




Summary
The availability of datasets with large numbers of variables is rapidly increasing. The effective application of Bayesian variable selection methods for regression with these datasets has proved difficult since available Markov chain Monte Carlo methods do not perform well in typical problem sizes of interest. We propose new adaptive Markov chain Monte Carlo algorithms to address this shortcoming. The adaptive design of these algorithms exploits the observation that in large-|$p$|, small-|$n$| settings, the majority of the |$p$| variables will be approximately uncorrelated a posteriori. The algorithms adaptively build suitable nonlocal proposals that result in moves with squared jumping distance significantly larger than standard methods. Their performance is studied empirically in high-dimensional problems and speed-ups of up to four orders of magnitude are observed.
1. Introduction
The availability of large datasets has led to an increasing interest in variable selection methods applied to regression models with many potential variables, but few observations, so-called large-|$p$|, small-|$n$| problems. Frequentist approaches have mainly concentrated on point estimates under assumptions of sparsity using penalized maximum likelihood procedures (Hastie et al., 2015). Bayesian approaches to variable selection are an attractive and natural alternative, and lead to a posterior distribution on all possible models which can address model uncertainty for variable selection and prediction. A growing literature provides a theoretical basis for good posterior properties in large-|$p$| problems (see, e.g., Johnson & Rossell, 2012; Castillo et al., 2015).
The posterior probabilities of all possible models can usually only be calculated or approximated if |$p$| is smaller than 30. If |$p$| is larger, Markov chain Monte Carlo methods are typically used to sample from the posterior distribution (George & McCulloch, 1997; O’Hara & Sillanpää, 2009; Clyde et al., 2011). García-Donato & Martínez-Beneito (2013) discuss the benefits of such methods. The most widely used Markov chain Monte Carlo algorithm in this context is the Metropolis–Hastings sampler, where new models are proposed using add-delete-swap samplers (Brown et al., 1998; Chipman et al., 2001). For example, this approach is used by Nikooienejad et al. (2016) in a binary regression model with a nonlocal prior for the regression coefficients on a dataset with 7129 genes. Some supporting theoretical understanding of convergence is available for the add-delete-swap samplers, e.g., conditions for rapid mixing in linear regression models have been derived by Yang et al. (2016). Others have considered more targeted moves in model space. For example, Titsias & Yau (2017) introduce the Hamming ball sampler which more carefully selects the proposed model in a Metropolis–Hastings sampler, in a similar way to shotgun variable selection (Hans et al., 2007), and Schäfer & Chopin (2013) develop a sequential Monte Carlo method that uses a sequence of annealed posteriors. Several authors use more general shrinkage priors and develop suitable Markov chain Monte Carlo algorithms for high-dimensional problems (see, e.g., Bhattacharya et al., 2016). Nonlocal priors (Johnson & Rossell, 2012) are adopted in Shin et al. (2018), who use screening for high dimensions. Zanella & Roberts (2019) combine Markov chain Monte Carlo and importance sampling ideas in their tempered Gibbs sampler.
The challenge of performing Markov chain Monte Carlo for Bayesian variable selection in high dimensions has led to several developments sacrificing exact posterior exploration. For example, Liang et al. (2013) use the stochastic approximation Monte Carlo algorithm (Liang et al., 2007) to efficiently explore model space. In another direction, variable selection can be performed as a post-processing step after fitting a model including all variables (see, e.g., Bondell & Reich, 2012; Hahn & Carvalho, 2015). Several authors develop algorithms that focus on high posterior probability models. In particular, Rockova & George (2014) propose a deterministic expectation-maximization-based algorithm for identifying posterior modes, while Papaspiliopoulos & Rossell (2017) develop an exact deterministic algorithm to find the most probable model of any given size in block-diagonal design models.
Alternatively, Markov chain Monte Carlo methods for variable selection can be tailored to the data to allow faster convergence and mixing using adaptive ideas (see, e.g., Green et al., 2015, § 2.4, and references therein). Several strategies have been developed in the literature for both the Metropolis-type algorithms (Ji & Schmidler, 2013; Lamnisos et al., 2013) and Gibbs samplers (Nott & Kohn, 2005; Richardson et al., 2010). Our proposal is a Metropolis–Hastings kernel that learns the relative importance of the variables, unlike previous work (see, e.g., Ji & Schmidler, 2013; Lamnisos et al., 2013). A similar strategy is used by Zanella & Roberts (2019) in a Gibbs sampling framework. This leads to substantially more efficient algorithms than commonly used methods in high-dimensional settings, and for which the computational cost of one step scales linearly with |$p$|. The algorithms adaptively build suitable nonlocal Metropolis–Hastings-type proposals that result in moves with expected squared jumping distance (Gelman et al., 1996) significantly larger than standard methods. In idealized examples the limiting versions of our adaptive algorithms converge in |$\mathcal{O}(1)$| and result in super-efficient sampling. They outperform independent sampling in terms of the expected squared jump distance and also in the sense of the central limit theorem asymptotic variance. This is in contrast to the behaviour of optimal local random walk Metropolis algorithms that on analogous idealized targets need at least |$\mathcal{O}(p)$| samples to converge (Roberts et al., 1997). The performance of our algorithms is studied empirically in realistic high-dimensional problems for both synthetic and real data. In particular, in § 4.1, for a well-studied synthetic data example, speed-ups of up to four orders of magnitude are observed compared to standard algorithms. Moreover, in § 4.2, we show the efficiency of the method in the presence of multicollinearity on a real-data example with |$p=100$| variables, and in § 4.3, we present real-data gene expression examples with |$p=22\, 576$| and with |$p=79\, 748$|, and reliably estimate the posterior inclusion probabilities for all variables. The Supplementary Material has results from three datasets with moderate |$p$| and high correlations used in Schäfer & Chopin (2013), indicating that our algorithms outperform most other methods in the literature. The algorithms have the potential to be parallelized across the multiple chains and to be applied to non-Gaussian models or more general prior structures.
2. Design of the adaptive samplers
2.1. The setting
2.2. In search of lost mixing time: optimizing the sampler
If |$s$| is close to |$1/2$|, the optimal |$\mathcal{O}(p)$| mixing rate occurs as |$p$| tends to infinity if the mean acceptance rate is |$0.234$|. If |$s\rightarrow 0$| as |$p\rightarrow \infty$|, the numerical results of Roberts (1998, § 3) indicate that the optimally tuned random walk Metropolis proposes to change two |$\gamma_j$|s at a time, but that the acceptance rate deteriorates to zero resulting in the chain not moving. This suggests that the actual mixing in this regime is slower than the |$\mathcal{O}(p)$| observed for smooth continuous densities.
We consider two proposals which satisfy (4): the independent proposal for which |$A_j=1-D_j=\pi_j $|, and the informed proposal for which |$A_j = \min\big(1, \frac{\pi_j}{1-\pi_j}\big)$| and |$D_j = \min\big(1, \frac{1- \pi_j}{\pi_j}\big)$|. The following proposition shows that the informed proposal has more desirable properties.
Consider the class of Metropolis–Hastings algorithms with target distribution given by (3), and proposal |$q_{\eta}(\gamma, \gamma')$| given by (2) with the independent or informed proposal. Let |${\rm var}_{\pi}f $| be the stationary variance of |$f$| under |$\pi_p(\gamma)$| and |$\pi^{(j)} := \{1-\pi_j, \pi_j\}$|. Then:
(i) The independent proposal leads to
(a) independent sampling and optimal mixing time |$\rho = 1$|;
(b) the expected squared jumping distance |$E_{\pi}(\Delta^2) = 2\sum_{j=1}^p \pi_j(1-\pi_j)$|;
(c) the asymptotic variances |$\sigma_{P,\ f}^2 = {\rm var}_{\pi}f$| for arbitrary |$f$| and |$\sigma_{P,\ f}^2 = {\rm var}_{\pi}f = \sum_{j=1}^p a_j^2 {\rm var}_{\pi^{(j)}}f_j$| for |$f \in \mathbb{L}(\Gamma)$|.
(ii) The informed proposal leads to
(a) the expected squared jumping distance |$E_{\pi}(\Delta^2) = 2\sum_{j=1}^p\min(1-\pi_j, \pi_j)$|, which is maximal;
(b) the asymptotic variance |$\sigma_{P,\ f}^2 = \sum_{j=1}^p \left\{2 \max (1-\pi_j, \pi_j) -1 \right\}a_j^2 {\rm Var}_{\pi^{(j)}}f_j$| for |$f \in \mathbb{L}(\Gamma)$|, which is optimal with respect to the Peskun ordering for the class of linear functions |$\mathbb{L}(\Gamma)$| defined in (5).
The differences of the expected squared jumping distance and asymptotic variance for the two proposals is largest when |$\pi_j$| is close to |$1/2$|.
Zanella (2020) discusses a framework for designing informed proposals in discrete spaces, and discusses optimal choices under Peskun ordering.
These results suggest that the informed proposal should be preferred to the independent proposal when designing a Metropolis–Hastings sampler for idealized posteriors of the form in (3). In practice, the posterior distribution will not have a product form, but can anything be said about its form when |$p$| is large? The following result sheds some light on this issue. We define |${\rm BF}_j(\gamma_{-j})$| to be the Bayes factor of including the |$j$|th variable given the values of |$\gamma_{-j}=(\gamma_1,\dots,\gamma_{j-1},\gamma_{j+1},\dots,\gamma_p)$| and denote by |$\gamma_0$| the vector |$\gamma$| without |$\gamma_j$| and |$\gamma_k$|.
Let |$a=\frac{{\rm BF}_j(\gamma_k=1,\gamma_0)} {{\rm BF}_j(\gamma_k=0,\gamma_0)}$|. If (i) |$a \rightarrow 1$| or (ii) |$a\rightarrow A<\infty$| and |${\rm BF}_j(\gamma_k=0,\gamma_{0}) h\rightarrow 0$| then |$ p(\gamma_j=1\mid \gamma_k=1,\gamma_0) \rightarrow p(\gamma_j=1\mid \gamma_k=0,\gamma_0)$|.
The family of these proposals for |$\zeta_j \in [0,1]$| form a line segment for |$(A_j, D_j)$| between |$(0, 0)$| and |$\big\{\min\big(1, \frac{\pi_j}{1-\pi_j}\big), \min\big(1, \frac{1- \pi_j}{\pi_j}\big)\big\}$|, which is illustrated in Fig. 1. The independent proposal corresponds to the point on this line where |$\zeta_j=\max(\pi_j, 1-\pi_j)$|.
![The solid black line shows pairs $(A_j, D_j)$ corresponding to $\pi=1/3$ and $\zeta_j \in [0,1]$ in (6). The independent proposal (i), marked with a triangle, is a shrunk version of the informed proposal (ii), marked with a bullet.](https://oup.silverchair-cdn.com/oup/backfile/Content_public/Journal/biomet/108/1/10.1093_biomet_asaa055/1/m_asaa055f1.jpeg?Expires=1716467792&Signature=onVDO~JKoR4oMNbQ1yF18CvlqHuSzsE6qY~WPUqaIX7Ll8mAlDo~8lf809Fh2EHhtRazKoaGsp13dN4IGMFrPBFWuAIBHFHH34aHJ32bbZV9p6~Ue7YpcWxaxNkdEUGFU3XxOSp4E8H5OhQtvkwmVqe5Lb29psHvmQcd--HWalktrDi6Uy70MyGauRhcMbSiRmQTwRJ--fUzt1c1-ppN6wpeXqLM~Kajsr69oS9pS4sDvtGDU~1kSKzICwfA~fy4FPbUk4-ubHGqbBzIe91VCpYqZ8casrC0~ZwYUR~suEuxIZhAp~cWilvYdlg188o0~KCdLpNe2EX6TOh~kmN5VA__&Key-Pair-Id=APKAIE5G5CRDK6RD3PGA)
The solid black line shows pairs |$(A_j, D_j)$| corresponding to |$\pi=1/3$| and |$\zeta_j \in [0,1]$| in (6). The independent proposal (i), marked with a triangle, is a shrunk version of the informed proposal (ii), marked with a bullet.
In the next section we devise adaptive Markov chain Monte Carlo algorithms to tune proposals of the form (2) so that the |$A_j$| and |$D_j$| lie approximately on this line. Larger values of |$\zeta_j$| tend to lead to larger jumps, whereas smaller values of |$\zeta_j$| tend to increase acceptance. These algorithms aim to find a point which balances this trade-off. We define two strategies for adapting |$\eta$|: exploratory individual adaptation and adaptively scaled individual adaptation.
With both forms of adaptation, we run independent parallel chains which share the same proposal parameters and refer to this as multiple-chain acceleration. Craiu et al. (2009) show empirically that running multiple independent Markov chains with the same adaptive parameters improves the rate of convergence of adaptive algorithms towards their target acceptance rate in the context of the classical adaptive Metropolis algorithm of Haario et al. (2001); see also Bornn et al. (2013).
2.3. Remembrance of things past: exploratory individual adaptation
The first adaptive strategy is a general purpose method that we term exploratory individual adaptation. It aims to find pairs |$(A_j, D_j)$| on the line segment defined by (4) which lead to good mixing. Proposals with larger values of |$A_j$| and |$D_j$| will tend to propose more changes to the included variables, but will also tend to reduce the average acceptance probability or mutation rate. The method introduces two tuning parameters, |$\tau_{\rm L}$| and |$\tau_{\rm U}$|. There are three types of updates for |$A^{(i)}$| and |$D^{(i)}$| which move towards the correct ratio |$A_j/D_j$| and then along the segment, where the slope of the segment depends on |$\pi_j$|. Unless otherwise stated, |$A^{(i+1)}_j=A^{(i)}_j$| and |$D^{(i+1)}_j=D^{(i)}_j$|.
Both the expansion step and the shrinkage step change |$A^{(i+1)}_j$|, and |$D^{(i+1)}_j$| for |$j$| in |$\gamma^{A(i)}$| and |$\gamma^{D(i)}$| to adjust the average squared jumping distance whilst maintaining that |$A^{(i+1)}_j / D^{(i+1)}_j \approx A^{(i)}_j / D^{(i)}_j$|. The expansion step is used if a promising move is proposed, when |$a_i>\tau_{\rm U}$|, and sets |$A^{(i+1)}_j$| and |$D^{(i+1)}_j$| larger than |$A^{(i)}_j$| and |$D^{(i)}_j$|, respectively. Similarly, the shrinkage step is used if an unpromising move has been proposed, when |$a_i<\tau_{\rm L}$|, and |$A^{(i+1)}_j$| and |$D^{(i+1)}_j$| are set smaller than |$A^{(i)}_j$| and |$D^{(i)}_j$|.
The correction step aims to increase the average acceptance rate by correcting the ratio between |$A$| and |$D$|. If |$\tau_{\rm L}<a_i<\tau_{\rm U}$|, we set |$A^{(i+1)}_j>A^{(i)}_j$| and |$D^{(i+1)}_j<D^{(i}_j$| if |$\gamma^{D(i)}_j=1$|, and |$A^{(i+1)}_j<A^{(i)}_j$| and |$D^{(i+1)}_j>D^{(i)}_j$| if |$\gamma^{A(i)}_j=1$|.
2.4. Remembrance of things past: adaptively scaled individual adaptation
3. Ergodicity of the algorithms
Since adaptive Markov chain Monte Carlo algorithms violate the Markov condition, the standard and well-developed Markov chain theory cannot be used to establish ergodicity and we need to derive appropriate results for our algorithms. We verify the validity of our algorithms by establishing the conditions introduced in Roberts & Rosenthal (2007), namely simultaneous uniform ergodicity and diminishing adaptation.
In the case of multiple-chain acceleration, where |$L$| copies of the chain are run, the model state space becomes the product space and the current state of the algorithm at time |$i$| is |$\gamma^{\otimes L,\, (i)} = (\gamma^{1,\, (i)},\dots, \gamma^{L,\, (i)}) \in \Gamma^L$|. The single-chain version corresponds to |$L=1$| and all results apply.
To this end we establish the following lemmas.
Simultaneous uniform ergodicity together with diminishing adaptation leads to the following theorem.
Consider the target |$\pi_p(\gamma)$| of (12), the constants |$1/2 \leqslant \lambda \leqslant 1$| and |$\epsilon > 0$| defining respectively the adaptation rate |$\phi_i=O(i^{-\lambda})$| and region in (7), (8) or (11), and the parameter |$\kappa >0$| in Algorithm 2. Then, ergodicity (15) and the strong law of large numbers (16) hold for each of the algorithms, exploratory individual adaptation and adaptively scaled individual adaptation, and their multiple-chain acceleration versions.
Lemma 2 and Theorem 1 remain true with any |$\lambda > 0$|; however, |$\lambda >1$| results in finite adaptation (see, e.g., Roberts & Rosenthal, 2007), and |$\lambda < 1/2$| is rarely used in practice for finite-sample stability concerns.
4. Results
4.1. Simulated data
The |$i$|th vector of regressors is generated as |$x_i\sim{{N}}(0,\Sigma)$|, where |$\Sigma_{jk}=\rho^{\vert j - k\vert}$|. In our examples we use the value |$\rho=0.6$|, which represents a relatively large correlation between the regressors.
We are interested in the performance of the two adaptive algorithms relative to an add-delete-swap algorithm. The adaptive algorithms do not lead to Markov chains, and so the traditional estimator of the effective sample size based on autocorrelation is not applicable. We define the ratio of the relative time-standardized effective sample size of algorithm |$A$| versus algorithm |$B$| to be |$ r_{A,\ B} = ({{\rm ESS}_A/t_A})/({{\rm ESS}_B/t_B}) , $| where |${\rm ESS}_A$| is the effective sample size for algorithm |$A$|. This is estimated by making 200 runs of each algorithm and calculating |$ \hat{r}_{A,\ B} =({s^2_Bt_B})/({s^2_At_A}), $| where |$t_A$| and |$t_B$| are the median runtimes, and |$s^2_A$| and |$s^2_B$| are the sample variances of the posterior inclusion probabilities for algorithms |$A$| and |$B$|.
We use the prior in (1) with |$V_\gamma=9 I$| and |$h=10/p$|, implying a prior mean model size of 10. The posterior distribution changes substantially with the SNR and the size of the dataset. All 10 true nonzero coefficients are given posterior inclusion probabilities greater than 0.9 in the two high-SNR scenarios, SNR = 2 and SNR = 3, for each value of |$n$| and |$p$|, and no true nonzero coefficients are given posterior inclusion probabilities greater than 0.2 in the low-SNR scenario, SNR = 0.5, for each value of |$n$| and |$p$|. In the intermediate SNR scenario, SNR = 1, the numbers of true nonzero coefficients given posterior inclusion probabilities greater than 0.9 are four and eight for |$p=500$|, and three and zero for |$p=5000$|. Generally, the results are consistent with our intuition that true nonzero regression coefficients should be detected with greater posterior probability for larger SNR, larger values of |$n$| and smaller values of |$p$|.
Table 1 shows the median relative time-standardized effective sample sizes for the exploratory individual adaptation and adaptively scaled individual adaptation algorithms with 5 or 25 multiple chains for different combinations of |$n$|, |$p$| and SNR. The median is taken across the estimated relative time-standardized effective sample sizes for all posterior inclusion probabilities.
Simulated data: median values of |$\hat{r}_{A,\ B}$| for the posterior inclusion probabilities over all variables where |$B$| is the add-delete-swap Metropolis–Hastings algorithm and |$A$| is the exploratory or adaptively scaled individual adaptation algorithm
| 5 chains | 25 chains | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| SNR | SNR | ||||||||
| |$(n,p)$| | 0.5 | 1 | 2 | 3 | 0.5 | 1 | 2 | 3 | |
| (500, 500) | EIA | 4.9 | 1.8 | 5.5 | 5.1 | 1.2 | 1.5 | 2.4 | 2.3 |
| ASI | 1.7 | 21.3 | 31.8 | 7.5 | 2.0 | 36.0 | 42.7 | 12.6 | |
| (500, 5000) | EIA | 8.7 | 2.2 | 718.0 | 81.5 | 7.1 | 2.9 | 2267.2 | 147.2 |
| ASI | 29.9 | 126.9 | 2053.1 | 2271.3 | 53.5 | 353.3 | 12319.5 | 7612.3 | |
| (1000, 500) | EIA | 5.9 | 16.3 | 7.7 | 4.2 | 1.6 | 80.7 | 4.4 | 1.8 |
| ASI | 41.9 | 2.1 | 16.9 | 12.0 | 32.8 | 34.0 | 27.9 | 14.4 | |
| (1000, 5000) | EIA | 2.2 | 2.2 | 9167.2 | 11.3 | 5.6 | 2.5 | 15960.7 | 199.8 |
| ASI | 15.4 | 37.0 | 4423.1 | 30.8 | 54.9 | 53.4 | 11558.2 | 736.4 | |
| 5 chains | 25 chains | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| SNR | SNR | ||||||||
| |$(n,p)$| | 0.5 | 1 | 2 | 3 | 0.5 | 1 | 2 | 3 | |
| (500, 500) | EIA | 4.9 | 1.8 | 5.5 | 5.1 | 1.2 | 1.5 | 2.4 | 2.3 |
| ASI | 1.7 | 21.3 | 31.8 | 7.5 | 2.0 | 36.0 | 42.7 | 12.6 | |
| (500, 5000) | EIA | 8.7 | 2.2 | 718.0 | 81.5 | 7.1 | 2.9 | 2267.2 | 147.2 |
| ASI | 29.9 | 126.9 | 2053.1 | 2271.3 | 53.5 | 353.3 | 12319.5 | 7612.3 | |
| (1000, 500) | EIA | 5.9 | 16.3 | 7.7 | 4.2 | 1.6 | 80.7 | 4.4 | 1.8 |
| ASI | 41.9 | 2.1 | 16.9 | 12.0 | 32.8 | 34.0 | 27.9 | 14.4 | |
| (1000, 5000) | EIA | 2.2 | 2.2 | 9167.2 | 11.3 | 5.6 | 2.5 | 15960.7 | 199.8 |
| ASI | 15.4 | 37.0 | 4423.1 | 30.8 | 54.9 | 53.4 | 11558.2 | 736.4 | |
SNR, signal-to-noice ratio; EIA, exploratory individual adaptation algorithm; ASI, adaptively scaled individual adaptation algorithm.
Simulated data: median values of |$\hat{r}_{A,\ B}$| for the posterior inclusion probabilities over all variables where |$B$| is the add-delete-swap Metropolis–Hastings algorithm and |$A$| is the exploratory or adaptively scaled individual adaptation algorithm
| 5 chains | 25 chains | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| SNR | SNR | ||||||||
| |$(n,p)$| | 0.5 | 1 | 2 | 3 | 0.5 | 1 | 2 | 3 | |
| (500, 500) | EIA | 4.9 | 1.8 | 5.5 | 5.1 | 1.2 | 1.5 | 2.4 | 2.3 |
| ASI | 1.7 | 21.3 | 31.8 | 7.5 | 2.0 | 36.0 | 42.7 | 12.6 | |
| (500, 5000) | EIA | 8.7 | 2.2 | 718.0 | 81.5 | 7.1 | 2.9 | 2267.2 | 147.2 |
| ASI | 29.9 | 126.9 | 2053.1 | 2271.3 | 53.5 | 353.3 | 12319.5 | 7612.3 | |
| (1000, 500) | EIA | 5.9 | 16.3 | 7.7 | 4.2 | 1.6 | 80.7 | 4.4 | 1.8 |
| ASI | 41.9 | 2.1 | 16.9 | 12.0 | 32.8 | 34.0 | 27.9 | 14.4 | |
| (1000, 5000) | EIA | 2.2 | 2.2 | 9167.2 | 11.3 | 5.6 | 2.5 | 15960.7 | 199.8 |
| ASI | 15.4 | 37.0 | 4423.1 | 30.8 | 54.9 | 53.4 | 11558.2 | 736.4 | |
| 5 chains | 25 chains | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| SNR | SNR | ||||||||
| |$(n,p)$| | 0.5 | 1 | 2 | 3 | 0.5 | 1 | 2 | 3 | |
| (500, 500) | EIA | 4.9 | 1.8 | 5.5 | 5.1 | 1.2 | 1.5 | 2.4 | 2.3 |
| ASI | 1.7 | 21.3 | 31.8 | 7.5 | 2.0 | 36.0 | 42.7 | 12.6 | |
| (500, 5000) | EIA | 8.7 | 2.2 | 718.0 | 81.5 | 7.1 | 2.9 | 2267.2 | 147.2 |
| ASI | 29.9 | 126.9 | 2053.1 | 2271.3 | 53.5 | 353.3 | 12319.5 | 7612.3 | |
| (1000, 500) | EIA | 5.9 | 16.3 | 7.7 | 4.2 | 1.6 | 80.7 | 4.4 | 1.8 |
| ASI | 41.9 | 2.1 | 16.9 | 12.0 | 32.8 | 34.0 | 27.9 | 14.4 | |
| (1000, 5000) | EIA | 2.2 | 2.2 | 9167.2 | 11.3 | 5.6 | 2.5 | 15960.7 | 199.8 |
| ASI | 15.4 | 37.0 | 4423.1 | 30.8 | 54.9 | 53.4 | 11558.2 | 736.4 | |
SNR, signal-to-noice ratio; EIA, exploratory individual adaptation algorithm; ASI, adaptively scaled individual adaptation algorithm.
The results show a wide variation in the relative performance of the adaptive algorithms and the add-delete-swap algorithm. As is common in work on Bayesian variable selection, see, e.g., Zanella & Roberts (2019), each result uses a single dataset and so the results have to be interpreted in a holistic way. Clearly, the adaptively scaled individual adaptation algorithm outperforms the exploratory individual adaptation algorithm for most settings with either 5 or 25 multiple chains. The performance of the exploratory individual adaptation and, especially, the adaptive scaled individual adaptation algorithm with 25 chains, is better than the corresponding performance with 5 chains for most cases. Concentrating on the results with the adaptively scaled individual adaptation algorithm, the largest increase in performance compared to the Metropolis–Hastings algorithm occurs with SNR = 2. In this case, there is three or four orders of magnitude improvement when |$p=5000$|, and several orders of magnitude improvement for other SNRs with |$p=5000$|. In smaller problems with |$p=500$| there are still substantial improvements in efficiency over the add-delete-swap Metropolis–Hastings sampler.
The superior performance of the adaptively scaled individual adaptation algorithm over the exploratory individual adaptation algorithm is due to the substantially faster convergence of the tuning parameters of the former algorithm to optimal values. Plotting posterior inclusion probabilities against |$A$| and |$D$| at the end of a run shows that, in most cases, the values of |$A_j$| are close to the corresponding posterior inclusion probabilities for both algorithms. However, the values of |$D_j$| are mostly close to 1 for adaptively scaled individual adaptation, but not for exploratory individual adaptation. If |$D_j$| is close to 1, then variable |$j$| is highly likely to be proposed to be removed if included in the model. This is consistent with the idealized super-efficient setting (ii) in Proposition 1 for |$\pi_j<0.5$|, and leads to improved mixing rates for small |$\pi_j$|, since it allows for the variable to be included more often in a fixed run length. This can be hard to learn through exploratory individual adaptation since variables with low posterior inclusion probabilities will rarely be included and so the algorithm learns |$D_j$| slowly for those variables.
4.2. Behaviour of the exploratory individual adaptation algorithm on the Tecator data
The Tecator data contains 172 observations and 100 variables. They have previously been analysed using Bayesian linear regression techniques by Griffin & Brown (2010), who give a description of the data, and Lamnisos et al. (2013). The regressors show a high degree of multicollinearity, so this is a challenging example for Bayesian variable selection algorithms. The prior used was (1) with |$V_\gamma=100 I$| and |$h=5/100$|. Even short runs of the exploratory individual adaptation algorithm for this data, such as 5 multiple chains with 3000 burn in and 3000 recorded iterations, taking about 5 seconds on a laptop, show consistent convergence across runs.
Our purpose was to study the adaptive behaviour of the exploratory individual adaptation algorithm on this real data example, in particular to compare the idealized values of the |$A_j$| and |$D_j$| with the values attained by the algorithm.
We use multiple chain acceleration with 50 multiple chains over the total of 6000 iterations. The algorithm parameters were set to |$\tau_{\rm L} = 0.01$| and |$\tau_{\rm U}= 0.1$|. The resulting mean acceptance rate was approximately |$0.2$|, indicating close to optimal efficiency. The average number of variables proposed to be changed in a single accepted proposal was |$23$|, approximately twice the average model size, meaning that in a typical move all of the current variables were deleted from the model, and a set of completely fresh variables was proposed.
Figure 2(a) shows how the exploratory individual adaptation algorithm approximates setting (ii) of Proposition 1, namely the super-efficient sampling from the idealized posterior (3). Figure 2(b) illustrates how the attained values of |$A_j$| somewhat overestimate the idealized values |$\min\{1, {\pi_j/(1-\pi_j)}\}$| of setting (ii) in Proposition 1. This indicates that the chosen parameter values |$\tau_{\rm L}=0.01$| and |$\tau_{\rm U}=0.1$| of the algorithm overcompensates for dependence in the posterior, which is not very pronounced for this dataset. To quantify the performance, we ran both algorithms with adaptation in the burn-in only and calculated the effective sample size. With a burn-in of 10 000 iterations and 30 000 draws, the effective sample per multiple chain was 4015 with exploratory individual adaptation and 6673 with adaptively scaled individual adaptation. This is an impressive performance for both algorithms given the multicollinearity in the regressors. The difference in performance can be explained by the speed of convergence to optimal values for the proposal. To illustrate this, we reran the algorithms with the burn-in extended to 30 000 iterations: the effective sample per multiple chain was now 4503 with exploratory individual adaptation, but 6533 with adaptively scaled individual adaptation, indicating that the first algorithm had caught up somewhat. As a comparison, the effective sample size was 1555 for add-delete-swap and 15 039 for the Hamming ball sampler with a burn-in of 10 000 iterations. However, the Hamming ball sampler required 34 times the run time of the exploratory individual adaptation sampler, rendering the latter nine times more efficient in terms of time-standardized effective sample size.
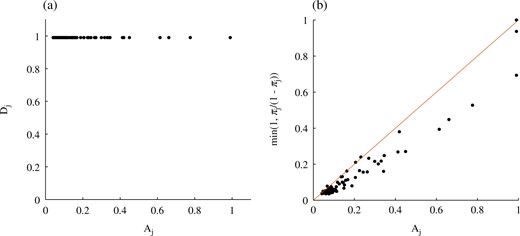
Tecator data: the adaptive parameter |$\eta = (A,D)$| for the exploratory individual adaptation algorithm. (a) Limiting values of the (|$A_j$|, |$D_j$|) pairs align at the top ends of the segments of Fig. 1, with the |$D_j$| close to 1, corresponding to the superefficient setting (ii) of Proposition 1; (b) The attained values of the |$A_{j}$| overestimate the idealized values |${\rm min}\left\{1,{\pi_{j}}/{1-\pi_{j}}\right\}$| of setting (ii) in Proposition 1, indicating low dependence in the posterior.
This example and the previous one show that the simplified posterior (3) is a good fit with many datasets and can indeed be used to guide and design algorithms.
4.3. Performance on problems with very large |$p$|
Bondell & Reich (2012) described a variable selection problem with 22 576 variables and 60 observations on two inbred mouse populations. The covariates are gender and gene expression measurements for 22 575 genes. Three physiological phenotypes are recorded, and used as the response variable in the three datasets: PCR|$i$|, |$i=1,\dots,3$|. We use prior (1) with |$V_{\gamma}=g I$|, where |$g$| is given a half-Cauchy hyperprior distribution, and a hierarchical prior was used for |$\gamma$| by assuming that |$h\sim{\mbox{Be}}\big(1, \frac{p-5}{5}\big)$|, which implies that the prior mean number of included variables is 5. We summarize the results using PCR1, while a more complete analysis of all PCR data is given in the Supplementary Material.
Another dataset, denoted SNP data, relates to genome-wide mapping of a complex trait. The data are weight measurements for 993 outbred mice and 79 748 single nucleotide polymorphisms, SNPs, recorded for each mouse. The testis weight is the response, the body weight is a regressor which is always included in the model and variable selection is performed on the 79 748 SNPs. The high dimensionality makes this a difficult problem and Carbonetto et al. (2017) use a variational inference algorithm, varbvs, for these data. We have used various prior specifications in (1), and present results for a half-Cauchy hyperprior on |$g$| and |$h=5/p$|. Complete results for these data are also provided in the Supplementary Material.
For all datasets, the individual adaptation algorithms were run with |$\tau_{\rm L}=0.05$| and |$\tau_{\rm U}=0.23$|, and |$\tau=0.234$|. The exploratory individual adaptation algorithm had a burn-in of 2150 iterations and 10 750 subsequent iterations and no thinning, and the adaptively scaled individual adaptation had 500 burn-in and 2500 recorded iterations and no thinning, which gave very similar run times. Rao–Blackwellised updates of |$\pi^{(i)}$| were only calculated during the burn-in, and posterior inclusion probability for the |$j$|th variable was estimated by the posterior mean of |$\gamma_j$|. In addition, we show results for the add-delete-swap algorithm and the weighted tempered Gibbs sampler of Zanella & Roberts (2019), which were the most promising alternatives. Three independent runs of all algorithms were executed to gauge the degree of agreement across runs. Using MATLAB and an Intel i7 3.60 GHz processor, each algorithm took about 25 minutes for the PCR data and around 2.5 hours for the SNP data.
Figures 3 and 4 show pairwise comparisons between the different runs for each dataset. The estimates from each independent chain for the adaptively scaled individual adaptation algorithm are very similar, and indicate that the sampler is able to accurately represent the posterior distribution. The weighted tempered Gibbs algorithm performs equally well for the SNP data, but shows worse performance on the PCR1 dataset. The exploratory individual adaptation algorithm does not seem to converge rapidly enough to effectively deal with these very high-dimensional model spaces in the relatively modest running time allocated. Clearly, the add-delete–wap sampler is not able to adequately characterize the posterior model distribution for the PCR data, with dramatically different results across runs, but performs much better for the SNP data.
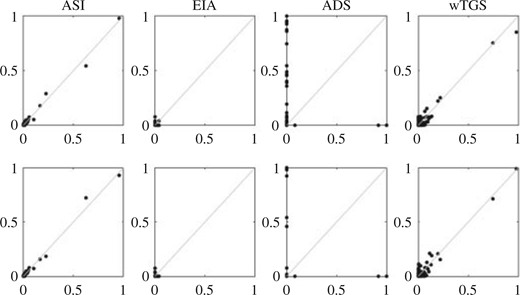
PCR|$1$| data: comparisons of posterior inclusion probabilities from pairs of runs with random |$g$| and |$h$| using adaptively scaled individual adaptation, ASI, exploratory individual adaptation, EIA, add-delete-swap, ADS, and weighted tempered Gibbs sampling, wTGS.
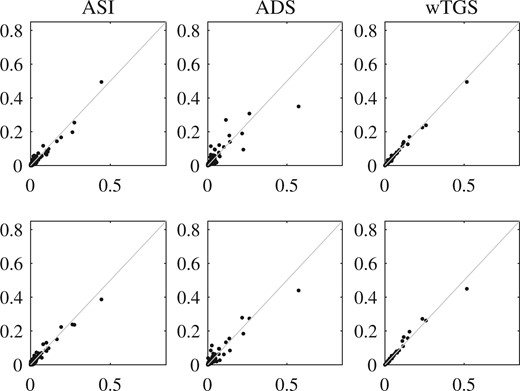
SNP data: comparisons of posterior inclusion probabilities from pairs of runs with random |$g$| and fixed |$h$| using adaptively scaled individual adaptation, ASI, add-delete-swap, ADS, and weighted tempered Gibbs sampling, wTGS.
Acknowledgement
K.Ł. acknowledges support from the Royal Society and the Engineering and Physical Sciences Research Council. The authors thank two referees and an associate editor for their insightful comments that helped improve the paper.
Supplementary material
Supplementary material available at Biometrika online includes proofs, derivations, details of adaptive parallel tempering versions of the algorithms, using the approach of Miasojedow et al. (2013), and further results. Code to run both algorithms is available from https://jimegriffin.github.io/website/.

{kind=link}
{kind=link}
{kind=link}
{kind=link}