




Summary
A novel control variate technique is proposed for the post-processing of Markov chain Monte Carlo output, based on both Stein’s method and an approach to numerical integration due to Sard. The resulting estimators of posterior expected quantities of interest are proven to be polynomially exact in the Gaussian context, while empirical results suggest that the estimators approximate a Gaussian cubature method near the Bernstein–von Mises limit. The main theoretical result establishes a bias-correction property in settings where the Markov chain does not leave the posterior invariant. Empirical results across a selection of Bayesian inference tasks are presented.
1. Introduction
Practical parametric approaches to choosing |$g_n$| have been well studied in the Bayesian context, typically based on polynomial regression models (Assaraf & Caffarel, 1999; Mira et al., 2013; Papamarkou et al., 2014; Oates et al., 2016; Brosse et al., 2019), but neural networks have also been proposed recently (Wan et al., 2019; Si et al., 2020). In particular, existing control variates based on polynomial regression have the attractive property of being semi-exact, meaning that there is a well-characterized set of functions |$f \in \mathcal{F}$| for which |$f_n$| can be shown to exactly equal |$f$| after a finite number |$n$| of samples have been obtained. For the control variates of Assaraf & Caffarel (1999) and Mira et al. (2013), the set |$\mathcal{F}$| contains certain low-order polynomials when |$p$| is a Gaussian distribution on |$\mathbb{R}^d$|. Those authors call their control variates zero-variance, but we prefer the term semi-exact since a general integrand |$f$| will not be an element of |$\mathcal{F}$|. Regardless of terminology, semi-exactness of the control variate is an appealing property because it implies that the approximation |$I_{\mathrm{CV}}(f)$| to |$I(f)$| is exact on |$\mathcal{F}$|. Intuitively, the performance of the control variate method is related to the richness of the set |$\mathcal{F}$| on which it is exact. For example, polynomial exactness of cubature rules can be used to establish their high-order convergence rates via a Taylor expansion argument (e.g., Hildebrand, 1987, Ch. 8).
The development of nonparametric approaches to the choice of |$g_n$| has focused on kernel methods (Oates et al., 2017; Barp et al., 2021), piecewise-constant approximations (Mijatović & Vogrinc, 2018) and nonlinear approximations based on selecting basis functions from a dictionary (Belomestny et al., 2020b; South et al., 2020). Theoretical analysis of nonparametric control variates was provided in the papers cited above, but compared with parametric methods, practical implementations of nonparametric methods are less well developed.
In this paper we propose a semi-exact control functional method. This represents the best of both worlds, in that at small |$n$| the semi-exactness property promotes stability and robustness of the estimator |$I_{\mathrm{CV}}(f)$|, while at large |$n$| the nonparametric regression component can be used to accelerate the convergence of |$I_{\mathrm{CV}}(f)$| to |$I(f)$|. In particular, we argue that in the Bernstein–von Mises limit, the set |$\mathcal{F}$| on which our method is exact is precisely the set of low-order polynomials, so that our method can be regarded as an approximately polynomially exact cubature rule developed for the Bayesian context. Furthermore, we establish a bias-correction property, which guarantees that the approximations produced using our method are consistent in certain settings where the Markov chain is not |$p$|-invariant.
Our motivation comes from an approach to numerical integration due to Sard (1949). Many numerical integration methods are based on constructing an approximation |$f_n$| to the integrand |$f$| that can be exactly integrated. In this case the integral |$I(f)$| is approximated using |$(*)$| in (2). In Gaussian and related cubatures, the function |$f_n$| is chosen in such a way that polynomial exactness is guaranteed (Gautschi, 2004, § 1.4). On the other hand, in kernel cubature and related approaches, |$f_n$| is an element of a reproducing kernel Hilbert space chosen such that an error criterion is minimized (Larkin, 1970). The contribution of Sard was to combine these two concepts in numerical integration by choosing |$f_n$| to enforce exactness on a low-dimensional space |$\mathcal{F}$| of functions and using the remaining degrees of freedom to find a minimum-norm interpolant to the integrand.
2. Methods
2.1. Sard’s method
If the set of points |$\{x^{(i)}\}_{i=1}^n$| is fixed, the cubature method in (3) has |$n$| degrees of freedom corresponding to the choice of the weights |$\{w_i\}_{i=1}^n$|. The approach proposed by Sard (1949) is a hybrid of the two classical approaches just described, calling for |$m \leqslant n$| of these degrees of freedom to be used to ensure that |$I_{\mathrm{NI}}(f)$| is exact for |$f$| in a given |$m$|-dimensional linear function space |$\mathcal{F}$| and, if |$m < n$|, allocating the remaining |$n-m$| degrees of freedom to select a minimum-norm interpolant from a large class of functions |$\mathcal{H}$|. The approach of Sard is therefore exact for functions in the finite-dimensional set |$\mathcal{F}$| and, at the same time, suitable for the integration of functions in the infinite-dimensional set |$\mathcal{H}$|. Further background on Sard’s method can be found in Larkin (1974) and Karvonen et al. (2018).
However, it is difficult to implement Sard’s method, or indeed any of the classical approaches just discussed, in the Bayesian context, because:
- (i)
the density |$p$| can be evaluated pointwise only up to an intractable normalization constant;
- (ii)
to construct weights, one needs to evaluate the integrals of basis functions of |$\mathcal{F}$| and of the interpolant |$f_n$|, which can be as difficult as evaluating the original integral.
To circumvent these issues, we propose to combine Sard’s approach to integration with Stein operators (Stein, 1972; Gorham & Mackey, 2015), thus eliminating the need to access normalization constants and to exactly evaluate integrals.
2.2. Stein operators
We refer to |$\mathcal{L}$| as a Stein operator owing to the use of equations of the form (5), up to a simple substitution, in the method of Stein (1972) for assessing convergence in distribution and because of its property of producing functions whose integrals with respect to |$p$| are zero under suitable conditions such as those described in Lemma 1.
The proof is provided in the Supplementary Material. Although our attention is limited to (5), the choice of Stein operator is not unique, and other Stein operators can be derived using the generator method of Barbour (1988) or using Schrödinger Hamiltonians (Assaraf & Caffarel, 1999). Contrary to the standard requirements for a Stein operator, the operator |$\mathcal{L}$| in control functionals does not need to fully characterize convergence, and consequently a broader class of functions |$g$| can be considered than in more traditional applications of Stein’s method (Stein, 1972).
It follows that if the conditions of Lemma 1 are satisfied by |$g_n : \mathbb{R}^d \rightarrow \mathbb{R}$|, the integral of a function of the form |$f_n = c_n + \mathcal{L} g_n$| is simply |$c_n$|, the constant. The main challenge in developing control variates, or functionals, based on Stein operators is therefore to find a function |$g_n$| such that the asymptotic variance |$\sigma(f - f_n)^2$| is small. To explicitly minimize asymptotic variance, Mijatović & Vogrinc (2018), Brosse et al. (2019) and Belomestny et al. (2020a) restricted attention to particular Metropolis–Hastings or Langevin samplers for which the asymptotic variance can be explicitly characterized. The minimization of empirical variance has also been proposed and studied in cases where samples are independent (Belomestny et al., 2020b) and dependent (Belomestny et al., 2020a,c). For an approach that is not tied to a particular Markov kernel, Assaraf & Caffarel (1999) and Mira et al. (2013), among others, proposed minimizing the mean squared error along the sample path, which corresponds to the case of an independent sampling method. In a similar spirit, the constructions in Oates et al. (2017, 2019) and Barp et al. (2021) are based on a minimum-norm interpolant, where the choice of norm is decoupled from the mechanism by which the points are sampled.
2.3. The proposed method
In this section we first construct an infinite-dimensional space |$\mathcal{H}$| and a finite-dimensional space |$\mathcal{F}$| of functions; these will underpin the proposed semi-exact control functional method.
The proof is provided in the Supplementary Material. The infinite-dimensional space |$\mathcal{H}$| used here is exactly the reproducing kernel Hilbert space |$\mathcal{H}(k_0)$|. The basic mathematical properties of |$k_0$| and the Hilbert space it reproduces are given in the Supplementary Material, and these can be used to inform the selection of an appropriate kernel.
For the finite-dimensional component, let |$\Phi$| be a linear space of twice continuously differentiable functions with dimension |$m-1$|, where |$m \in \mathbb{N}$|, and a basis |$\{\phi_i\}_{i=1}^{m-1}$|. Define the space obtained by applying the differential operator (5) to |$\Phi$| as |$\mathcal{L} \Phi = \mathrm{span}\{ \mathcal{L} \phi_1, \ldots, \mathcal{L} \phi_{m-1} \}$|. If the preconditions of Lemma 1 are satisfied for each basis function |$g = \phi_i$|, then linearity of the Stein operator implies that |$\int (\mathcal{L}\phi) \,\mathrm{d}p = 0$| for every |$\phi \in \Phi$|. Typically we will select |$\Phi = \mathcal{P}^r$| as the polynomial space |$\mathcal{P}^r = \mathrm{span} \{ x^{\alpha} : \alpha \in \mathbb{N}_0^d, \, 0 < |{\alpha}| \leqslant r \}$| for some nonnegative integer |$r$|. Constant functions are excluded from |$\mathcal{P}^r$| since they are in the null space of |$\mathcal{L}$|; when required we let |$\mathcal{P}_0^r = \text{span}\{1\} \oplus \mathcal{P}^r$| denote the larger space with the constant functions included. The finite-dimensional space |$\mathcal{F}$| is then taken to be |$ \mathcal{F} = \mathrm{span} \{1\} \oplus \mathcal{L} \Phi = \mathrm{span} \{1, \mathcal{L} \phi_1, \ldots \mathcal{L} \phi_{m-1} \}$|.
(Interpolation). We have |$f_n(x^{(i)} ; f) = f(x^{(i)})$| for |$i = 1, \ldots, n$|.
(Semi-exactness) We have |$f_n(\cdot\, ;f) = f(\cdot)$| whenever |$f \in \mathcal{F}$|.
Since |$\mathcal{F}$| is |$m$|-dimensional, these requirements yield a total of |$n+m$| constraints. Under weak conditions, discussed in § 2.5, the total number of degrees of freedom due to selection of |$a$| and |$b$| is equal to |$n+m$| and Conditions 1 and 2 can be satisfied. Furthermore, the corresponding function |$f_n$| can be shown to minimize a particular seminorm on a larger space of functions, subject to the interpolation and exactness constraints; to limit the scope of the paper, we do not discuss this characterization further, but the seminorm is defined in (16) and the reader can find full details in Wendland (2004, Theorem 13.1). Figure 1 illustrates one such interpolant. The proposed estimator of the integral is then
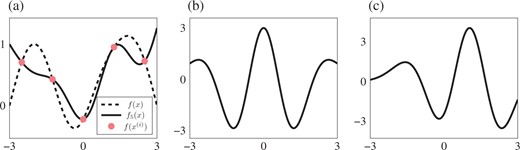
(a) The interpolant |$f_n$| from (9) at |$n=5$| points to the function |$f(x) = \sin\{0.5\pi (x-1)\} + \exp\{-(x-0.5)^2\}$| for the Gaussian density |$p(x) = \mathcal{N}(x; 0,1)$|; the interpolant uses the Gaussian kernel |$k(x,y) = \exp\{-(x-y)^2\}$| and a polynomial parametric basis with |$r=2$|. Two translates (b) |$k_0(\cdot\,,0)$| and (c) |$k_0(\cdot\,,1)$| of the kernel (6).
Under the hypotheses of Lemma 1 for each |$g = \phi_i \ (i = 1,\dots,m-1)$| and Lemma 2, whenever the estimator |$I_{\mathrm{SECF}}(f)$| is well-defined, we have |$I_{\mathrm{SECF}}(f) = b_1$| where |$b_1$| is the constant term in (9).
The earlier work of Assaraf & Caffarel (1999) and Mira et al. (2013) corresponds to |$a = 0$| and |$b \neq 0$|, while setting |$b = 0$| in (9) and ignoring the semi-exactness requirement recovers the unique minimum-norm interpolant in the Hilbert space |$\mathcal{H}(k_0)$| where |$k_0$| is reproducing, in the sense of (4). The work of Oates et al. (2017) corresponds to |$b_i = 0$| for |$i = 2,\dots,m$|. It is therefore clear that the proposed approach is a strict generalization of existing work and can be seen as a compromise between semi-exactness and minimum-norm interpolation.
2.4. Polynomial exactness in the Bernstein–von Mises limit
Consider the Bernstein–von Mises limit and suppose that the Fisher information matrix |$I(\hat{x}_N)$| is nonsingular. Then, for the choice |$\Phi = \mathcal{P}^r$| with |$r \in \mathbb{N}$|, the estimator |$I_\mathrm{SECF}$| is exact on |$\mathcal{F} = \mathcal{P}_0^r$|.
Thus the proposed estimator is polynomially exact up to order |$r$| in the Bernstein–von Mises limit. We believe that this property can confer robustness of the estimator in a broad range of applied contexts. At finite |$N$|, when the limit has not been reached, the above argument can be expected to hold only approximately.
2.5. Computation for the proposed method
The requirement in Lemma 4 for the |$x^{(i)}$| to be distinct precludes, for example, the direct use of Metropolis–Hastings output. However, as emphasized in Oates et al. (2017) for control functionals and studied further in Liu & Lee (2017) and Hodgkinson et al. (2020), the consistency of |$I_{\mathrm{SECF}}$| does not require that the Markov chain be |$p$|-invariant. It is therefore trivial to, for example, filter out duplicate states from Metropolis–Hastings output.
The solution of linear systems of equations defined by an |$n \times n$| matrix |$K_0$| and an |$m \times m$| matrix |$P^{ \mathrm{\scriptscriptstyle T} } K_0^{-1} P$| entails a computational cost of |$O(n^3 + m^3)$|. In some situations this cost may yet be smaller than the cost associated with evaluation of |$f$| and |$p$|, but in general this computational requirement limits the applicability of the method just described. In the Supplementary Material we propose a computationally efficient approximation, |$I_{\mathrm{ASECF}}$|, to the full method, based on a combination of the Nyström approximation (Williams & Seeger, 2001) and the well-known conjugate gradient method, inspired by the recent work of Rudi et al. (2017).
3. Empirical assessment
3.1. Experimental set-up
We performed a detailed comparison of existing and proposed control variate and control functional techniques. Three examples were considered: a Gaussian target, representing the Bernstein–von Mises limit; a setting in which nonparametric control functional methods perform well; and a setting where parametric control variate methods are known to be successful. In each case we determine whether or not the proposed semi-exact control functional method is competitive with the state-of-the-art technique.
Specifically, we compare the following estimators, all instances of |$I_{\mathrm{CV}}$| in (2) for a particular choice of |$f_n$|, which may or may not be an interpolant:
- (i)
standard Monte Carlo integration, (1), based on Markov chain output;
- (ii)
the control functional estimator recommended in Oates et al. (2017), |$I_{\mathrm{CF}}(f) = (1^{ \mathrm{\scriptscriptstyle T} }K_0^{-1}1)^{-1} 1^{{ \mathrm{\scriptscriptstyle T} }} K_0^{-1}f$|;
- (iii)
the zero-variance polynomial control variate method of Assaraf & Caffarel (1999) and Mira et al. (2013), |$I_{\mathrm{ZV}}(f) = e_1^{ \mathrm{\scriptscriptstyle T} } (P^{ \mathrm{\scriptscriptstyle T} } P)^{-1}P^{ \mathrm{\scriptscriptstyle T} } f$|;
- (iv)
the auto-zero-variance approach of South et al. (2020), which uses five-fold cross-validation to automatically select (A) between the ordinary least squares solution |$I_{\mathrm{ZV}}$| and an |$\ell_1$|-penalized alternative, where the penalization strength is itself selected using 10-fold cross-validation within the test dataset, and (B) the polynomial order;
- (v)
the proposed semi-exact control functional estimator, (13);
- (vi)
an approximation, |$I_{\mathrm{ASECF}}$|, of (13) based on the Nyström approximation and the conjugate gradient method, described in the Supplementary Material.
Open-source software for implementing all of the above methods is available in the |$\texttt{R}$| (R Development Core Team, 2022) package |$\texttt{ZVCV}$| (South, 2020). The same sets of |$n$| samples were used for all estimators, in both the construction of |$f_n$| and the evaluation of |$I_{\mathrm{CV}}$|. For methods in which there is a fixed polynomial basis we considered only orders |$r=1$| and |$r=2$|, following the recommendation of Mira et al. (2013). For kernel-based methods, duplicate values of |$x_i$| were removed, as discussed in § 2.5, and Frobenius regularization was employed whenever the condition number of the kernel matrix |$K_0$| was close to machine precision (Higham, 1988). Several choices of kernel were considered, but for brevity we focus here on the rational quadratic kernel |$k(x,y; \lambda) = (1+\lambda^{-2} \|x-y\|^2)^{-1}$|. This kernel was found to yield the best performance across a range of experiments; a comparison with the Matérn and Gaussian kernels is provided in the Supplementary Material. The parameter |$\lambda$| was selected using five-fold cross-validation, based again on performance across a spectrum of experiments; a comparison with the median heuristic (Garreau et al., 2017) is presented in the Supplementary Material.
3.2. Gaussian illustration
Figure 2 displays the statistical efficiency of each estimator for |$10 \leqslant n \leqslant 1000$| and |$3 \leqslant d \leqslant 100$|. Computational efficiency is not shown since exact sampling from |$p$| in this example is trivial. The proposed semi-exact control functional method performs consistently well compared to its competitors for this nonpolynomial integrand. Unsurprisingly, the best improvements are for large |$n$| and small |$d$|, where the proposed method results in a statistical efficiency over 100 times better than the baseline estimator and up to five times better than the next-best method.
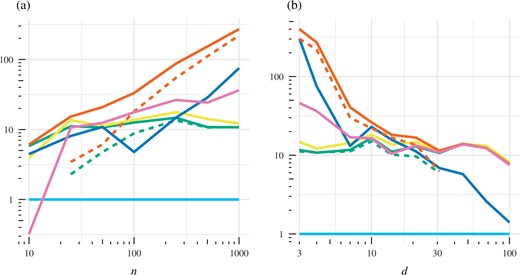
Gaussian example: (a) estimated statistical efficiency |$\hat{\mathcal{E}}$| with |$d=4$| and (b) estimated statistical efficiency |$\hat{\mathcal{E}}$| with |$n=1000$| for the integrand (15). The methods compared are standard Monte Carlo integration (light blue), the control functional estimator of Oates et al. (2017) (dark blue), the zero-variance polynomial control variate method of Assaraf & Caffarel (1999) and Mira et al. (2013) (green), the auto-zero-variance approach of South et al. (2020) (yellow), the proposed semi-exact control functional estimator (orange), and an approximate semi-exact control functional estimator (pink); dashed and solid lines correspond to polynomial order 2 and order 1, respectively (if applicable).
3.3. Capture-recapture example
The two remaining examples, presented here and in § 3.4, are applications of Bayesian statistics described in South et al. (2020). In each case the aim is to estimate expectations with respect to a posterior distribution |$P_{x \mid y}$| of the parameters |$x$| of a statistical model based on |$y$|, an observed dataset. Samples |$x^{(i)}$| were obtained using the Metropolis-adjusted Langevin algorithm (Roberts & Tweedie, 1996), which is a Metropolis–Hastings algorithm with proposal |$\mathcal{N} \{ x^{(i-1)} + (h^2/2)\Sigma\nabla_{x} \log P_{x \mid y}(x^{(i-1)} \mid y), h^2 \Sigma\}$|. Step sizes of |$h=0.72$| for the capture-recapture example and |$h=0.3$| for the sonar example in § 3.4 were selected, and an empirical approximation of the posterior covariance matrix was used as the preconditioner |$\Sigma \in \mathbb{R}^{d\times d}$|. Since the proposed method does not rely on the Markov chain being |$P_{x \mid y}$|-invariant, we also repeated these experiments using the unadjusted Langevin algorithm (Ermak, 1975; Parisi, 1981); the results are similar and are reported in the Supplementary Material.
South et al. (2020) found that nonparametric methods outperformed standard parametric methods for this 11-dimensional example. The estimator |$I_{\mathrm{SECF}}$| combines elements of both approaches, so one is interested in determining how the method performs. It is clear from Fig. 3 that all variance-reduction approaches are helpful in improving upon the vanilla Monte Carlo estimator in this example. The best improvement in terms of statistical and computational efficiency is provided by |$I_{\mathrm{SECF}}$|, which also has similar performance to |$I_{\mathrm{CF}}$|.
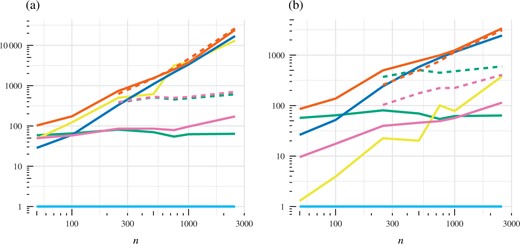
Capture-recapture example: (a) estimated statistical efficiency |$\hat{\mathcal{E}}$| and (b) estimated computational efficiency |$\hat{\mathcal{C}}$|. Efficiency here is reported as an average over the 11 expectations of interest. The methods compared are standard Monte Carlo integration (light blue), the control functional estimator of Oates et al. (2017) (dark blue), the zero-variance polynomial control variate method of Assaraf & Caffarel (1999) and Mira et al. (2013) (green), the auto-zero-variance approach of South et al. (2020) (yellow), the proposed semi-exact control functional estimator (orange), and an approximate semi-exact control functional estimator (pink); dashed and solid lines correspond to polynomial order 2 and order 1, respectively (if applicable).
3.4. Sonar example
We use an |$\mathcal{N}(0,5^2)$| prior for the predictors, after standardizing to a standard deviation of 0.5, and a |$\mathcal{N}(0,20^2)$| prior for the intercept, following Chopin & Ridgway (2017) and South et al. (2020); however, we focus on estimating the more challenging integrand |$f(\beta) = \{ 1+\exp(-\tilde{X}\beta) \}^{-1}$|, which can be interpreted as the probability that observed covariates |$\tilde{X}$| emanate from a metal cylinder. The gold standard of |$I \approx 0.4971$| was obtained from a Metropolis–Hastings procedure (Hastings, 1970) with 10 million iterations, run with a multivariate normal random walk proposal.
Figure 4 illustrates the statistical and computational efficiency of estimators for various |$n$| in this example. It is interesting that |$I_{\mathrm{SECF}}$| and |$I_{\mathrm{ASECF}}$| offer similar statistical efficiency to |$I_{\mathrm{ZV}}$|, especially given the poor relative performance of |$I_{\mathrm{CF}}$|. Since it is inexpensive to obtain the |$n$| samples using the Metropolis-adjusted Langevin algorithm in this example, |$I_{\mathrm{ZV}}$| and |$I_{\mathrm{ASECF}}$| are the only approaches that yield improvements in computational efficiency over the baseline estimator for the majority of |$n$| values considered, and even in these instances the improvements are marginal.
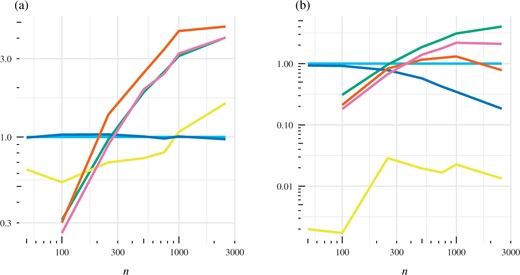
Sonar example: (a) estimated statistical efficiency |$\hat{\mathcal{E}}$| and (b) estimated computational efficiency |$\hat{\mathcal{C}}$|. The methods compared are standard Monte Carlo integration (light blue), the control functional estimator of Oates et al. (2017) (dark blue), the zero-variance polynomial control variate method of Assaraf & Caffarel (1999) and Mira et al. (2013) (green), the auto-zero-variance approach of South et al. (2020) (yellow), the proposed semi-exact control functional estimator (orange), and an approximate semi-exact control functional estimator (pink).
4. Theoretical properties and convergence assessment
4.1. Finite-sample error and a practical diagnostic
The proof is provided in the Supplementary Material. The first quantity on the right-hand side of (17), |$|f|_{k_0,\mathcal{F}}$|, can be approximated by |$|f_n|_{k_0,\mathcal{F}}$| when |$f_n$| is a reasonable approximation for |$f$|, and this can in turn can be bounded as |$|f_n|_{k_0,\mathcal{F}} \leqslant (a^{ \mathrm{\scriptscriptstyle T} } K_0 a)^{1/2}$|. The finiteness of |$|f|_{k_0,\mathcal{F}}$| ensures the existence of a solution to the Stein equation, sufficient conditions for which are discussed in Mackey & Gorham (2016) and Si et al. (2020). The second quantity on the right-hand side of (17), |$(w^{ \mathrm{\scriptscriptstyle T} } K_0 w)^{1/2}$|, is computable and can be recognized as a kernel Stein discrepancy between the empirical measure |$\sum_{i=1}^n w_i \delta(x^{(i)})$| and the distribution whose density is |$p$|, based on the Stein operator |$\mathcal{L}$| (Chwialkowski et al., 2016; Liu et al., 2016). Our choice of Stein operator differs from that in Chwialkowski et al. (2016) and Liu et al. (2016). There has been substantial recent research into the use of kernel Stein discrepancies for assessing algorithm performance in the Bayesian computational context (Gorham & Mackey, 2017; Chen et al., 2018, 2019; Singhal et al., 2020; Hodgkinson et al., 2020), and one can also exploit this discrepancy as a diagnostic for the performance of the semi-exact control functional. The diagnostic that we propose to monitor is the product |$(w^{ \mathrm{\scriptscriptstyle T} } K_0 w)^{1/2} (a^{ \mathrm{\scriptscriptstyle T} } K_0 a)^{1/2}$|. This approach to error estimation was also suggested, outside the Bayesian context, in Fasshauer (2011, § 5.1).
The empirical results shown in Fig. 5 suggest that this diagnostic provides a conservative approximation of the actual error. Further work is needed to establish whether this diagnostic detects convergence and nonconvergence in general.
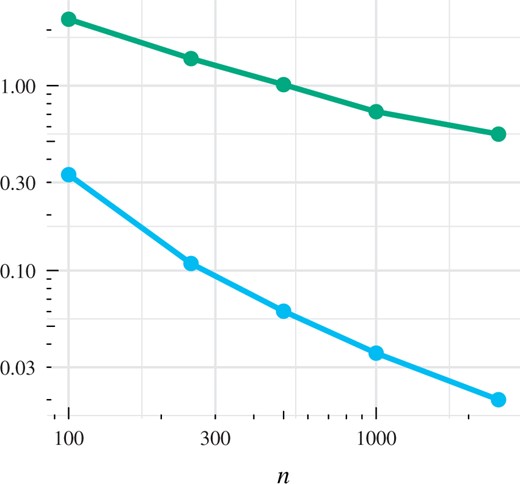
The mean absolute error (blue) and mean of the approximate upper bound |$(w^{ \mathrm{\scriptscriptstyle T} } K_0 w)^{1/2} (a^{ \mathrm{\scriptscriptstyle T} } K_0 a)^{1/2}$| (green) for different values of |$n$| in the sonar example of § 3.4. Both are based on the semi-exact control functional method with |$\Phi = \mathcal{P}^1$|.
4.2. Consistency of the estimator
In what follows we consider an increasing number |$n$| of samples |$\boldsymbol{x}^{(i)}$|, while the finite-dimensional space |$\Phi$|, with basis |$\{\phi_1,\dots,\phi_{m-1}\}$|, is held fixed. The samples |$\boldsymbol{x}^{(i)}$| will be assumed to arise from a |$V$|-uniformly ergodic Markov chain; the reader is referred to Meyn & Tweedie (2012, Ch. 16) for the relevant background. Recall that the points |$(x^{(i)})_{i=1}^n$| are said to be |$\mathcal{F}$|-unisolvent if the matrix in (11) has full rank. It will be convenient to introduce an inner product |$\langle {u}, {v} \rangle_n = {u}^{ \mathrm{\scriptscriptstyle T} } {K}_0^{-1} {v}$| and associated norm |$\|{u}\|_n = \langle {u}, {u} \rangle_n^{1/2}$|. Let |$\Pi$| be the matrix that projects orthogonally onto the columns of |$[{\Psi}]_{i,j} = \mathcal{L} \phi_j({x}^{(i)})$| with respect to the |$\langle \cdot \,, \cdot \rangle_n$| inner product.
Suppose that the hypotheses of Corollary 1 hold, and let |$f$| be any function for which |$|f|_{k_0,\mathcal{F}} < \infty$|. Let |$q$| be a probability density with |$p/q > 0$| on |$\mathbb{R}^d$|, and consider a |$q$|-invariant Markov chain |$({x}^{(i)})_{i=1}^n$|, assumed to be |$V$|-uniformly ergodic for some |$V : \mathbb{R}^d \rightarrow [1,\infty)$|, such that
- (i)
|$\sup_{x \in \mathbb{R}^d} \; V(x)^{-r} \; \{p(\boldsymbol{x}) / q(\boldsymbol{x})\}^4 \; k_0(x,x)^2 < \infty$| for some |$0 < r < 1$|;
- (ii)
the points |$(x^{(i)})_{i=1}^n$| are almost surely distinct and |$\mathcal{F}$|-unisolvent;
- (iii)
|$\lim\sup_{n \rightarrow \infty} \| \Pi \,{1} \|_n / \| {1} \|_n < 1$| almost surely.
Then |$| I_{\mathrm{SECF}}(f) - I(f)| = O_\mathrm{P}(n^{1/2})$|.
This demonstrates that, even in the biased-sampling setting, the proposed estimator is consistent. The proof is provided in the Supplementary Material and exploits a recent theoretical contribution from Hodgkinson et al. (2020). Assumption (i) serves to ensure that |$q$| is similar enough to |$p$| that a |$q$|-invariant Markov chain will also explore the high-probability regions of |$p$|, as discussed in Hodgkinson et al. (2020). Sufficient conditions for |$V$|-uniform ergodicity are necessarily Markov chain-dependent. The case of the Metropolis-adjusted Langevin algorithm is discussed in Roberts & Tweedie (1996) and Chen et al. (2019), and in particular Theorem 9 of Chen et al. (2019) gives sufficient conditions for |$V$|-uniform ergodicity with |$V(\boldsymbol{x}) = \exp(s \|\boldsymbol{x}\|)$| for all |$s > 0$|. Under these conditions, and with the rational quadratic kernel |$k$| considered in § 3, we have |$k_0(\boldsymbol{x},\boldsymbol{x}) = O\{\|\nabla_{\boldsymbol{x}} \log p(\boldsymbol{x})\|^2\}$| and so (i) is satisfied whenever |$\{p(\boldsymbol{x}) / q(\boldsymbol{x}) \} \|\nabla_{\boldsymbol{x}} \log p(\boldsymbol{x})\| = O\{\exp( t \|\boldsymbol{x}\|)\}$| for some |$t > 0$|, a weak requirement. Assumption (ii) ensures that the finite-sample error bound (17) is almost surely well-defined. Assumption (iii) ensures that the points in the sequence |$(\boldsymbol{x}^{(i)})_{i=1}^n$| distinguish, asymptotically, the constant function from the functions |$\{\phi_i\}_{i=1}^{m-1}$|, which is a weak technical requirement.
5. Discussion
Several possible extensions of the proposed method can be considered. For example, the parametric component |$\Phi$| could be adapted to the particular |$f$| and |$p$| using a dimensionality reduction method. Likewise, extending cross-validation to encompass the choice of kernel and even the choice of control variate or control functional estimator may be useful. The potential for alternatives to the Nyström approximation to further improve scalability of the method can also be explored. In terms of the points |$x^{(i)}$| on which the estimator is defined, these could be optimally selected to minimize the error bound in (17), for example following the approaches of Chen et al. (2018, 2019). Finally, we highlight a possible extension to the case where only stochastic gradient information is available, following Friel et al. (2016) in the parametric context.
Acknowledgement
Oates is grateful to Yvik Swan for discussion of Stein’s method. Karvonen was supported by the Aalto ELEC Doctoral School and the Vilho, Yrjö and Kalle Väisälä Foundation. Girolami was supported by the Royal Academy of Engineering Research Chair and the U.K. Engineering and Physical Sciences Research Council (EP/T000414/1, EP/R018413/2, EP/P020720/2, EP/R034710/1, EP/R004889/1). Karvonen, Girolami and Oates were supported by the Lloyd’s Register Foundation programme on data-centric engineering at the Alan Turing Institute, U.K. Nemeth and South were supported by the Engineering and Physical Sciences Research Council (EP/S00159X/1 and EP/V022636/1). The authors are grateful for feedback from three reviewers, an associate editor and the editor.
Supplementary material
Supplementary material available at Biometrika online includes further technical details, additional simulation results and proofs of the theoretical results stated in the main article.
References
R Development Core Team (

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}