





Summary
This paper provides an orthogonal extension of the semiparametric difference-in-differences estimator proposed in earlier literature. The proposed estimator enjoys the so-called Neyman orthogonality (Chernozhukov et al., 2018), and thus it allows researchers to flexibly use a rich set of machine learning methods in the first-step estimation. It is particularly useful when researchers confront a high-dimensional data set in which the number of potential control variables is larger than the sample size and the conventional nonparametric estimation methods, such as kernel and sieve estimators, do not apply. I apply this orthogonal difference-in-differences estimator to evaluate the effect of tariff reduction on corruption. The empirical results show that tariff reduction decreases corruption in large magnitude.
1. INTRODUCTION
The difference-in-differences (DiD) estimator has been used widely in empirical economics to evaluate causal effects when there exists a natural experiment with a treated group and an untreated group. By comparing the variation over time in an outcome variable between the treated group and the untreated group, the DiD estimator can be used to calculate the effect of treatment on the outcome variable. Applications of DiD include but are not limited to studies of the effects of immigration on laboru markets (Card, 1990), the effects of minimum wage law on wages (Card and Krueger, 1994), the effect of tariff liberalisation on corruption (Sequeira, 2016), the effect of household income on children’s personalities (Akee et al., 2018), and the effect of corporate tax on wages (Fuest, Peichl, and Siegloch, 2018).
The traditional linear DiD estimator depends on a parallel-trend assumption that in the absence of treatment, the difference in outcomes between treated and untreated groups remains constant over time. In many situations, however, this assumption may not hold because there are other individual characteristics that may be associated with the variations of the outcomes. The treatment may be taken as exogenous only after controlling for these characteristics. However, as noted by Meyer, Viscusi, and Durbin (1995), including control variables in the linear specification of the traditional DiD estimator imposes strong constraints on the heterogeneous effect of treatment. To address this problem, Abadie (2005) proposed the semiparametric DiD estimator. Compared to the traditional linear DiD estimator, the advantages of Abadie’s estimator are threefold. First, the characteristics are treated nonparametrically so that any estimation error caused by functional specification is avoided. Second, the effect of treatment is allowed to vary among individuals, whereas the traditional linear DiD estimator does not allow this heterogeneity. Third, the estimation framework proposed in Abadie (2005) will enable researchers to estimate how the effect of treatment varies with changes in the characteristics.
The present paper provides an orthogonal extension of Abadie’s semiparametric DiD estimator (DMLDiD hereafter).1 Abadie’s semiparametric DiD estimator behaves well when researchers use conventional nonparametric methods, such as kernel and sieve estimators, to estimate the propensity score in the first-step estimation. As shown in the classical semiparametric estimation literature, Abadie’s DiD estimator is |$\sqrt{N}$|-consistent and asymptotically normal when kernel or sieve is used in the first-step estimation. However, according to the general theory of inference developed in Chernozhukov et al. (2018), these desirable properties may fail if researchers use a rich set of newly developed nonparametric estimation methods, the so-called machine learning (ML) methods, such as Lasso, Logit Lasso, random forests, boosting, neural network, and their hybrids, in the first-step estimation. This is especially a problem when researchers confront a high-dimensional data set in which the number of potential control variables is more than the sample size, and thus the conventional nonparametric estimation methods do not apply.
In this paper, I propose DMLDiD for three different data structures: repeated outcomes, repeated cross sections, and multilevel treatment, which are all based on the original paper by Abadie (2005), as well as on the papers on the general inference theory of ML methods by Chernozhukov et al. (2018) and Chernozhukov et al. (2019). DMLDiD will allow researchers to apply a broad set of ML methods and still obtain valid inferences. The key difference is that DMLDiD, in contrast to Abadie’s original DiD estimator, is constructed on the basis of a score function that satisfies the so-called Neyman orthogonality (Chernozhukov et al. 2018), which is an important property for obtaining valid inferences when applying ML methods. With this property, DMLDiD can overcome the bias caused by the first-step ML estimation and achieve |$\sqrt{N}$|-consistency and asymptotic normality as long as the ML estimator converges to its true value at a rate faster than N−1/4. Figure 1 shows the Monte Carlo simulation that illustrates the negative effect of directly combining ML methods on Abadie’s estimator and the benefit of using DMLDiD. The histogram in the left panel shows that the simulated distribution of Abadie’s estimator is biased, whereas the simulated distribution of DMLDiD in the right panel is centred at the true value.
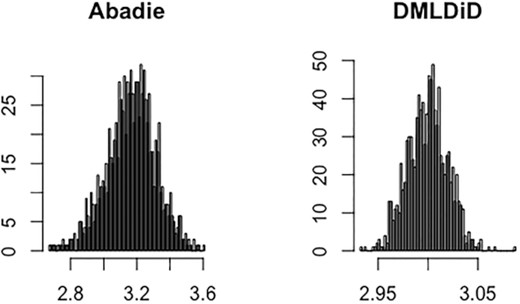
Comparison of Abadie’s DiD and DMLDiD with the first-step Logit Lasso estimation. The true value is θ0 = 3. The results for other ML methods can be found in Section 4.
As an empirical example, I study the effect of tariff reduction on corruption by using the trade data between South Africa and Mozambique during 2006 and 2014. The source of exogenous variation is the large tariff reduction on certain commodities occurring in 2008. This natural experiment was studied previously by Sequeira (2016) using the traditional linear DiD estimator. On the basis of Sequeira’s linear specification, I include the interaction terms between the treatment and a vector of control variables. After controlling for the interaction terms, I find that the traditional linear DiD estimate becomes insignificantly different from zero. This suggests the existence of heterogeneous treatment effects, and Sequeira’s result can be interpreted as a weighted average of these heterogeneous effects. As pointed out by Abadie (2005), it is ideal to treat the control variables nonparametrically when there exists heterogeneity in treatment effects, to avoid any inconsistency caused by functional form misspecification. I apply both Abadie’s semiparametric DiD and DMLDiD on the same data set (Table 9 of Sequeira, 2016). In comparison with Sequeira’s result, though with the same sign, Abadie’s estimator is at least twice as large as previously reported by Sequeira (2016). This large effect, however, may be due to the lack of robustness of this estimation method and the finite-sample bias in the first-step nonparametric estimation. DMLDiD removes the first-order bias and suggests a smaller effect that is closer to Sequeira’s estimate. The value becomes only 60% higher than Sequeira’s result. This extra effect can be explained by the misspecification of the traditional linear DiD estimator. Therefore, I obtain the same conclusion as Sequeira (2016) that tariff reduction decreases corruption, but my estimate suggests an even larger magnitude.
The DMLDiD proposed in the present paper relies heavily on the recent high-dimensional and ML literature: Belloni et al. (2012), Belloni, Chernozhukov, and Hansen (2014), Chernozhukov et al. (2015), Belloni et al. (2017), and Chernozhukov et al. (2018). The present paper is also closely related to the robustness of average treatment effect estimation discussed in Robins and Rotnitzky (1995) and the general discussion in Chernozhukov et al. (2019). The asymptotic properties of the robust estimators discussed in those papers remain unaffected if only one of the first-step estimation with classical nonparametric method is inconsistent. In independent and contemporaneous works, Zimmert (2019), Sant’Anna and Zhao (2019), Li (2019), and Lu, Nie, and Wager (2019) also considered the orthogonal property of Abadie’s DiD estimator. Zimmert (2019) further discussed its efficiency, whereas Sant’Anna and Zhao (2019) and Li (2019) focused on classical first-step estimation. Lu, Nie, and Wager (2019) discussed the situation in which control variables are correlated with time.
1.1. Plan of the paper
Section 2 reviews both the traditional linear DiD estimator and Abadie’s semiparametric DiD estimator and discusses their limitations. Section 3 presents DMLDiD and discusses its theoretical properties. Section 4 conducts the Monte Carlo simulation to shed some light on the finite-sample performance of the proposed DiD estimator. Section 5 provides the empirical application, and Section 6 concludes the paper.
2. THE SEMIPARAMETRIC DID ESTIMATOR
2.1. Case 1 (repeated outcomes)
Suppose that researchers observe both pre-treatment and post-treatment outcomes for the individual of interest. That is, researchers observe |$\left\lbrace Y_{i}\left(0\right),Y_{i}\left(1\right),D_{i},X_{i}\right\rbrace _{i=1}^{N}$|. In this case, we can identify the ATT under the following assumptions (Abadie, 2005):
|$E\left[Y_{i}^{0}\left(1\right)-Y_{i}^{0}\left(0\right)\mid X_{i},D_{i}=1\right]=E\left[Y_{i}^{0}\left(1\right)-Y_{i}^{0}\left(0\right)\mid X_{i},D_{i}=0\right]$|.
P(Di = 1) > 0 and P(Di = 1∣Xi) < 1, with probability one.
2.2. Case 2 (repeated cross sections)
Suppose what researchers observe is repeated cross-sectional data. That is, researchers observe |$\left\lbrace Y_{i},D_{i},T_{i},X_{i}\right\rbrace _{i=1}^{N}$|, where Yi = Yi(0) + Ti(Yi(1) − Yi(0)), and Ti is a time indicator that takes value one if the observation belongs to the post-treatment sample.
Conditional on T = 0, the data are independent and identically distributed from the distribution of (Y(0), D, X), and conditional on T = 1, the data are independent and identically distributed from the distribution of (Y(1), D, X).
The next section proposes DMLDiD based on (2.1) and (2.2). A distinctive feature of DMLDiD is that the Gateaux derivatives of the score functions are zero with respect to their infinite-dimensional nuisance parameters. This property helps us remove the first-order bias of the first-step ML estimation.
3. THE DMLDID ESTIMATOR
In this section, I propose DMLDiD on the basis of Abadie’s results (2.1) and (2.2). In Section 3.1, I present the new score functions derived from (2.1) and (2.2) and propose an algorithm to construct DMLDiD. In Section 3.2, I show the theoretical properties of the proposed estimator.
3.1. The Neyman-orthogonal score
Suppose Assumptions 2.1 through 2.3 hold, and consider the following new score functions.
Notice that the above new functions are equal to the original score functions (2.1) and (2.2) plus the adjustment terms, (c1, c2), which have zero expectations. Thus, the new score functions (3.1) and (3.2) still identify the ATT in each case. The purpose of the adjustment terms is to make the Gateaux derivative of the new score functions zero with respect to infinite-dimensional nuisance parameters, which is the so-called Neyman-orthogonal property in Chernozhukov et al. (2018). I combine the new scores (3.1) and (3.2) with the cross-fitting algorithm of Chernozhukov et al. (2018) to propose DMLDiD.
The estimators |$\left(\hat{g}_{k},\hat{\ell }_{1k},\hat{\ell }_{2k}\right)$| can be constructed by using any ML methods or classical estimators, such as kernel or series estimators. For completeness, I present the Logit Lasso and Lasso estimators here.
3.2. Asymptotic properties
In this section, I show the theoretical properties of the DMLDiD estimator |$\tilde{\theta }$|. In particular, I will show that the estimator |$\tilde{\theta }$| can achieve |$\sqrt{N}$|-consistency and asymptotic normality as long as the first-step estimators converge at rates faster than N−1/4. This rate of convergence can be achieved by many ML methods, including Lasso and Logit Lasso.
The critical difference between DMLDiD and Abadie’s DiD estimator is the score functions on which they are based. The new score functions (3.1) and (3.2) have the directional (or the Gateaux) derivatives equal to zero with respect to their infinite-dimensional nuisance parameters, whereas the scores based on (2.1) and (2.2) do not have this property. This property is the so-called Neyman orthogonality in Chernozhukov et al. (2018).
The new score functions (3.1) and (3.2) obey the Neyman orthogonality.
The proof of this lemma can be found in the online appendix. In fact, it is also possible to derive the Neyman-orthogonal scores with respect to both finite- and infinite-dimensional nuisance parameters. However, the functional forms are much more complicated than the score functions (3.1) and (3.2), and this will make the corresponding estimator not as neat as the estimators proposed here. Because they will enjoy the same asymptotic properties, here I focus only on the estimators based on (3.1) and (3.2).
In the following, I will discuss the theoretical properties of the new estimator |$\tilde{\theta }$| when data belong to repeated outcomes and repeated cross sections. The results of multilevel treatment can be proved by using the same arguments. Let κ and C be strictly positive constants, K ≥ 2 be a fixed integer, and εN be a sequence of positive constants approaching zero. Denote by ∥ · ∥P, q the Lq norm of some probability measure P: ∥f∥P, q ≡ (∫∣f(w)∣qdP(w))1/q and |$\parallel f \parallel _{P,\infty } \equiv \sup _{w} \mid f\left(w\right) \mid$|.
Let P be the probability law for (Y(0), Y(1), D, X). Let D = g0(X) + U and Y(1) − Y(0) = ℓ10(X) + V1, with EP[U∣X] = 0 and EP[V1∣X, D = 0] = 0. Define G1p0 ≡ EP[∂pψ1(W, θ0, p0, η10)] and Σ10 ≡ EP[(ψ1(W, θ0, p0, η10) + G1p0(D − p0))2]. For the above definition, the following conditions hold: (a) Pr(κ ≤ g0(X) ≤ 1 − κ) = 1; (b) ∥UV1∥P, 4 ≤ C; (c) E[U2∣X] ≤ C; (d) |$E\left[V_{1}^{2}\mid X\right]\le C$|; (e) Σ10 > 0; and (f) given the auxiliary sample |$I_{k}^{c}$|, the estimator |$\hat{\eta }_{1k}=\left(\hat{g}_{k},\hat{\ell }_{1k}\right)$| obeys the following conditions. With probability 1 − o(1), |$\parallel \hat{\eta }_{1k}-\eta _{10}\parallel _{P,2}\le \varepsilon _{N}$|, |$\parallel \hat{g}_{k}-1/2\parallel _{P,\infty }\le 1/2-\kappa$|, and |$\parallel \hat{g}_{k}-g_{0}\parallel _{P,2}^{2}+\parallel \hat{g}_{k}-g_{0}\parallel _{P,2}\times \parallel \hat{\ell }_{1k}-\ell _{10}\parallel _{P,2}\le \left(\varepsilon _{N}\right)^{2}$|.
Let P be the probability law for (Y, T, D, X). Let D = g0(X) + U and (T − λ0)Y = ℓ20(X) + V2, with Ep[U∣X] = 0 and Ep[V2∣X, D = 0] = 0. Define G2p0 ≡ EP[∂pψ2(W, θ0, p0, λ0, η20)], G2λ0 ≡ EP[∂λψ2(W, θ0, p0, λ0, η20)], and Σ20 ≡ EP[(ψ1(W, θ0, p0, η10) + G2p0(D − p0) + G2λ0(T − λ0))2]. For the above definition, the following conditions hold: (a) Pr(κ ≤ g0(X) ≤ 1 − κ) = 1; (b) ∥UV2∥P, 4 ≤ C; (c) E[U2∣X] ≤ C; (d) |$E\left[V_{2}^{2}\mid X\right]\le C$|; (e) EP[Y2∣X] ≤ C; (f) ∣EP[YU]∣ ≤ C; (g) Σ20 > 0; and (h) given the auxiliary sample |$I_{k}^{c}$|, the estimator |$\hat{\eta }_{2k}=\left(\hat{g}_{k},\hat{\ell }_{2k}\right)$| obeys the following conditions. With probability 1 − o(1), |$\parallel \hat{\eta }_{2k}-\eta _{20}\parallel _{P,2}\le \varepsilon _{N}$|, |$\parallel \hat{g}_{k}-1/2\parallel _{P,\infty }\le 1/2-\kappa$|, and |$\parallel \hat{g}_{k}-g_{0}\parallel _{P,2}^{2}+\parallel \hat{g}_{k}-g_{0}\parallel _{P,2}\times \parallel \hat{\ell }_{2k}-\ell _{20}\parallel _{P,2}\le \left(\varepsilon _{N}\right)^{2}$|.
Theorem 3.1 shows that DMLDiD |$\tilde{\theta }$| can achieve |$\sqrt{N}$|-consistency and asymptotic normality if the first-step estimators of the infinite-dimensional nuisance parameters converge at a rate faster than N−1/4. This rate of convergence can be achieved by many ML methods. In particular, Van de Geer (2008) and Belloni et al. (2012) provided detailed conditions for Logit Lasso and the modified Lasso estimators to satisfy this rate of convergence. Theorem 3.2 provides consistent estimators for the asymptotic variance of |$\tilde{\theta }$|. The proofs of Theorem 3.1 and Theorem 3.2 can be found in the online appendix.
4. SIMULATION
In the online appendix, I conduct Monte Carlo simulations to shed some light on the finite-sample properties of the DiD estimator of Abadie (2005) and the DMLDiD estimator |$\tilde{\theta }$| in all three data structures: repeated outcomes, repeated cross sections, and multilevel treatment. For the first-step ML estimation, I generate high-dimensional data and estimate the propensity score by Logit Lasso, Support vector machine (SVM), regression tree, random forests, boosting, and neural nets. I use random forests with 500 regression trees to estimate the remaining infinite-dimensional nuisance parameters. I find that although Abadie’s DiD estimator suffers from the bias of a variety of ML methods, the DMLDiD estimator |$\tilde{\theta }$| can successfully correct the bias and is centred at the true value. Figure 2 shows the Monte Carlo simulation and the data-generating process for repeated outcomes. Other cases and details are provided in the online appendix.
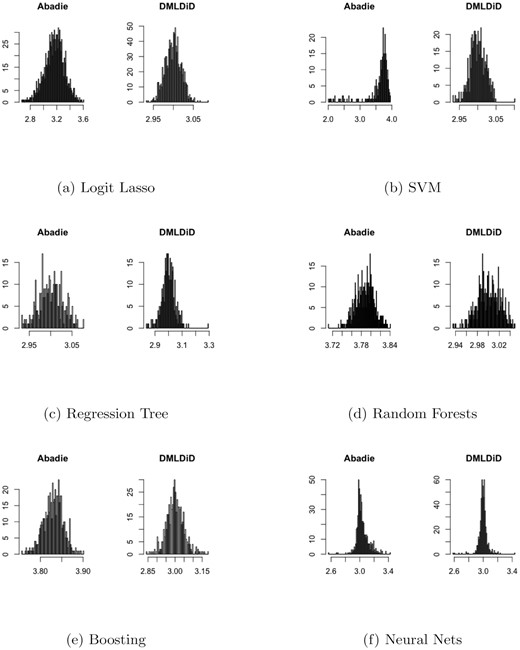
The simulation for repeated outcomes with the true value θ0 = 3.
The data-generating process for repeated outcomes: Let N = 200 be the sample size and p = 100 the dimension of control variables, Xi ∼ N(0, Ip × p). Let γ0 = (1, 1/2, 1/3, 1/4, 1/5, 0, |$...,0)\in \mathbb {R}^{p}$|, and Di is generated by the propensity score |$P(D=1\mid X)=\frac{1}{1+\exp (-X^{\prime }\gamma _{0})}.$| Also, let the potential outcomes be |$Y_{i}^{0}\left(0\right)=X_{i}^{\prime }\beta _{0}+\varepsilon _{1},$||$Y_{i}^{0}\left(1\right)=Y_{i}^{0}\left(0\right)+1+\varepsilon _{2},$| and |$Y_{i}^{1}\left(1\right)=\theta _{0}+Y_{i}^{0}\left(1\right)+\varepsilon _{3},$| where β0 = γ0 + 0.5 and θ0 = 3, and all error terms follow N(0, 0.1). Researchers observe {Yi(0), Yi(1), Di, Xi} for i = 1, ..., N, where |$Y_{i}\left(0\right)=Y_{i}^{0}\left(0\right)$| and |$Y_{i}\left(1\right)=Y_{i}^{0}\left(1\right)\left(1-D_{i}\right)+Y_{i}^{1}\left(1\right)D_{i}$|.
5. EMPIRICAL EXAMPLE
In this example, I analyse the effect of tariff reduction on corruption behaviors by using the bribe payment data collected by Sequeira (2016) between South Africa and Mozambique. There have been theoretical and empirical debates on whether higher tariff rates increase incentives for corruption (Clotfelter, 1983; Sequeira and Djankov, 2014) or lower tariffs encourage agents to pay higher bribes through an income effect (Feinstein, 1991; Slemrod and Yitzhaki, 2002). The former argues that an increase in the tariff rate makes it more profitable to evade taxes on the margin, whereas the latter asserts that an increased tariff rate makes the taxpayers less wealthy, and this, under the decreasing risk aversion of being penalised, tends to reduce evasion (Allingham and Sandmo, 1972).
Estimation results for (5.1) and (5.2).
| Equation (5.1) | Equation (5.2) | |
|---|---|---|
| |$\hat{\gamma }_{1}$| | −2.928** | 0.934 |
| (0.944) | (2.690) | |
| TP × diff | −0.986 | |
| (0.959) | ||
| TP × agri | −1.170** | |
| (0.580) | ||
| TP × lvalue | −0.098 | |
| (0.129) | ||
| TP × perishable | 0.859 | |
| (1.213) | ||
| TP × largefirm | −0.576 | |
| (0.988) | ||
| |$TP\times day\_arri$| | −0.002 | |
| (0.106) | ||
| TP × inspection | −0.525 | |
| (0.911) | ||
| TP × monitor | −0.482 | |
| (0.713) | ||
| TP × 2007tariff | 0.009 | |
| (0.048) | ||
| TP × SouthAfrica | −2.706*** | |
| (0.912) |
| Equation (5.1) | Equation (5.2) | |
|---|---|---|
| |$\hat{\gamma }_{1}$| | −2.928** | 0.934 |
| (0.944) | (2.690) | |
| TP × diff | −0.986 | |
| (0.959) | ||
| TP × agri | −1.170** | |
| (0.580) | ||
| TP × lvalue | −0.098 | |
| (0.129) | ||
| TP × perishable | 0.859 | |
| (1.213) | ||
| TP × largefirm | −0.576 | |
| (0.988) | ||
| |$TP\times day\_arri$| | −0.002 | |
| (0.106) | ||
| TP × inspection | −0.525 | |
| (0.911) | ||
| TP × monitor | −0.482 | |
| (0.713) | ||
| TP × 2007tariff | 0.009 | |
| (0.048) | ||
| TP × SouthAfrica | −2.706*** | |
| (0.912) |
Estimation results for (5.1) and (5.2).
| Equation (5.1) | Equation (5.2) | |
|---|---|---|
| |$\hat{\gamma }_{1}$| | −2.928** | 0.934 |
| (0.944) | (2.690) | |
| TP × diff | −0.986 | |
| (0.959) | ||
| TP × agri | −1.170** | |
| (0.580) | ||
| TP × lvalue | −0.098 | |
| (0.129) | ||
| TP × perishable | 0.859 | |
| (1.213) | ||
| TP × largefirm | −0.576 | |
| (0.988) | ||
| |$TP\times day\_arri$| | −0.002 | |
| (0.106) | ||
| TP × inspection | −0.525 | |
| (0.911) | ||
| TP × monitor | −0.482 | |
| (0.713) | ||
| TP × 2007tariff | 0.009 | |
| (0.048) | ||
| TP × SouthAfrica | −2.706*** | |
| (0.912) |
| Equation (5.1) | Equation (5.2) | |
|---|---|---|
| |$\hat{\gamma }_{1}$| | −2.928** | 0.934 |
| (0.944) | (2.690) | |
| TP × diff | −0.986 | |
| (0.959) | ||
| TP × agri | −1.170** | |
| (0.580) | ||
| TP × lvalue | −0.098 | |
| (0.129) | ||
| TP × perishable | 0.859 | |
| (1.213) | ||
| TP × largefirm | −0.576 | |
| (0.988) | ||
| |$TP\times day\_arri$| | −0.002 | |
| (0.106) | ||
| TP × inspection | −0.525 | |
| (0.911) | ||
| TP × monitor | −0.482 | |
| (0.713) | ||
| TP × 2007tariff | 0.009 | |
| (0.048) | ||
| TP × SouthAfrica | −2.706*** | |
| (0.912) |
Column 2 of Table 1 shows that (a) after controlling for the interaction terms, the estimate for γ1 becomes insignificantly different from zero, and (b) most of the coefficients of the interaction terms are negative. This suggests that there exists a large set of negative heterogeneous treatment effects and that Sequeira’s estimate may be a weighted average of these heterogeneous treatment effects. The negative coefficients of the interaction terms justify the sign of Sequeira’s estimate. However, it is ideal to treat the covariates nonparametrically when there exists heterogeneity in treatment effects, to avoid any potential inconsistency created by functional form misspecification (Abadie, 2005).
I estimate the ATT using both Abadie’s DiD estimator and DMLDiD. Because the data are repeated cross sections, I construct the estimators on the basis of (2.2) and (3.2), respectively. The estimators with first-step kernel estimation contain one individual characteristic (the natural log of shipment value per ton), which is the only significant and continuous control variable in Table 9 of Sequeira (2016). The estimators with first-step Lasso estimation contain a list of the covariates included in Table 9 of Sequeira (2016), which consists of the characteristics of product, shipment, firm, and border officials. I choose both the bandwidth kernel and penalty level of Lasso by 10-fold cross validations. Table 2 shows the estimation result. First, we can observe that the estimates with first-step kernel are much larger than the estimates with first-step Lasso. The reason may be that more control variables are included in the latter estimates. Second, though with the same sign, Abadie’s estimator (−8.168 or −6.432) is at least twice as large as previously reported by Sequeira (2016). This large effect, however, may be due to not only the robustness of semiparametric estimation on the functional form but also the finite-sample bias in the first-step nonparametric estimation. The DMLDiD estimator (−5.222) removes the first-order bias and suggests a smaller effect that is closer to Sequeira’s estimate. Its value is only 60% higher than Sequeira’s result. This extra effect can be explained by the misspecification of the traditional linear DiD estimator. Therefore, I obtain the same conclusion as Sequeira (2016) that tariff reduction decreases corruption, but my estimate suggests an even larger magnitude.
The results of semiparametric DiD estimation.
| Sequeira (2016) | Abadie (kernel) | DMLDiD (kernel) | Abadie (Lasso) | DMLDiD (Lasso) | |
|---|---|---|---|---|---|
| ATT | −2.928** | −8.168** | −6.998* | −6.432** | −5.222* |
| (0.944) | (3.072) | (3.752) | (2.737) | (2.647) |
| Sequeira (2016) | Abadie (kernel) | DMLDiD (kernel) | Abadie (Lasso) | DMLDiD (Lasso) | |
|---|---|---|---|---|---|
| ATT | −2.928** | −8.168** | −6.998* | −6.432** | −5.222* |
| (0.944) | (3.072) | (3.752) | (2.737) | (2.647) |
The results of semiparametric DiD estimation.
| Sequeira (2016) | Abadie (kernel) | DMLDiD (kernel) | Abadie (Lasso) | DMLDiD (Lasso) | |
|---|---|---|---|---|---|
| ATT | −2.928** | −8.168** | −6.998* | −6.432** | −5.222* |
| (0.944) | (3.072) | (3.752) | (2.737) | (2.647) |
| Sequeira (2016) | Abadie (kernel) | DMLDiD (kernel) | Abadie (Lasso) | DMLDiD (Lasso) | |
|---|---|---|---|---|---|
| ATT | −2.928** | −8.168** | −6.998* | −6.432** | −5.222* |
| (0.944) | (3.072) | (3.752) | (2.737) | (2.647) |
6. CONCLUSION
The DiD estimator survives as one of the most popular methods in the causal inference literature. A practical problem that empirical researchers face is the selection of important control variables when they confront a large number of candidate variables. Researchers may want to use ML methods to handle a rich set of control variables while taking the strength of the DiD estimator. I improve its original versions by proposing DMLDiD to allow researchers to use ML methods while still obtaining valid inferences. This additional benefit will make DiD more flexible for empirical researchers to explore a broader set of popular estimation methods and analyse more types of data sets.
Footnotes
The R codes can be found on my Github: https://github.com/NengChiehChang/Diff-in-Diff
REFERENCES
SUPPORTING INFORMATION
Additional Supporting Information may be found in the online version of this article at the publisher’s website.
Online Supplement
Replication package
Notes
Co-editor Victor Chernozhukov handled this manuscript.
APPENDIX A: MORE ON ESTIMATION
Multilevel treatments algorithm:
Take aK-foldrandom partition|$\left(I_{k}\right)_{k=1}^{K}$|of observation indices [N] = {1, ..., N}, such that the size of each foldIkisn = N/K. For eachk ∈ [K] = {1, ..., K}, define the auxiliary sample|$I_{k}^{c}\equiv \left\lbrace 1,...,N\right\rbrace \setminus I_{k}$|.
For eachk ∈ [K], construct the estimator ofp0and λ0by|$\hat{p}_{w}=\frac{1}{n}\sum _{i\in I_{k}^{c}}D_{i}$|. Also, construct the estimators ofgw, gz, and ℓ30by using the auxiliary sample|$I_{k}^{c}$|: |$\hat{g}_{wk}=\hat{g}_{w}\left(\left(W_{i}\right)_{i\in I_{k}^{c}}\right)$|, |$\hat{g}_{zk}=\hat{g}_{z}\left(\left(W_{i}\right)_{i\in I_{k}^{c}}\right)$|, and|$\hat{\ell }_{3k}=\hat{\ell }_{3}\left(\left(W_{i}\right)_{i\in I_{k}^{c}}\right)$|.
- For eachk, construct the intermediate ATT estimators:$$\begin{eqnarray} \tilde{\theta }_{wk}& =\frac{1}{n}\sum _{i\in I_{k}}\frac{I\left(W_{i}=w\right)\cdot \hat{g}_{zk}\left(X_{i}\right)-I\left(W_{i}=0\right)\cdot \hat{g}_{wk}\left(X_{i}\right)}{\hat{p}_{w}\hat{g}_{zk}\left(X_{i}\right)}\\ & \times \left(Y\left(1\right)-Y\left(0\right)-\hat{\ell }_{3k}\left(X_{i}\right)\right). \end{eqnarray}$$
Construct the final ATT estimators: |$\tilde{\theta }=\frac{1}{K}\sum _{k=1}^{K}\tilde{\theta }_{k}.$|

{kind=link}
{kind=link}