see alsoAndrieu et al., 2018). The identity (7) was first proved by Cérou et al. (2011) in the case where |$N_{p}=N$|. Our proof technique is different: we obtain (7) as a consequence of (6). The appearance of |$K^{1}$| and |$K^{2}$| in (6) is also central to the justification of our variance estimators below.
3.3. Asymptotic variances
For each |$p\in\{0,\ldots,n\}$|, let |$e_{p}\in B_{n}$| denote the vector with a |$1$| in position |$p$| and zeros elsewhere. As in Remark 2, |$0_{n}$| denotes the zero string in |$B_{n}$|. The following result builds upon Lemmas 1 and 2. It shows that a particular subset of the measures |$\{\mu_{b}:b\in B_{n}\}$|, namely |$\mu_{0_{n}}$| and |$\{\mu_{e_{p}}:p=0,\ldots,n\}$|, appear in the asymptotic variances; its proof is in the Supplementary Material.
This particular decomposition of |$\sigma_{n}^{2}(\varphi)$| is also prominent in the limiting variance for the central limit theorem for |$\gamma_{n}^{N}(\varphi)$| in Del Moral (2004, Ch. 9).
4. Estimators
4.1. Particle approximations of each |$\mu_{b}$|
For any |$b\in B_{n}$| and |$\phi\in\mathcal{L}(\mathcal{X}^{\otimes2})$|:
(i)|$E\left\{ \mu_{b}^{N}(\phi)\right\} =\mu_{b}(\phi)$| for all |$N\geq1$|;
(ii)|$\sup_{N\geq1}NE\left[\left\{ \mu_{b}^{N}(\phi)-\mu_{b}(\phi)\right\} ^{2}\right]<\infty$| and hence |$\mu_{b}^{N}(\phi)\to\mu_{b}(\phi)$| in probability.
The proof of Theorem 2 is in the Supplementary Material. Although (11) can be computed in principle from the output of Algorithm 1 without the need for any further simulation, the conditional expectation in (11) involves a summation over all binary strings in |$\mathcal{I}(b)$|, so calculating |$\mu_{b}^{N}(\varphi^{\otimes2})$| in practice may be computationally expensive. Fortunately, relatively simple and computationally efficient expressions are available for |$\mu_{b}^{N}(\varphi^{\otimes2})$| in the cases |$b=0_{n}$| and |$b=e_{p}$|, and those are the only ones required to construct our variance estimators.
4.2. Variance estimators
Our next objective is to explain how (3) is related to the measures |$\mu_{b}^{N}$| and to introduce another family of estimators associated with the individual terms (10).
The following identity of events holds: |$\left\{ E_{n}^{K_{n}^{1}}\neq E_{n}^{K_{n}^{2}}\right\} =\left\{ (K^{1},K^{2})\in\mathcal{I}(0_{n})\right\}$|.
For any |$\varphi\in\mathcal{L}(\mathcal{X})$|:
(i)|$E\left\{ \gamma_{n}^{N}(1)^{2}v_{p,n}^{N}(\varphi)\right\} =\gamma_{n}(1)^{2}v_{p,n}(\varphi)$| for all |$N\geq1$|;
(ii)|$v_{p,n}^{N}(\varphi)\to v_{p,n}(\varphi)$| and |$v_{p,n}^{N}\{\varphi-\eta_{n}^{N}(\varphi)\}\to v_{p,n}\{\varphi-\eta_{n}(\varphi)\}$|, both in probability;
(iii)|$E\left\{ \gamma_{n}^{N}(1)^{2}v_{n}^{N}(\varphi)\right\} =\gamma_{n}(1)^{2}\sigma_{n}^{2}(\varphi)$| for all |$N\geq1$| and |$v_{n}^{N}(\varphi)\to\sigma_{n}^{2}(\varphi)$| in probability.
Pseudocode for computing each |$v_{p,n}^{N}(\varphi)$| and |$v_{n}^{N}(\varphi)$| with time and space complexity in |${O}(Nn)$| time upon running Algorithm 1 is provided in the Supplementary Material. The time complexity is the same as that of running Algorithm 1, but the space complexity is larger. Empirically, we have found that |$NV_{n}^{N}(\varphi)$| is very similar to |$v_{n}^{N}(\varphi)$| as an estimator of |$\sigma_{n}^{2}(\varphi)$| when |$N$| is large enough that they are both accurate, and hence may be preferable due to its reduced space complexity. On the other hand, the estimators |$v_{p,n}^{N}(\varphi)$| and |$v_{p,n}^{N}\{\varphi-\eta_{n}^{N}(\varphi)\}$| are the first of their kind to appear in the literature, and may be used to gain insight into the underlying Feynman–Kac model.
5. Use of the estimators to tune the particle filter
5.1. Asymptotically optimal allocation
The variance estimators can be used to report Monte Carlo errors alongside particle approximations, but may also be useful in algorithm design and tuning. Here and in § 5.2 we provide simple examples to illustrate this point. To simplify presentation, we focus on performance in estimating |$\gamma_{n}^{N}(\varphi)$|, but the ideas can easily be modified to deal instead with |$\eta_{n}^{N}(\varphi)$|.
The following well-known result is closely related to Neyman’s optimal allocation in stratified random sampling (Tschuprow, 1923; Neyman, 1934). A short proof using Jensen’s inequality can be found in Glasserman (2004, § 4.3).
Let |$a_{0},\ldots,a_{n}\geq0$|. The function |$(c_{0},\ldots,c_{n})\mapsto\sum_{p=0}^{n}c_{p}^{-1}a_{p}$| is minimized, subject to |$\min_{p}c_{p}>0$| and |$\sum_{p=0}^{n}c_{p}=n+1$|, at |$(n+1)^{-1}(\sum_{p=0}^{n}a_{p}^{1/2})^{2}$| when |$c_{p}\propto a_{p}^{1/2}$|.
As a consequence, we can in principle minimize |$\sigma_{n}^{2}(\varphi)$| by choosing |$c_{p}\propto v_{p,n}(\varphi)^{1/2}$|. An approximation of this optimal allocation can be obtained by the following two-stage procedure. First run a particle filter with |$N_{p}=N$| to obtain the estimates |$v_{p,n}^{N}(\varphi)$| and then define |$c_{0:n}$| by |$c_{p}=\max\{ v_{p,n}^{N}(\varphi),g(N)\} ^{1/2}$|, where |$g$| is some positive but decreasing function with |$\lim_{N\rightarrow\infty}g(N)=0$|.
Then run a second particle filter with each |$N_{p}=\left\lceil c_{p}N\right\rceil$|, and report the quantities of interest, e.g., |$\gamma_{n}^{N}(\varphi)$|. The function |$g$| is chosen to ensure that |$c_{p}>0$| and that for large |$N$| we permit small values of |$c_{p}$|. The quantity |$\sum_{p=0}^{n}v_{p,n}^{N}(\varphi)/\{\sum_{p=0}^{n}c_{p}^{-1}v_{p,n}^{N}(\varphi)\}$|, obtained from the first run, is an indication of the improvement in variance using the new allocation.
Approximately optimal allocation has previously been addressed by Bhadra & Ionides (2016), who introduced a meta-model to approximate the distribution of the Monte Carlo error associated with |$\log\gamma_{n}^{N}(1)$| in terms of an autoregressive process, the objective function to be minimized then being the variance under this meta-model. They provide only empirical evidence for the fit of their meta-model, whereas our approach targets the true asymptotic variance |$\sigma_{n}^{2}(\varphi)$| directly.
5.2. An adaptive particle filter
Monte Carlo errors of particle filter approximations can be sensitive to |$N$|, and an adequate value of |$N$| to achieve a given error may not be known a priori. The following procedure increases |$N$| until |$V_{n}^{N}(\varphi)$| is in a given interval. Given an initial number of particles |$N^{(0)}$| and a threshold |$\delta>0$|, one can run successive particle filters, doubling the number of particles each time, until the associated random variable |$V_{n}^{N^{(\tau)}}(\varphi)\in[0,\delta]$|. Finally, one runs a final particle filter with |$N^{(\tau)}$| particles, and returns the estimate of interest. In § 6 we provide empirical evidence that this procedure can be effective in some applications.
6. Applications and illustrations
6.1. Linear Gaussian hidden Markov model
This model is specified by |$M_{0}(\cdot)=\mathcal{N}(\cdot;0,1)$|, |$M_{p}(x_{p-1},\cdot)=\mathcal{N}(\cdot;0{\cdot}9x_{p-1},1)$| and |$G_{p}(x_{p})=\mathcal{N}(y_{p};x_{p},1)$|. The measures |$\eta_{n}$| and |$\gamma_{n}$| are available in closed form via the Kalman filter, and |$v_{p,n}(\varphi)$| can be computed exactly and very accurately for |$\varphi\equiv1$| and |$\varphi={\rm Id}$| respectively, allowing us to assess the accuracy of our estimators. We used a synthetic dataset, simulated according to the model with |$n=99$|. A Monte Carlo study with |$10^{4}$| replicates of |$V_{n}^{N}(\varphi)$| for each value of |$N$| and |$c_{p}\equiv1$| was used to measure the accuracy of the estimate |$NV_{n}^{N}(\varphi)$| as |$N$| grows; results are displayed in Fig. 2 and for this data |$\sigma_{n}^{2}(1)=294{\cdot}791$| and |$\sigma_{n}^{2}\{{\rm Id}-\eta_{n}({\rm Id})\}\approx1{\cdot}95$|. The Chan & Lai (2013) estimator of |$\sigma_{n}^{2}\{{\rm Id}-\eta_{n}({\rm Id})\}$| is fairly similar for |$N$| large enough that the variance estimator is approximately unbiased. The estimates |$v_{n}^{N}(\varphi)$| differed very little from |$NV_{n}^{N}(\varphi)$|, and so are not shown. We then tested the accuracy of the estimates |$v_{p,n}^{N}(1)$|; results are displayed in Fig. 3. The estimates |$v_{p,n}^{N}\{{\rm Id}-\eta_{n}^{N}({\rm Id})\}$| are very close to |$0$| for |$p<95$| with values |$(0{\cdot}009,0{\cdot}07,0{\cdot}39,1{\cdot}48)$| for |$p\in\{96,97,98,99\}$|; this behaviour is in keeping with time-uniform bounds on asymptotic variances (Whiteley, 2013, and references therein).
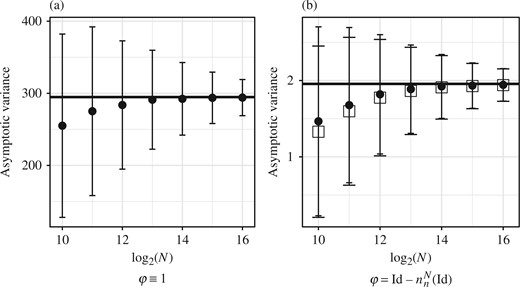
Estimated asymptotic variances |$NV_{n}^{N}(\varphi)$| (dots and error bars for the mean |$\pm$| one standard deviation from |$10^{4}$| replicates) against |$\log_{2}N$| for the linear Gaussian example. The horizontal lines correspond to the true asymptotic variances. The sample variances of |$\gamma_{n}^{N}(1)/\gamma_{n}(1)$| and |$\eta_{n}^{N}({\rm Id})$|, scaled by |$N$|, were close to their asymptotic variances. Corresponding results for the estimator of Chan & Lai (2013) are overlaid with boxes instead of dots and wider tick marks on the error bars.
Plot of |$v_{p,n}^{N}(1)$| (dots and error bars for the mean |$\pm$| one standard deviation from |$10^{3}$| replicates) and |$v_{p,n}(1)$| (crosses) at each |$p\in\{0,\ldots,n\}$| for the linear Gaussian example, with |$N=10^{5}$|.
We also compared a constant |$N$| particle filter, the asymptotically optimal particle filter where the asymptotically optimal allocation is computed exactly, and its approximation described in § 5.1 for different values of |$N$| using a Monte Carlo study with |$10^{4}$| replicates. We took |$g(N)=2/\log_{2}N$| in defining the approximation, and the results in Fig. 4(a) indicate that the approximation reduces the variance. The improvement is fairly modest for this particular model, and indeed the exact asymptotic variances associated with the constant |$N$| and asymptotically optimal particle filters differ by less than a factor of |$2$|. In contrast, Fig. 4(b) shows that the improvement can be fairly dramatic in the presence of outlying observations; the improvement in variance there is by a factor of close to |$40$|. Finally, we tested the adaptive particle filter described in § 5.2 using |$10^{4}$| replicates for each value of |$\delta$|; results are displayed in Fig. 5, and indicate that the variances are close to their prescribed thresholds.
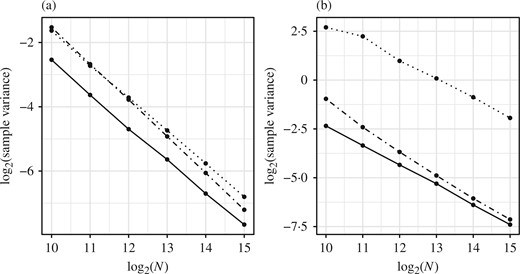
Logarithmic plots of sample variance for |$10^{4}$| replicates of |$\gamma_{n}^{N}(1)/\gamma_{n}(1)$| against |$N$| for the linear Gaussian example, using a constant |$N$| particle filter (dotted), the approximately asymptotically optimal particle filter (dot-dash), and the asymptotically optimal particle filter (solid). In panel (b), the observation sequence is |$y_{p}=0$| for |$p\in\{0,\ldots,99\}\setminus\{49\}$| and |$y_{49}=8$|.
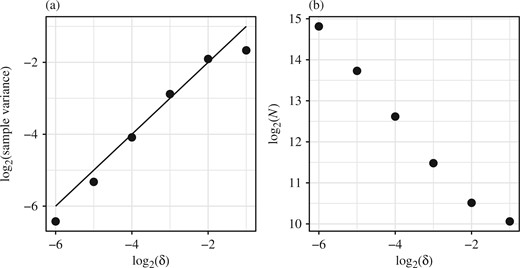
Logarithmic plots for the simple adaptive |$N$| particle filter estimates of |$\gamma_{n}(1)$| for the linear Gaussian example. Panel (a) plots the sample variance of |$\gamma_{n}^{N}(1)/\gamma_{n}(1)$| against |$\delta$|, along with the straight line |$y=x$|. Panel (b) plots |$N$| against |$\delta$|, where |$N$| is the average number of particles used by the final particle filter.
6.2. Stochastic volatility hidden Markov model
A stochastic volatility model is defined by |$M_{0}(\cdot)=\mathcal{N}\{ \,\cdot\,;0,\sigma^{2}/(1-\rho^{2})\}$|, |$M_{p}(x_{p-1},\cdot)=\mathcal{N}(\,\cdot\,;\rho x_{p-1},\sigma^{2})$| and |$G_{p}(x_{p})=\mathcal{N}\{y_{p};0,\beta^{2}\exp(x_{p})\}$|. We used the pound/dollar daily exchange rates for 100 consecutive weekdays ending on 28th June 1985, a subset of the well-known dataset analysed in Harvey et al. (1994). Our results are obtained by choosing the parameters |$(\rho,\sigma,\beta)=(0{\cdot}95,0{\cdot}25,0{\cdot}5)$|. We provide in the Supplementary Material plots of the accuracy of the estimate |$NV_{n}^{N}(\varphi)$| as |$N$| grows using |$10^{4}$| replicates for each value of |$N$|; the asymptotic variances |$\sigma_{n}^{2}(1)$| and |$\sigma_{n}^{2}\{{\rm Id}-\eta_{n}({\rm Id})\}$| are estimated as being approximately |$347$| and |$1{\cdot}24$| respectively. In the Supplementary Material we plot the estimates of |$v_{p,n}(\varphi)$|. We found modest improvement for the approximation of the asymptotically optimal particle filter, as one could infer from the estimated |$v_{p,n}(\varphi)$| and Lemma 5. For the simple adaptive |$N$| particle filter, results in the Supplementary Material indicate that the variances are close to their prescribed thresholds.
6.3. A sequential Monte Carlo sampler
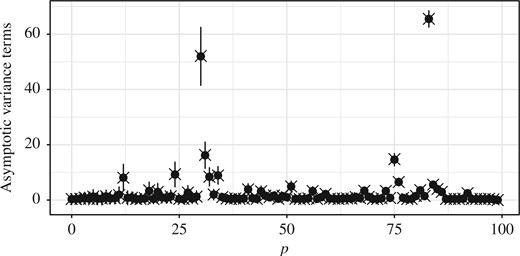
One striking difference between the estimates for this model and those for the hidden Markov models above is that the asymptotic variance |$\sigma_{n}^{2}\{{\rm Id}-\eta_{n}({\rm Id})\}\approx822$| is considerably larger than |$\sigma_{n}^{2}(1)\approx2{\cdot}1$|; the variability of the estimates |$NV_{n}^{N}(\varphi)$| is shown in the Supplementary Material. Inspection of the estimates of |$v_{p,n}(\varphi)$| in Fig. 6 allows us to investigate both this difference and the dependence of |$v_{p,n}(\varphi)$| on |$k$| in greater detail.
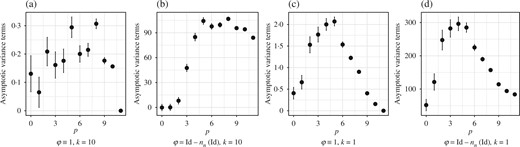
Plot of |$v_{p,n}^{N}(\varphi)$| (dots and error bars for the mean |$\pm$| one standard deviation) at each |$p\in\{0,\ldots,n\}$| with |$k=10$| iterations in (a) and (b) and with |$k=1$| iteration in (c) and (d) for each Markov kernel in the sequential Monte Carlo sampler example and |$N=10^{5}$|.
Figure 6(a) and (b) show that while |$v_{p,n}(1)$| is small for all |$p$|, the values of |$v_{p,n}\{{\rm Id}-\eta_{n}({\rm Id})\}$| are larger for large |$p$| than for small |$p$|; this could be due to the inability of the Metropolis kernels |$(M_{q})_{q\geq p}$| to mix well due to the separation of the modes in |$(\eta_{q})_{q\geq p}$| when |$p$| is large. In Fig. 6(c) and (d), |$k=1$|, i.e., each |$M_{p}$| consists of only a single iterate of a Metropolis kernel, and we see that the values of |$v_{p,n}(\varphi)$| associated with small |$p$| are much larger than when |$k=10$|, indicating that the larger number of iterates does improve the asymptotic variance of the particle approximations. However, the effect on |$v_{p,n}(\varphi)$| is less pronounced for large |$p$|. Results for the simple adaptive |$N$| particle filter approximating |$\eta_{n}({\rm Id})$| are provided in the Supplementary Material, which again show that the estimates are close to their prescribed thresholds.
7. Discussion
7.1. Alternatives to the bootstrap particle filter
In the hidden Markov model examples in § 6, we have constructed the Feynman–Kac measures taking |$M_{0},\ldots,M_{n}$| to be the initial distribution and transition probabilities of the latent process and defining |$G_{0},\ldots,G_{n}$| to incorporate the realized observations. This is only one, albeit important, way to construct particle approximations of |$\eta_{n}$|, and the algorithm itself is usually referred to as the bootstrap particle filter. Alternative specifications of |$(M_{p},G_{p})_{0\leq p\leq n}$| lead to different Feynman–Kac models, as discussed in Del Moral (2004, § 2.4.2), and the variance estimators introduced here are applicable to these models as well.
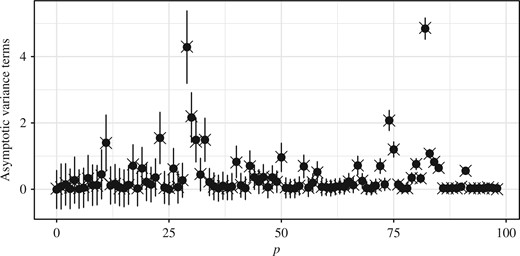
Plot of |$\check{v}_{p,n}^{N}(1)$| (dots and error bars for the mean |$\pm$| one standard deviation) and |$\check{v}_{p,n}(1)$| (crosses) at each |$p\in\{0,\ldots,n\}$| in the linear Gaussian example.
7.2. Estimators based on independent, identically distributed replicates
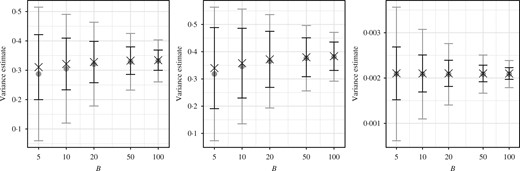
It is clearly possible to consistently estimate the variance of |$\gamma_{n}^{N}(\varphi)/\gamma_{n}(1)$| by using independent identically distributed replicates of |$\gamma_{n}^{N}$|. Such estimates necessarily entail simulation of multiple particle filters. We now compare the accuracy of such estimates with those based on independent, identically distributed replicates of |$V_{n}^{N}(\varphi)$|. For some |$\varphi\in\mathcal{L}(\mathcal{X})$| and |$B\in\mathbb{N}$|, let |$\gamma_{n,i}^{N}(\varphi)$| and |$V_{n,i}^{N}(\varphi)$| be independent and identically distributed replicates for |$i\in[B]$|, and define |$M=N^{-1}\sum_{i\in[B]}\gamma_{n,i}^{N}(1)$|. A standard estimate of |${\rm var}\{ \gamma_{n}^{N}(\varphi)/\gamma_{n}(1)\}$| is obtained by calculating the sample variance of |$\{M^{-1}\gamma_{n,i}^{N}(\varphi)\::\:i\in[B]\}$|. Noting the lack of bias of |$\gamma_{n}^{N}(1)^{2}V_{n}^{N}(\varphi)$|, an alternative estimate of |${\rm var}\{ \gamma_{n}^{N}(\varphi)/\gamma_{n}(1)\}$| can be obtained as |$B^{-1}\sum_{i\in[B]}\{ M^{-1}\gamma_{n,i}^{N}(1)\} ^{2}V_{n,i}^{N}(\varphi)$|. Both these estimates can be seen as ratios of simple Monte Carlo estimates of |${\rm var}\{ \gamma_{n}^{N}(\varphi)\}$| and |$\gamma_{n}(1)^{2}$|, and are therefore consistent as |$B\rightarrow\infty$|. We show in Fig. 8 a comparison between these estimates for the three models discussed in § 6 with |$N=10^{3}$| and |$\varphi\equiv1$|, and we can see that the alternative estimate based on |$V_{n}^{N}(1)$| is empirically more accurate for these examples.
7.3. Final remarks
In many applications, particularly in the context of hidden Markov models, particle filters are used to approximate conditional expectations with respect to updated Feynman–Kac measures. We define these, their approximations, and provide corresponding variance estimators in the Supplementary Material. Of some interest is the updated estimator |$\hat{\gamma}_{n-1}^{N}(1)=\gamma_{n}^{N}(1)$| whose variance estimator is |$\hat{V}_{n-1}^{N}(1)=V_{n-1}^{N}(G_{n-1})/\eta_{n-1}^{N}(G_{n-1})^{2}\neq V_{n}^{N}(1)$|. In fact, |$V_{n}^{N}(1)$| is an unbiased, noisy approximation of |$\hat{V}_{n-1}^{N}(1)$|, due to using |$E_{n}$| instead of |$G_{n-1}$| and |$\zeta_{n-1}$|. However, empirical investigations indicate that the difference in variance is practically negligible.
Acknowledgement
This paper was first submitted when Anthony Lee was at the University of Warwick. He was partially supported by the Alan Turing Institute.
Supplementary material
Supplementary material available at Biometrika online includes algorithms for efficient computation of the variance estimators, results for estimators associated with updated Feynman–Kac measures, additional figures and proofs.
Appendix
We shall now prove |$(K^{1},K^{2})\in\mathcal{I}(0_{n})\Rightarrow E_{n}^{K_{n}^{1}}\neq E_{n}^{K_{n}^{2}}$|. Recall from § 3.1 that when |$(K^{1},K^{2})\in\mathcal{I}(0_{n})$|, we have |$A_{p-1}^{K_{p}^{1}}=K_{p-1}^{1}\neq K_{p-1}^{2}=A_{p-1}^{K_{p}^{2}}$| for all |$p\in[n]$|, hence |$B_{0}^{K_{n}^{1}}=K_{0}^{1}\neq K_{0}^{2}=B_{0}^{K_{n}^{2}}$|. Applying (A3) with |$p=0$| and using the fact that in Algorithm 1, |$E_{0}^{i}=i$| for all |$i\in[N_{n}]$|, we have |$E_{n}^{i}=E_{0}^{B_{0}^{i}}=B_{0}^{i}$|, hence |$E_{n}^{K_{n}^{1}}=B_{0}^{K_{n}^{1}}\neq B_{0}^{K_{n}^{2}}=E_{n}^{K_{n}^{2}}$| as required. It remains to prove |$(K^{1},K^{2})\notin\mathcal{I}(0_{n})\Rightarrow E_{n}^{K_{n}^{1}}=E_{n}^{K_{n}^{2}}$|. Assuming |$(K^{1},K^{2})\notin\mathcal{I}(0_{n})$|, consider |$\tau=\mathrm{max}\{p:K_{p}^{1}=K_{p}^{2}\}$|. If |$\tau=n$| then clearly |$E_{n}^{K_{n}^{1}}=E_{n}^{K_{n}^{2}}$|, so suppose |$\tau<n$|. It follows from § 3.1 that |$B_{\tau}^{K_{n}^{1}}=K_{\tau}^{1}=K_{\tau}^{2}=B_{\tau}^{K_{n}^{2}}$|, so taking |$p=\tau$| and |$i=K_{n}^{1},K_{n}^{2}$| in (A3) gives |$E_{n}^{K_{n}^{1}}=E_{n}^{K_{n}^{2}}$|. □
For the remainder of the proof, |$\to$| denotes convergence in probability. For part (ii), |$\mu_{e_{p}}^{N}(\varphi^{\otimes2})-\mu_{0_{n}}^{N}(\varphi^{\otimes2})\to\gamma_{n}(1)^{2}v_{p,n}(\varphi)$| by Theorem 2, and |$\gamma_{n}^{N}(1)^{2}\to\gamma_{n}(1)^{2}$| by Proposition 1, so |$v_{p,n}^{N}(\varphi)=\{\mu_{e_{p}}^{N}(\varphi^{\otimes2})-\mu_{0_{n}}^{N}(\varphi^{\otimes2})\}/\gamma_{n}^{N}(1)^{2}\to v_{p,n}(\varphi)$|; as in the proof of Theorem 1, |$\mu_{b}^{N}[\{\varphi-\eta_{n}^{N}(\varphi)\}^{\otimes2}]\to\mu_{b}[\{\varphi-\eta_{n}(\varphi)\}^{\otimes2}]$| gives |$v_{p,n}^{N}\{\varphi-\eta_{n}^{N}(\varphi)\}\to v_{p,n}\{\varphi-\eta_{n}(\varphi)\}$|. Part (iii) follows from (i) and (ii). □

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}