





Summary
The Rubin Causal Model (RCM) is a framework that allows to define the causal effect of an intervention as a contrast of potential outcomes. In recent years, several methods have been developed under the RCM to estimate causal effects in time series settings. None of these makes use of autoregressive integrated moving average (ARIMA) models, which are instead very common in the econometrics literature. In this paper, we propose a novel approach, named Causal-ARIMA (C-ARIMA), to define and estimate the causal effect of an intervention in observational time series settings under the RCM. We first formalise the assumptions enabling the definition, the estimation and the attribution of the effect to the intervention. We then check the validity of the proposed method with a simulation study. In the empirical application, we use C-ARIMA to assess the causal effect of a permanent price reduction on supermarket sales. The CausalArima R package provides an implementation of the proposed approach.
1. INTRODUCTION
The potential outcomes approach is a framework that allows to define the causal effect of a treatment (or ‘intervention’) as a contrast of potential outcomes, to discuss assumptions enabling to identify such causal effects from available data, as well as to develop methods for estimating causal effects under these assumptions (Rubin, 1974, 1975, 1978; Imbens and Rubin, 2015). Following Holland (1986), we refer to this framework as the Rubin Causal Model (RCM). Under the RCM, the causal effect of a treatment is defined as a contrast of potential outcomes, only one of which is observed while the others are missing and become counterfactuals once the treatment is assigned.
Having its roots in the context of randomised experiments, several methods have been developed to define and estimate causal effects under the RCM in the most diverse settings, including networks (VanderWeele, 2010; Forastiere et al., 2020; Noirjean et al., 2020), time series (Robins, 1986; Robins et al., 1999; Bojinov and Shephard, 2019) and panel data (Rambachan and Shephard, 2019; Bojinov et al., 2020).
Focusing on observational time series data, popular methods for policy evaluation under the RCM include Difference-in-Differences (DiD) and synthetic controls methods. However, both approaches require the presence of controls that did not experience the treatment and, in case of an extensive policy change impacting all units, finding untreated units is often challenging.
A different approach to assess the impact of shocks occurring on a time series is intervention analysis, introduced in Box and Tiao (1975) and Box and Tiao (1976). The effect is generally estimated by fitting an autoregressive integrated moving average (ARIMA) type model with the addition of an intervention component whose structure should capture the effect generated on the series (e.g., level shift, slope change and similar). For example, a simple model structure that is extensively used in literature is a linear regression with ARIMA errors (REG-ARIMA henceforth) and the addition of a level shift (e.g., Larcker et al., 1980; Worthington and Valadkhani, 2004; Schaffer et al., 2021). However, intervention analysis fails to define the causal estimands and to discuss the assumptions enabling the attribution of the uncovered effect to the intervention.
Closing the gap between causal inference under the RCM and intervention analysis, in this paper we propose a novel approach, Causal-ARIMA (C-ARIMA), to estimate the causal effect of an intervention in observational time series settings where no control unit is available. In particular, we discuss assumptions under the RCM to define, estimate and attribute the effect of the intervention in such settings; we then introduce the causal estimands of interest and derive a methodology to perform inference. Finally, we illustrate how the proposed approach can be conveniently applied to solve real inferential issues by estimating the causal effect of a permanent price reduction on supermarket sales. More specifically, on 4 October 2018 the branch of a supermarket chain located in Florence (Italy) introduced a new price policy that permanently lowered the price of several store brands. The main goal is estimating the effect of the new policy on the sales of those products, as well as its indirect impact on competitor brands with the same characteristics as the discounted goods. Our results suggest that store brands’ sales increased due to the permanent price discount; interestingly, we find little evidence of a detrimental effect on competitor brands, suggesting that unobserved factors may drive competitor-brand sales more than price.
The remainder of the paper is organised as follows: Section 2 surveys the literature; Section 3 presents the causal framework; Section 4 illustrates the proposed C-ARIMA approach; Section 5 reports the results of a simulation study; Section 6 describes the empirical findings; Section 7 concludes.
2. LITERATURE REVIEW
In time series settings, the identification and the estimation of causal effects using potential outcomes have been formalised in the context of randomised experiments, see, e.g., Bojinov and Shephard (2019), Rambachan and Shephard (2019) and Bojinov et al. (2020). However, observational studies pose additional challenges to the identification and estimation of causal effects: unlike randomised experiments, the assignment mechanism, i.e., the process that determines which units receive treatment and which receive control, is unknown; in addition, in the presence of a single series receiving the intervention, estimands like the ATE (average treatment effect) are not applicable, and sometimes it might be difficult to find suitable control series.
In economics, a prediction-based causal approach for time series data is Granger–Sims causality (Granger, 1969; Sims, 1972). Despite several differences with the potential outcome framework, some connections exist between the two approaches (Rambachan and Shephard, 2019). However, as shown in Lechner (2011), neither of these concepts implies the other without additional assumptions. In addition, Holland (1986) points out that a Granger-Sims cause may become a spurious association when new information is gathered and added in the predictive model.
DiD estimators (Card and Krueger, 1993; Angrist and Pischke, 2008; Anger et al., 2011) and synthetic control methods (Abadie and Gardeazabal, 2003; Abadie et al., 2010, 2015) have been used to evaluate the effect of interventions in the absence of experimental data in a wide range of fields, including economics (Billmeier and Nannicini, 2013; Botosaru and Ferman, 2019; Ben-Michael et al., 2021) and marketing (Brodersen et al., 2015; Li, 2019). Recent developments also include their combinations, as the Synthetic Difference-in-Differences (SDiD) estimator proposed in Arkhangelsky et al. (2019), and the strand of literature on heterogeneous treatment effects with staggered adoption and variation in timing (Callaway and Sant’Anna, 2021; Sun and Abraham, 2021; Athey and Imbens, 2022). In such settings the treatment time varies across units and they remain exposed to it at all times afterwards; thus, it is possible to estimate the effect of the intervention, even when all units are eventually treated by using, as a control group, the set of last-treated units or the set of not-yet-treated units.
Nevertheless, DiD estimators, synthetic control methods and their combinations usually require to observe at least one suitable control unit, which is often impractical. For example, in our application, appropriate control series could be the sales of products that are not impacted by the new policy. However, since the supermarket chain implemented an extensive price policy change addressing at least one product in each category, all products were impacted, directly or indirectly, by the intervention. In addition, all products received the intervention simultaneously, thereby precluding the adoption of the DiD estimators developed under variation in timing. Therefore, in our setting none of the methods mentioned above is applicable.
An approach overcoming these limitations is proposed by Brodersen et al. (2015), and only requires to learn the dynamics of the treated unit prior to the intervention. In particular, the authors employ Bayesian Structural Time Series models (Harvey, 1989; West and Harrison, 2006) to build a synthetic control by forecasting the counterfactual series in the absence of intervention based on a model estimated on the pre-intervention data. Borrowing the name from the associated R package, from now on we refer to their method as ‘CausalImpact’. A generalisation of this approach is proposed in Menchetti and Bojinov (2022), where the authors employ Multivariate Bayesian Structural Time Series models to assess the impact of an intervention on statistical units showing interactions with one another.
This work is most closely related to CausalImpact and to its multivariate extension in Menchetti and Bojinov (2022), since they both consider time series setups where suitable control units are absent. In the same vein as CausalImpact, our method exploits the time dynamics in the pre-intervention period to predict the series in the absence of intervention. Similarly to Menchetti and Bojinov (2022), in the application we deal with interfering units, but we handle the interference problem by considering all units to receive an active form of treatment. Furthermore, in contrast to CausalImpact and Menchetti and Bojinov (2022), our methodology is based on ARIMA models, and can be used as an alternative by researchers and practitioners in many fields that are not familiar to (or are not willing to adopt) Bayesian inference. In addition, ARIMA models have desirable properties (tractability, consistency of the estimator of model parameters), and are suited to describe a wide variety of time series generated by complex, non-stationary processes. They are also implemented in a large number of statistical software programs, which makes C-ARIMA very easy to use in practice. The associated CausalArima R package should further promote a wide adoption of the proposed approach.1
Therefore, C-ARIMA complements the set of tools for causal inference on observational time series data: it is tailored to estimate the effect of an intervention when no control series is available and when the number of pre-treatment periods is large, since it allows to fully exploit useful information provided by the pre-intervention dynamics; it is well suited in case of a single time series as well as for a simultaneous intervention on a large number of units (policy evaluation). Conversely, by focusing on a few time points, DiD estimators and synthetic controls have a limited ability to exploit long pre-treatment periods.2
Finally, C-ARIMA also shares many features with the approach described in Box and Tiao (1976), where the authors suggest to compare, at each point in time, the observed data after an intervention with the forecasts from a model fitted to the pre-intervention period. However, oftentimes researchers are interested in a cumulative sum of point effects, e.g., Papadogeorgou et al. (2018) focus on estimating the total number of hospital readmissions due to the Hospital Readmission Reduction Program over the entire post-intervention period. Therefore, we also provide test statistics for two additional effects: the cumulative and the temporal average effect. Most importantly, we frame our estimators in the potential outcome framework, defining the effects and discussing the assumptions enabling their attribution to the intervention: both Box and Tiao (1976) and canonical intervention analysis fail to do so, and thus it is unclear whether the effect estimated with such methods might also have a causal interpretation.
3. CAUSAL FRAMEWORK
On 4 October 2018 the Florence branch of an Italian supermarket chain introduced a new price policy that permanently lowered the price of 707 store brands in several product categories; the empirical analysis focuses on the goods belonging to the ‘cookies’ category. The supermarket chain also sells competitor-brand cookies with the same characteristics (e.g., ingredients, flavour, shape) as their store brand equivalent; starting from the intervention date, these products became more expensive compared to the store brands. As the price reduction ranges from |$-5.7\%$| to |$-23.2\%$|, we expect an heterogeneous effect on each product. The main goal of the analysis is then to assess the overall impact of the price policy, which is done by estimating its causal effect on the sales of both store and competitor-brand cookies.
In this section we present the notation and introduce some assumptions allowing the definition and the estimation of the causal effect, as well as its attribution to the intervention. We also discuss their validity in our empirical setting. Finally, we define the causal estimands we are interested in.
3.1. Assumptions
Let |$\operatorname{W}_{j,t} \in \lbrace 0,1\rbrace$| be a random variable describing the treatment assignment of unit |$j \in \mathcal {V} = \lbrace 1,\dots ,J\rbrace$| at time |$t \in \lbrace 1,\dots , T\rbrace$|, where 1 denotes that a ‘treatment’ (or ‘intervention’) has taken place and 0 denotes control. Lower case |$\operatorname{w}_{j,t}$| denotes a realisation of |$\operatorname{W}_{j,t}$|. In general, the treatment on unit j can be allocated (or not) at each time t, thereby generating a different sequence |$\operatorname{W}_{j,1:T} = ( \operatorname{W}_{j,1}, \dots , \operatorname{W}_{j,T})$| for each unit. Instead, we restrict our attention to a setting where all units are subject to a simultaneous and persistent intervention.3
We say that unit j received a single persistent intervention if there exists a|$t^{*}_j$|such that|$\operatorname{W}_{j,t} = 0$|for all|$t \in \lbrace 1, \dots , t^{*}_j \rbrace$|and for all|$t \in \lbrace t_j^{*} +1, \dots , T \rbrace$|the unit is either always treated, |$\operatorname{W}_{j,t} = 1$|, or always assigned to control, |$\operatorname{W}_{j,t} = 0$|. If the intervention happens simultaneously on all units, we denote with|$t^{*} = t^{*}_j$|the single intervention date.
Notice that, since the treatment is irreversible, |$\operatorname{W}_{j,t} = \operatorname{W}_{j,t^{\prime }}$| for all |$t,t^{\prime } \in \lbrace t^{*} +1, \dots , T \rbrace$|, thus we can drop the t subscript from the treatment variable. Both the permanent price reduction on store brands and the relative price increase on competitor brands are single persistent interventions, although the treatment definition differs for the two groups. More formally, let |$\mathcal {S} = \lbrace 1, \dots , J_s \rbrace$| and |$\mathcal {C} = \lbrace 1, \dots , J_c\rbrace$| denote the subsets of store and competitor brands, respectively; these are such that |$\mathcal {V} = \mathcal {S} \cup \mathcal {C}$| and |$J = J_s + J_c$|. Then, |$\operatorname{W}_{j} = 1$| for |$j \in \mathcal {S}$| indicates the ‘permanent price reduction’ of each store brand; while |$\operatorname{W}_{j} = 1$| for |$j \in \mathcal {C}$| stands for ‘relative price increase’, whose size also varies across competitor cookies as a result of the different reductions applied to store brands.
In the RCM, the sales that we would have under treatment or control are known as potential outcomes. Although in a panel study the potential outcomes of each unit generally depend on the other units’ assignment, in our empirical setting we can exclude cross-unit interactions within each group of store and competitor brands. Indeed, the cookies selected for the permanent price discount appeal to different customers, as they differ on many characteristics, such as shape, flavor and ingredients. We call this assumption temporal no-interference.4 As for the interactions between the two groups, we postulate that any spillover from store to competitor brands is well captured by the relative price increase (additional spillovers due to other promotional activities on store brands are ruled out), and that competitor brands are not subject to other interventions. Furthermore, we assume that the intervention has no anticipatory effects on the outcome. This is plausible when the statistical units have no knowledge of the future intervention (see also Bojinov and Shephard, 2019; Callaway and Sant’Anna, 2021; Sun and Abraham, 2021), which is also the case of our application, since the supermarket chain did not advertise the price reduction in advance.
Therefore, under the previously discussed assumptions, we can use |$\operatorname{Y}_{j,t}(\operatorname{w}_j)$| to denote the potential outcomes time series of unit j at time t. Indeed, unit j’s potential outcomes depend solely on its assignment |$\operatorname{w}_j$|. In addition, recall that there are only two potential paths for each unit in the post-intervention period, i.e., |$\operatorname{w}_j = 1$| or |$\operatorname{w}_j = 0$|. These give rise to the same number of potential outcomes, but we can only observe one of them for each unit. In our case, the observed potential outcome series is |$\operatorname{Y}_{j,t}(1)$| for all units and all |$t\in \lbrace t^{*}+1, \dots , T \rbrace$|, whereas |$\operatorname{Y}_{j,t}(0)$| is the missing or counterfactual potential outcome time series which is unobserved and needs to be estimated.
Including covariates that are linked to the outcome can improve the estimation of |$\operatorname{Y}_{j,t}(0)$|, but if the covariates are influenced by the treatment the estimates will be biased. We therefore make the following assumption.
Let|$\operatorname{X}_{j,t}$|be a vector of covariates that are predictive of the outcome of unit j; for all|$t \in \lbrace t^{*}+1,\dots ,T \rbrace$|such covariates are not affected by the intervention, i.e., |$\operatorname{X}_{j,t}(1) = \operatorname{X}_{j,t}(0)$|.
As a result, we can use the known covariates values to improve the prediction of the outcome in the absence of intervention |$\operatorname{Y}_{j,t}(0)$|. As detailed in Section 6, the set of covariates in the application includes a holiday dummy, some day-of-the-week dummies and the price per unit. While it is quite obvious that all the dummies are unaffected by the intervention, things get trickier for price. For the analysis on competitor brands we used their actual price, since it is not directly affected by the intervention (only their relative price is altered by the policy); conversely, for the analysis on store brands, we assumed that the price would not have changed without the intervention.5
Finally, following Antonelli and Beck (2020), we use the next assumption for identification of the treatment effect.
In other words, the conditional distribution of the outcome in the absence of treatment is invariant to time translations of one lag; thus, if we had perfect knowledge of the conditional distribution of |$\operatorname{Y}_{j,t}(0)$| in the pre-intervention period, we would also know its conditional distribution in the post-intervention period. In the empirical practice, the model fitted prior to intervention approximates our knowledge of this distribution before |$t^{*}$| and, under Assumption 3.3; we can rely on that knowledge to estimate the counterfactual outcome in the post-intervention period. Therefore, this assumption allows us to identify the effect from available data (the identification proof is provided in Appendix A).
It is worth pointing out that any analysis attempting to convey a causal message should be explicit on the assumptions needed to define and estimate causal effects. Furthermore, such assumptions depend on the empirical setting. For example, in case of a single unit (no panel dimension) the assumption of no-temporal interference is unnecessary; and in the absence of relevant covariates there is no need to include Assumption 3.2. Thus, before any causal analysis, researchers need to carefully formulate the set of assumptions and discuss their validity in the specific empirical setting.
3.2. Causal estimands
We now introduce three related causal estimands: the point effect (an instantaneous effect at each point in time after the intervention), the cumulative effect (a partial sum of the point effects) and the temporal average effect (the average of the point effects in a given time period).
In other words, the point effect measures the causal effect at a specific point in time and can be defined at every |$t \in \lbrace t^{*}+1, \dots , t^{*}+K\rbrace$|, thereby originating a vector of causal effects. The cumulative effect is then obtained by summing the point effects up to a predefined time point. For example, in our application, the cumulative effect would be the total number of cookies sold due to the permanent price reduction from the day when the new policy became effective until the end of the analysis period. Finally, the temporal average effect indicates the number of cookies sold daily, on average, due to the permanent price reduction.6
As described in Bojinov et al. (2020), in a panel setting we can also explore a cross-sectional average point effect, which averages the unit-specific point effects across units. In our case, it would be the average sales across the cookies in each group at a given time.
In line with Definition 3.1; we could also define a cross-sectional cumulative effect and a cross-sectional temporal average effect, e.g., for the group of store brands |$\Delta _{t^{*}+k}^{(\mathcal {S})} = \sum _{h = 1}^{k} \tau _{t^{*}+h}^{(\mathcal {S})}(1;0)$| and |$\bar{\tau }_{t^{*}+k}^{(\mathcal {S})}(1;0) = \Delta _{t^{*}+k}^{(\mathcal {S})}/k$|. In the next section, we introduce the C-ARIMA model and we describe how it can be used to estimate the causal quantities of interest.
4. C-ARIMA
We propose a causal version of the widely used ARIMA model, which we indicate as C-ARIMA. After introducing the model equation, we briefly discuss how causal effects under the RCM differ from general intervention components. Then, we present estimators for the estimands defined in Section 3.2 and describe our inferential strategy. Finally, we provide a theoretical comparison with REG-ARIMA, so as to highlight the major differences between the proposed approach and a widely adopted method in the intervention analysis literature. From now on we drop the j subscript from the notation of the potential outcomes and the causal effects, since under the assumptions set out in Section 3 we can focus on a single generic unit.
4.1. Model
As it will be clear in Section 4.2, our model is estimated on the pre-intervention data, thus in the C-ARIMA approach we do not need to find the structure that better represents the effect of the intervention (e.g., additive outlier, transient change, innovation outlier). Conversely, such effect emerges as a contrast of potential outcomes in the post-intervention period and the proposed approach allows us to estimate |$\tau _t(1;0)$| whatever structure it has.
4.2. Causal effect inference in the stationary case
Based on the C-ARIMA model, we can now detail inference on |$\tau _t(1;0) = \tau _t$| and the other causal estimands defined in Section 3.2 (for sake of simplicity, we remove the |$(1;0)$| label from now on).
Let|$\lbrace \operatorname{Y}^\dagger _t(\operatorname{w})\rbrace$|follow the model (4.2), equivalently represented in matrix form as by (4.9)–(4.10). Let|$\beta$|, |$\vartheta$|, and|$\sigma ^{2}_{\varepsilon }$|be estimated consistently by the usual Maximum Likelihood estimators|$\widehat{\beta }$|, |$\widehat{\vartheta }$|, and|$\widehat{\sigma }^{2}_{\varepsilon }$|using estimation data (label 1), which, in turn, implies similar properties for estimators|$\widehat{\sigma }^{2}_{z}$|and|$\widehat{R}$|of the corresponding elements.
Some comments are in order.
Equations (4.12)–(4.13) show that the random behaviour of |$\widehat{\tau }^\dagger$| depends on different components: |$z_2^\dagger$| is the intrinsic randomness of the post-intervention period; |$-R_{21} R_{11}^{-1} z_1^\dagger$| is the ARMA ‘inertia’ (ARMA predictions on period 2 using estimation data); |$-X^\dagger _{2} (X^{\dagger \prime }_{1} R_{11}^{-1} X^\dagger _{1} )^{-1} X^{\dagger \prime }_{1} R_{11}^{-1} z^\dagger _1$| is the contribution of the covariates of the post-intervention period; |$R_{21} R_{11}^{-1} X^\dagger _{1} (X^{\dagger \prime }_{1} R_{11}^{-1} X^\dagger _{1} )^{-1} X^{\dagger \prime }_{1} R_{11}^{-1} z^\dagger _1$| is the contribution of the covariates of the estimation period, which are propagated to period 2 by the ARMA dynamics.
Regarding the distribution of |$\widehat{\tau }^\dagger$|, there are two possible strategies. If one trusts in the Normality of the ARIMA error term |$\varepsilon$|, also |$z^\dagger$| and then |$\widehat{\tau }^\dagger$| are Gaussian. Otherwise, it is possible to resort to a bootstrap strategy, where randomly sampled empirical residuals (|$\varepsilon$|) are used to simulate the ARIMA errors (|$z^\dagger$|) via the estimated |$\widehat{\vartheta }$| parameters.
The single |$\widehat{\tau }^\dagger _{t^{*}+k}$| estimator corresponds to the kth element of (4.12); the single |$\widehat{\Delta }^\dagger _{t^{*}+k}$| estimator is instead the linear combination (unit weights) of the first k elements of (4.12). Thus, its variance can be derived directly from (4.14). The same reasoning applies for the variance of |$\widehat{\bar{\tau }}_{t^{*}+k}^\dagger$|.
4.3. Causal effect inference in the non-stationary case
Let|$\lbrace \operatorname{Y}_t(\operatorname{w}) \rbrace$|follow model (4.1).
4.4. Estimation and inference of causal effects under C-ARIMA
Summarising, in order to estimate the causal effects (3.1), (3.2) and (3.3), we need to follow a three-step process: (i) estimate the ARIMA model only in the pre-intervention period, so as to learn the dynamics of the dependent variable and the links with the covariates without being influenced by the treatment; (ii) based on the process learned in the pre-intervention period, perform a prediction step and obtain an estimate of the counterfactual outcome during the post-intervention period in the absence of intervention; (iii) by comparing the observations with the corresponding forecasts at any time point in the post-intervention period, evaluate the resulting differences, which represent the estimated point causal effects. Then, we have two options to perform inference on the estimated effects: if we rely in the Normality of the error terms (possibly, after an inspection of model residuals) we can use the results presented in Theorem 4.1; otherwise, we can resort to a bootstrap strategy by using resampled residuals in order to compute empirical critical values (the detailed algorithm is provided in the Online Appendix). Finally, in case we used differencing operators to make the process stationary, we can recover the effect on the original variable by applying the results presented in Theorem 4.2.
4.5. Comparison with REG-ARIMA
There are three main differences between C-ARIMA and REG-ARIMA. First, REG-ARIMA is estimated using the entire time series of observed data (it does not introduce potential outcomes). This implies that without discussing any assumption, the effect grasped by |$\beta _D$| cannot be attributed to the intervention. For example, it might be biased by the inclusion of a regressor linked to the treatment, or even be the anticipated result of a future intervention. Second, REG-ARIMA can only capture effects in the form of level shifts and, more generally, intervention analysis requires to repeat model estimation until the assumed structure on the intervention component is supported by data. Conversely, C-ARIMA assumes no structure on |$\tau _t$| and, as such, it can capture any form of effects (level shift, slope change, irregular time-varying effects) in only one step. Finally, |$\beta _D$| is the only effect that we can estimate under REG-ARIMA and, by construction, it averages across the whole post-intervention period; instead, with C-ARIMA we can define and estimate an average effect, but also the point effect, thereby appreciating the evolution of the causal effect in time.
Next section reports a simulation study where we compare the empirical performance of both approaches (C-ARIMA and REG-ARIMA) in inferring causal effects. We remark, however, that the comparison is purely practical, since the theoretical limitations of REG-ARIMA do not allow the attribution of such effects to the intervention.
5. SIMULATION
We generated 2,000 replications from an ARIMA|$(1,0,1)(1,0,1)_7$| model, then we added two types of effects: (i) a level shift of four different magnitudes, i.e., |$+0\%$| (absence of effect), |$+10\%$|, |$+25\%$|, |$+50\%$|; (ii) two irregular, time-varying effects that fade after a while to increase again near the end of the analysis period (IRR 1 and IRR 2). Figure 1 provides a graphical representation of the level shift and the irregular interventions for one of the simulated time series. Notice that IRR 1 is designed such that the effect is negative after three months from the intervention and zero at the end of the analysis period. Instead, the effect under IRR 2 is always positive, except when it is exactly zero at the 3-month horizon.
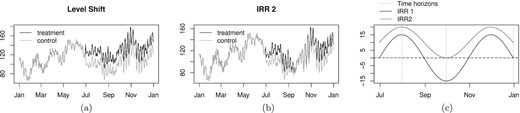
(a) Level shift of +25% for one simulated series; (b) irregular effect (IRR 2); (c) pattern of the irregular effects during all the post-intervention period (those at 1, 3 and 6-month horizons are highlighted in the plot).
In line with the theory presented in Section 4, we tested C-ARIMA and REG-ARIMA in detecting these effects, comparing the performance of both approaches in terms of three indicators: (i) the probability of rejecting the null hypothesis of absence of effect when it is true (type I error probability); (ii) the probability of correctly rejecting the null hypothesis when it is false (power); (iii) computational time. We also tested whether the two approaches would give different results based on the model used in the pre-intervention period (the true model used to generate the data versus the best-fitting model based on the Bayesian Information Criterion) and the time horizon used for valuation (1 month, 3 months and 6 months after the fictional intervention producing the effects).
Table 1 shows the results of simulations in terms of power. Unsurprisingly, REG-ARIMA outperforms C-ARIMA when the effect is a level shift; indeed, the former model is specifically designed for interventions in this form. However, REG-ARIMA fails to detect the negative effect under IRR 1, and incorrectly reject the null of absence of effect at the second time horizon under IRR 2. Conversely, C-ARIMA performs well when the effect is irregular, and does a reasonably good job in case of level shifts compared to benchmark REG-ARIMA, especially when the impact size increases. The simulation results also show that the type I error probability of both approaches is in line with the desired threshold (|$\alpha = 0.05$|) and that C-ARIMA is computationally more efficient than REG-ARIMA. Further comments and additional results are reported in the Online Appendix. Overall, the simulation results indicate that C-ARIMA performs well when the true effect takes the form of a level shift; furthermore, it outperforms the standard REG-ARIMA approach in the estimation of irregular, time-varying effects.
Power of the test based on |$\widehat{\tau }^\dagger _t$| (for C-ARIMA) and |$\widehat{\beta }_D$| (for REG-ARIMA).
| C-ARIMA, |$\tau ^\dagger _t$| | REG-ARIMA, |$\beta _D$| | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TRUE | BIC | TRUE | BIC | ||||||||||
| 1 m | 3 m | 6 m | 1 m | 3 m | 6 m | 1 m | 3 m | 6 m | 1 m | 3 m | 6 m | ||
| IRR 1 | 0.480 | 0.477 | 0.060 | 0.482 | 0.478 | 0.059 | 0.052 | 0.058 | 0.053 | 0.054 | 0.062 | 0.051 | |
| IRR 2 | 0.724 | 0.058 | 0.242 | 0.726 | 0.056 | 0.242 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |
| |$+10\%$| | 0.243 | 0.248 | 0.242 | 0.243 | 0.250 | 0.242 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |
| |$+25\%$| | 0.895 | 0.887 | 0.879 | 0.895 | 0.887 | 0.879 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |
| |$+50\%$| | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |
| C-ARIMA, |$\tau ^\dagger _t$| | REG-ARIMA, |$\beta _D$| | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TRUE | BIC | TRUE | BIC | ||||||||||
| 1 m | 3 m | 6 m | 1 m | 3 m | 6 m | 1 m | 3 m | 6 m | 1 m | 3 m | 6 m | ||
| IRR 1 | 0.480 | 0.477 | 0.060 | 0.482 | 0.478 | 0.059 | 0.052 | 0.058 | 0.053 | 0.054 | 0.062 | 0.051 | |
| IRR 2 | 0.724 | 0.058 | 0.242 | 0.726 | 0.056 | 0.242 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |
| |$+10\%$| | 0.243 | 0.248 | 0.242 | 0.243 | 0.250 | 0.242 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |
| |$+25\%$| | 0.895 | 0.887 | 0.879 | 0.895 | 0.887 | 0.879 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |
| |$+50\%$| | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |
Notes: The numbers in bold highlight when the power function significantly deviates from what is expected (see Figure 1 panel (c)). The results are reported for both the true model (|$TRUE$|) and the best-fitting model (|$BIC$|) at three time horizons: 1 month (1m), 3 months (3m) and 6 months (6m) from the intervention. The different impact sizes ranging from |$+10\%$| to |$+50\%$| in the rows denote estimated effects in the form of level shifts, whereas IRR 1 and IRR 2 indicate the irregular effects.
Power of the test based on |$\widehat{\tau }^\dagger _t$| (for C-ARIMA) and |$\widehat{\beta }_D$| (for REG-ARIMA).
| C-ARIMA, |$\tau ^\dagger _t$| | REG-ARIMA, |$\beta _D$| | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TRUE | BIC | TRUE | BIC | ||||||||||
| 1 m | 3 m | 6 m | 1 m | 3 m | 6 m | 1 m | 3 m | 6 m | 1 m | 3 m | 6 m | ||
| IRR 1 | 0.480 | 0.477 | 0.060 | 0.482 | 0.478 | 0.059 | 0.052 | 0.058 | 0.053 | 0.054 | 0.062 | 0.051 | |
| IRR 2 | 0.724 | 0.058 | 0.242 | 0.726 | 0.056 | 0.242 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |
| |$+10\%$| | 0.243 | 0.248 | 0.242 | 0.243 | 0.250 | 0.242 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |
| |$+25\%$| | 0.895 | 0.887 | 0.879 | 0.895 | 0.887 | 0.879 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |
| |$+50\%$| | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |
| C-ARIMA, |$\tau ^\dagger _t$| | REG-ARIMA, |$\beta _D$| | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TRUE | BIC | TRUE | BIC | ||||||||||
| 1 m | 3 m | 6 m | 1 m | 3 m | 6 m | 1 m | 3 m | 6 m | 1 m | 3 m | 6 m | ||
| IRR 1 | 0.480 | 0.477 | 0.060 | 0.482 | 0.478 | 0.059 | 0.052 | 0.058 | 0.053 | 0.054 | 0.062 | 0.051 | |
| IRR 2 | 0.724 | 0.058 | 0.242 | 0.726 | 0.056 | 0.242 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |
| |$+10\%$| | 0.243 | 0.248 | 0.242 | 0.243 | 0.250 | 0.242 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |
| |$+25\%$| | 0.895 | 0.887 | 0.879 | 0.895 | 0.887 | 0.879 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |
| |$+50\%$| | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |
Notes: The numbers in bold highlight when the power function significantly deviates from what is expected (see Figure 1 panel (c)). The results are reported for both the true model (|$TRUE$|) and the best-fitting model (|$BIC$|) at three time horizons: 1 month (1m), 3 months (3m) and 6 months (6m) from the intervention. The different impact sizes ranging from |$+10\%$| to |$+50\%$| in the rows denote estimated effects in the form of level shifts, whereas IRR 1 and IRR 2 indicate the irregular effects.
6. EMPIRICAL APPLICATION
In this section we describe the results of our empirical application; the goal is to estimate the impact of the permanent price reduction performed by an Italian supermarket chain.
6.1. Data and methodology
Data consists of daily sales counts of 11 store brands and their corresponding competitor-brand cookies in the period 1 September 2017–30 April 2019 (Anonymous firm, 2019).11 The permanent price reduction on the store-brand cookies was introduced by the supermarket chain on 4 October 2018. As an example, Figure 2 shows the time series of units sold, the evolution of price per unit and the autocorrelation function of one store brand and its direct competitor. The plots for the remaining store-brand and competitor-brand cookies are provided in the Online Appendix. The occasional price drops before the intervention date indicate temporary promotions run regularly by the supermarket chain. The products exhibit a clear weekly seasonal pattern, evidenced by the spikes in the autocorrelation functions. In the panel referred to the direct competitor brand, we can also observe the evolution of the relative price per unit (the ratio between the prices of the competitor brand and the corresponding store brand). Unsurprisingly, despite the occasional drops due to temporary promotions, the price of the competitor brand relative to the corresponding store brand has increased after the intervention.
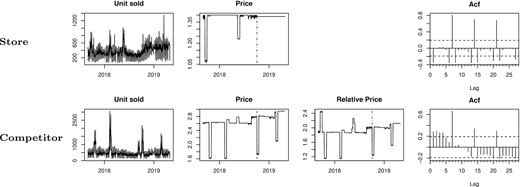
Daily time series of unit sold, price per unit and autocorrelation function for two selected items.
To estimate the causal effect of the permanent price discount on the sales of store-brand cookies, we follow the approach outlined in Section 4. In particular, under the assumptions set out in Section 3, we can analyse each cookie separately, thereby fitting 11 independent models. In order to improve model diagnostics, the dependent variable is the natural log of the daily sales count. This also means that we are postulating the existence of a multiplicative effect of the new price policy on the sales of cookies. Therefore, we focused our attention on estimating the temporal average causal effect, which can still be interpreted as an average multiplicative effect in terms of the original variable. Furthermore, we included covariates to improve prediction of the missing potential outcomes in the absence of intervention. As ruled by Assumption 3.2; all the considered regressors can be safely assumed to be unaffected by the intervention. In particular, to take care of the seasonality we included six dummy variables corresponding to the day of the week and one dummy denoting December Sundays.12 Indeed, the policy of the supermarket chain implies that all shops are closed on Sunday afternoon, except during Christmas holidays. Thus, we may have two opposite ‘Sunday effects’: a positive effect in December, when the shops are open all day; a negative effect during the rest of the year, since all shops are closed in the afternoon. We also included a holiday dummy taking value 1 before and after a national holiday and 0 otherwise. This is to account for consumers’ tendency to increase purchases before and after a closure day.13 Finally, we included a modified version of the unit price, that after the intervention day and during all the post-period is taken equal to the last price before the permanent discount. As explained in the discussion of Assumption 3.2; this is the most likely price that the unit would have had in the absence of intervention. In addition, to estimate the average causal effect of the intervention on store brands, we are also interested in evaluating how this effect evolves with time. Thus, we repeated the analysis by making predictions at three different time horizons: 1 month, 3 months and 6 months after the intervention.
The same methodology is applied to the competitor brands, with a slight modification on the set of covariates. Indeed, this time the unit price is not directly influenced by the intervention, which instead affects the relative price (as shown in Figure 2); so, to forecast competitor sales in the absence of intervention we directly used the actual price.
The results obtained from C-ARIMA are then compared to those of REG-ARIMA. More specifically, we fitted independent linear regressions with ARIMA errors for each of the 11 store brands and their competitors.
6.2. Results and discussion
Table 2 shows the results of the C-ARIMA and the REG-ARIMA approaches applied to the store brands. To provide a more direct comparison with REG-ARIMA, the C-ARIMA results reported here have been derived under the assumption that the error terms are normally distributed. Residuals diagnostics and Normal QQ-plots seem to support this assumption for some of the items (see Figures S5 and S9 in the Online Appendix). In addition, the results based on bootstrapped residuals are in line with those shown in this section for both store and competitor brands (see Tables S6 and S8 in the Online Appendix). Figure 3 illustrates the causal effect, the observed time series and the forecasted series in the absence of intervention for one selected item (additional plots are provided in the Online Appendix). At the 1-month time horizon, the causal effect is significantly positive at the |$5\%$| level for 5 out of 11 items; three months after the intervention, the causal effect is significantly positive at the same level for 8 items; after six months, the effect is significant and positive for 10 items. The analysis performed with REG-ARIMA leads to similar results, except for the effects on items 1 and 2 at the 3-month horizon. This suggests that the intervention might have produced a level shift in the outcome level. To have a summary figure for the impact produced by the permanent price reduction on all store brands, we also estimated the cross-sectional temporal average effect as defined in (3.4). This is positive and significant at all time horizons, indicating that the intervention was, on average, effective in increasing store-brand sales.

Forecasted sales and pattern of point effect on store brand 4 at 1 month horizon.
Causal effect estimates of the permanent price reduction on store brands.
| Time horizon: | ||||||
|---|---|---|---|---|---|---|
| 1 month | 3 months | 6 months | ||||
| Item | |$\widehat{\bar{\tau }}^\dagger _t$| | |$\widehat{\beta }_D$| | |$\widehat{\bar{\tau }}^\dagger _t$| | |$\widehat{\beta }_D$| | |$\widehat{\bar{\tau }}^\dagger _t$| | |$\widehat{\beta }_D$| |
| 1 | 0.14 | 0.09 | 0.15. | 0.11 | 0.18** | 0.16** |
| (0.13) | (0.10) | (0.09) | (0.07) | (0.07) | (0.06) | |
| 2 | 0.14 | 0.11 | 0.13 | 0.13* | 0.14* | 0.14*** |
| (0.12) | (0.10) | (0.09) | (0.06) | (0.07) | (0.04) | |
| 3 | 0.19. | 0.15. | 0.21* | 0.18*** | 0.25*** | 0.24*** |
| (0.11) | (0.08) | (0.08) | (0.05) | (0.06) | (0.04) | |
| 4 | 0.49*** | 0.32*** | 0.30*** | 0.22** | 0.32*** | 0.27*** |
| (0.10) | (0.09) | (0.07) | (0.07) | (0.05) | (0.06) | |
| 5 | |$-$|0.02 | |$-$|0.05 | 0.07 | 0.01 | 0.11 | 0.07 |
| (0.13) | (0.09) | (0.10) | (0.07) | (0.07) | (0.05) | |
| 6 | 0.24. | 0.25** | 0.34*** | 0.30*** | 0.37*** | 0.35*** |
| (0.12) | (0.09) | (0.09) | (0.07) | (0.07) | (0.05) | |
| 7 | 0.55*** | 0.57*** | 0.34*** | 0.49*** | 0.30*** | 0.35*** |
| (0.11) | (0.04) | (0.08) | (0.09) | (0.06) | (0.04) | |
| 8 | 0.26** | 0.33*** | 0.25*** | 0.25*** | 0.14* | 0.18** |
| (0.08) | (0.07) | (0.07) | (0.07) | (0.06) | (0.06) | |
| 9 | 0.47*** | 0.56*** | 0.20*** | 0.28*** | 0.21*** | 0.26*** |
| (0.07) | (0.07) | (0.05) | (0.08) | (0.04) | (0.06) | |
| 10 | 0.66*** | 0.82*** | 0.57*** | 0.58*** | 0.33*** | 0.36*** |
| (0.12) | (0.12) | (0.10) | (0.05) | (0.08) | (0.06) | |
| 11 | 0.12. | 0.11* | 0.16* | 0.14*** | 0.14** | 0.13*** |
| (0.06) | (0.05) | (0.06) | (0.03) | (0.05) | (0.03) | |
| |$\widehat{\bar{\tau }}^{(\mathcal {S}) \dagger }_t$| | 0.29** | 0.25** | 0.23*** | |||
| (0.11) | (0.08) | (0.06) | ||||
| Time horizon: | ||||||
|---|---|---|---|---|---|---|
| 1 month | 3 months | 6 months | ||||
| Item | |$\widehat{\bar{\tau }}^\dagger _t$| | |$\widehat{\beta }_D$| | |$\widehat{\bar{\tau }}^\dagger _t$| | |$\widehat{\beta }_D$| | |$\widehat{\bar{\tau }}^\dagger _t$| | |$\widehat{\beta }_D$| |
| 1 | 0.14 | 0.09 | 0.15. | 0.11 | 0.18** | 0.16** |
| (0.13) | (0.10) | (0.09) | (0.07) | (0.07) | (0.06) | |
| 2 | 0.14 | 0.11 | 0.13 | 0.13* | 0.14* | 0.14*** |
| (0.12) | (0.10) | (0.09) | (0.06) | (0.07) | (0.04) | |
| 3 | 0.19. | 0.15. | 0.21* | 0.18*** | 0.25*** | 0.24*** |
| (0.11) | (0.08) | (0.08) | (0.05) | (0.06) | (0.04) | |
| 4 | 0.49*** | 0.32*** | 0.30*** | 0.22** | 0.32*** | 0.27*** |
| (0.10) | (0.09) | (0.07) | (0.07) | (0.05) | (0.06) | |
| 5 | |$-$|0.02 | |$-$|0.05 | 0.07 | 0.01 | 0.11 | 0.07 |
| (0.13) | (0.09) | (0.10) | (0.07) | (0.07) | (0.05) | |
| 6 | 0.24. | 0.25** | 0.34*** | 0.30*** | 0.37*** | 0.35*** |
| (0.12) | (0.09) | (0.09) | (0.07) | (0.07) | (0.05) | |
| 7 | 0.55*** | 0.57*** | 0.34*** | 0.49*** | 0.30*** | 0.35*** |
| (0.11) | (0.04) | (0.08) | (0.09) | (0.06) | (0.04) | |
| 8 | 0.26** | 0.33*** | 0.25*** | 0.25*** | 0.14* | 0.18** |
| (0.08) | (0.07) | (0.07) | (0.07) | (0.06) | (0.06) | |
| 9 | 0.47*** | 0.56*** | 0.20*** | 0.28*** | 0.21*** | 0.26*** |
| (0.07) | (0.07) | (0.05) | (0.08) | (0.04) | (0.06) | |
| 10 | 0.66*** | 0.82*** | 0.57*** | 0.58*** | 0.33*** | 0.36*** |
| (0.12) | (0.12) | (0.10) | (0.05) | (0.08) | (0.06) | |
| 11 | 0.12. | 0.11* | 0.16* | 0.14*** | 0.14** | 0.13*** |
| (0.06) | (0.05) | (0.06) | (0.03) | (0.05) | (0.03) | |
| |$\widehat{\bar{\tau }}^{(\mathcal {S}) \dagger }_t$| | 0.29** | 0.25** | 0.23*** | |||
| (0.11) | (0.08) | (0.06) | ||||
Notes:|$^{\boldsymbol{\cdot }}$|p|$\lt $|0.1; |$^{*}$|p|$\lt $|0.05; |$^{**}$|p|$\lt $|0.01; |$^{***}$|p|$\lt $|0.001. The estimates are reported for three different time horizons: 1 month, 3 months and 6 months from the intervention. In this table, |$\widehat{\bar{\tau }}^\dagger _t$| is the estimated temporal average effect (in all models d = D = 0, therefore this is the effect on the original variable and |$\widehat{\bar{\tau }}^\dagger _t = 0$| implies no effect); |$\widehat{\bar{\tau }}^{(\mathcal {S}) \dagger }_t$| is the temporal average effect aggregated across all items; |$\widehat{\beta }_D$| is the coefficient estimate of the intervention dummy according to REG-ARIMA (|$\widehat{\beta }_D = 0$| implies absence of association). Standard errors within parentheses.
Causal effect estimates of the permanent price reduction on store brands.
| Time horizon: | ||||||
|---|---|---|---|---|---|---|
| 1 month | 3 months | 6 months | ||||
| Item | |$\widehat{\bar{\tau }}^\dagger _t$| | |$\widehat{\beta }_D$| | |$\widehat{\bar{\tau }}^\dagger _t$| | |$\widehat{\beta }_D$| | |$\widehat{\bar{\tau }}^\dagger _t$| | |$\widehat{\beta }_D$| |
| 1 | 0.14 | 0.09 | 0.15. | 0.11 | 0.18** | 0.16** |
| (0.13) | (0.10) | (0.09) | (0.07) | (0.07) | (0.06) | |
| 2 | 0.14 | 0.11 | 0.13 | 0.13* | 0.14* | 0.14*** |
| (0.12) | (0.10) | (0.09) | (0.06) | (0.07) | (0.04) | |
| 3 | 0.19. | 0.15. | 0.21* | 0.18*** | 0.25*** | 0.24*** |
| (0.11) | (0.08) | (0.08) | (0.05) | (0.06) | (0.04) | |
| 4 | 0.49*** | 0.32*** | 0.30*** | 0.22** | 0.32*** | 0.27*** |
| (0.10) | (0.09) | (0.07) | (0.07) | (0.05) | (0.06) | |
| 5 | |$-$|0.02 | |$-$|0.05 | 0.07 | 0.01 | 0.11 | 0.07 |
| (0.13) | (0.09) | (0.10) | (0.07) | (0.07) | (0.05) | |
| 6 | 0.24. | 0.25** | 0.34*** | 0.30*** | 0.37*** | 0.35*** |
| (0.12) | (0.09) | (0.09) | (0.07) | (0.07) | (0.05) | |
| 7 | 0.55*** | 0.57*** | 0.34*** | 0.49*** | 0.30*** | 0.35*** |
| (0.11) | (0.04) | (0.08) | (0.09) | (0.06) | (0.04) | |
| 8 | 0.26** | 0.33*** | 0.25*** | 0.25*** | 0.14* | 0.18** |
| (0.08) | (0.07) | (0.07) | (0.07) | (0.06) | (0.06) | |
| 9 | 0.47*** | 0.56*** | 0.20*** | 0.28*** | 0.21*** | 0.26*** |
| (0.07) | (0.07) | (0.05) | (0.08) | (0.04) | (0.06) | |
| 10 | 0.66*** | 0.82*** | 0.57*** | 0.58*** | 0.33*** | 0.36*** |
| (0.12) | (0.12) | (0.10) | (0.05) | (0.08) | (0.06) | |
| 11 | 0.12. | 0.11* | 0.16* | 0.14*** | 0.14** | 0.13*** |
| (0.06) | (0.05) | (0.06) | (0.03) | (0.05) | (0.03) | |
| |$\widehat{\bar{\tau }}^{(\mathcal {S}) \dagger }_t$| | 0.29** | 0.25** | 0.23*** | |||
| (0.11) | (0.08) | (0.06) | ||||
| Time horizon: | ||||||
|---|---|---|---|---|---|---|
| 1 month | 3 months | 6 months | ||||
| Item | |$\widehat{\bar{\tau }}^\dagger _t$| | |$\widehat{\beta }_D$| | |$\widehat{\bar{\tau }}^\dagger _t$| | |$\widehat{\beta }_D$| | |$\widehat{\bar{\tau }}^\dagger _t$| | |$\widehat{\beta }_D$| |
| 1 | 0.14 | 0.09 | 0.15. | 0.11 | 0.18** | 0.16** |
| (0.13) | (0.10) | (0.09) | (0.07) | (0.07) | (0.06) | |
| 2 | 0.14 | 0.11 | 0.13 | 0.13* | 0.14* | 0.14*** |
| (0.12) | (0.10) | (0.09) | (0.06) | (0.07) | (0.04) | |
| 3 | 0.19. | 0.15. | 0.21* | 0.18*** | 0.25*** | 0.24*** |
| (0.11) | (0.08) | (0.08) | (0.05) | (0.06) | (0.04) | |
| 4 | 0.49*** | 0.32*** | 0.30*** | 0.22** | 0.32*** | 0.27*** |
| (0.10) | (0.09) | (0.07) | (0.07) | (0.05) | (0.06) | |
| 5 | |$-$|0.02 | |$-$|0.05 | 0.07 | 0.01 | 0.11 | 0.07 |
| (0.13) | (0.09) | (0.10) | (0.07) | (0.07) | (0.05) | |
| 6 | 0.24. | 0.25** | 0.34*** | 0.30*** | 0.37*** | 0.35*** |
| (0.12) | (0.09) | (0.09) | (0.07) | (0.07) | (0.05) | |
| 7 | 0.55*** | 0.57*** | 0.34*** | 0.49*** | 0.30*** | 0.35*** |
| (0.11) | (0.04) | (0.08) | (0.09) | (0.06) | (0.04) | |
| 8 | 0.26** | 0.33*** | 0.25*** | 0.25*** | 0.14* | 0.18** |
| (0.08) | (0.07) | (0.07) | (0.07) | (0.06) | (0.06) | |
| 9 | 0.47*** | 0.56*** | 0.20*** | 0.28*** | 0.21*** | 0.26*** |
| (0.07) | (0.07) | (0.05) | (0.08) | (0.04) | (0.06) | |
| 10 | 0.66*** | 0.82*** | 0.57*** | 0.58*** | 0.33*** | 0.36*** |
| (0.12) | (0.12) | (0.10) | (0.05) | (0.08) | (0.06) | |
| 11 | 0.12. | 0.11* | 0.16* | 0.14*** | 0.14** | 0.13*** |
| (0.06) | (0.05) | (0.06) | (0.03) | (0.05) | (0.03) | |
| |$\widehat{\bar{\tau }}^{(\mathcal {S}) \dagger }_t$| | 0.29** | 0.25** | 0.23*** | |||
| (0.11) | (0.08) | (0.06) | ||||
Notes:|$^{\boldsymbol{\cdot }}$|p|$\lt $|0.1; |$^{*}$|p|$\lt $|0.05; |$^{**}$|p|$\lt $|0.01; |$^{***}$|p|$\lt $|0.001. The estimates are reported for three different time horizons: 1 month, 3 months and 6 months from the intervention. In this table, |$\widehat{\bar{\tau }}^\dagger _t$| is the estimated temporal average effect (in all models d = D = 0, therefore this is the effect on the original variable and |$\widehat{\bar{\tau }}^\dagger _t = 0$| implies no effect); |$\widehat{\bar{\tau }}^{(\mathcal {S}) \dagger }_t$| is the temporal average effect aggregated across all items; |$\widehat{\beta }_D$| is the coefficient estimate of the intervention dummy according to REG-ARIMA (|$\widehat{\beta }_D = 0$| implies absence of association). Standard errors within parentheses.
Table 3 reports the results for the competitor brands and Figure 4 plots the causal effect, the observed series and the forecasted series for one selected item. Again, the causal effect seems to strengthen as we proceed far away from the intervention.At a 1-month horizon no significant effect is observed; three months after the intervention, on item 10 we find a negative effect and significant at the |$5\%$| level; at a 6-month horizon we find a significant negative effects on item 10 and a significant positive effect on item 5. A negative effect suggests that, following the permanent price discount, consumers have changed their behaviour by privileging the cheaper store brand. Instead, a positive effect might indicate that the price policy has determined an increase in the customer base, i.e., new clients have entered the shop and eventually bought the items at full price. This time, REG-ARIMA leads to different results: at the 6-month horizon, positive effects are found on items 6 and 7, and a negative effect is detected on item 8. This suggests that whatever impact was captured by the intervention dummy of REG-ARIMA, this was not due to the relative price increase experienced by competitor brands. Overall, our analysis on the cross-sectional temporal average effect indicates that competitor brands were mostly unaffected by the intervention applied on store brands.

Forecasted sales and pattern of point effect on competitor brand 10 at 1 month horizon.
Causal effect estimates of the permanent price reduction on competitor brands.
| Time horizon: | ||||||
|---|---|---|---|---|---|---|
| 1 month | 3 months | 6 months | ||||
| Item | |$\widehat{\bar{\tau }}^\dagger _t$| | |$\widehat{\beta }_D$| | |$\widehat{\bar{\tau }}^\dagger _t$| | |$\widehat{\beta }_D$| | |$\widehat{\bar{\tau }}^\dagger _t$| | |$\widehat{\beta }_D$| |
| 1 | |$-$|0.04 | |$-$|0.03 | 0.02 | |$-$|0.16 | 0.04 | |$-$|0.12 |
| (0.57) | (0.21) | (0.52) | (0.25) | (0.42) | (0.22) | |
| 2 | |$-$|0.13 | |$-$|0.17 | |$-$|0.07 | |$-$|0.13 | |$-$|0.15 | |$-$|0.13 |
| (0.52) | (0.21) | (0.52) | (0.20) | (0.45) | (0.19) | |
| 3 | 0.04 | |$-$|0.06 | 0.09 | |$-$|0.03 | 0.17 | 0.01 |
| (0.42) | (0.22) | (0.32) | (0.20) | (0.21) | (0.17) | |
| 4 | 0.00 | 0.04 | |$-$|0.13 | |$-$|0.03 | |$-$|0.04 | 0.01 |
| (0.31) | (0.19) | (0.23) | (0.16) | (0.18) | (0.13) | |
| 5 | |$-$|0.03 | |$-$|0.02 | 0.05 | 0.06 | 0.12* | 0.12** |
| (0.11) | (0.06) | (0.07) | (0.06) | (0.05) | (0.05) | |
| 6 | |$-$|0.05 | |$-$|0.01 | 0.03 | 0.06 | 0.09 | 0.10* |
| (0.13) | (0.10) | (0.11) | (0.06) | (0.09) | (0.05) | |
| 7 | 0.04 | |$-$|0.11 | 0.11 | |$-$|0.05 | 0.40 | 0.39*** |
| (0.57) | (0.29) | (0.38) | (0.26) | (0.29) | (0.08) | |
| 8 | |$-$|0.09 | |$-$|0.09 | |$-$|0.06 | −0.07. | |$-$|0.08 | −0.10** |
| (0.08) | (0.06) | (0.06) | (0.04) | (0.05) | (0.04) | |
| 9 | |$-$|0.09 | |$-$|0.09 | |$-$|0.11 | |$-$|0.11 | |$-$|0.10 | |$-$|0.09 |
| (0.14) | (0.10) | (0.10) | (0.08) | (0.08) | (0.06) | |
| 10 | |$-$|0.03 | |$-$|0.02 | −0.12* | −0.09* | −0.11* | −0.08* |
| (0.06) | (0.05) | (0.05) | (0.04) | (0.04) | (0.04) | |
| |$\widehat{\bar{\tau }}^{(\mathcal {C}) \dagger }_t$| | |$-$|0.04 | |$-$|0.02 | 0.04 | |||
| (0.35) | (0.30) | (0.24) | ||||
| Time horizon: | ||||||
|---|---|---|---|---|---|---|
| 1 month | 3 months | 6 months | ||||
| Item | |$\widehat{\bar{\tau }}^\dagger _t$| | |$\widehat{\beta }_D$| | |$\widehat{\bar{\tau }}^\dagger _t$| | |$\widehat{\beta }_D$| | |$\widehat{\bar{\tau }}^\dagger _t$| | |$\widehat{\beta }_D$| |
| 1 | |$-$|0.04 | |$-$|0.03 | 0.02 | |$-$|0.16 | 0.04 | |$-$|0.12 |
| (0.57) | (0.21) | (0.52) | (0.25) | (0.42) | (0.22) | |
| 2 | |$-$|0.13 | |$-$|0.17 | |$-$|0.07 | |$-$|0.13 | |$-$|0.15 | |$-$|0.13 |
| (0.52) | (0.21) | (0.52) | (0.20) | (0.45) | (0.19) | |
| 3 | 0.04 | |$-$|0.06 | 0.09 | |$-$|0.03 | 0.17 | 0.01 |
| (0.42) | (0.22) | (0.32) | (0.20) | (0.21) | (0.17) | |
| 4 | 0.00 | 0.04 | |$-$|0.13 | |$-$|0.03 | |$-$|0.04 | 0.01 |
| (0.31) | (0.19) | (0.23) | (0.16) | (0.18) | (0.13) | |
| 5 | |$-$|0.03 | |$-$|0.02 | 0.05 | 0.06 | 0.12* | 0.12** |
| (0.11) | (0.06) | (0.07) | (0.06) | (0.05) | (0.05) | |
| 6 | |$-$|0.05 | |$-$|0.01 | 0.03 | 0.06 | 0.09 | 0.10* |
| (0.13) | (0.10) | (0.11) | (0.06) | (0.09) | (0.05) | |
| 7 | 0.04 | |$-$|0.11 | 0.11 | |$-$|0.05 | 0.40 | 0.39*** |
| (0.57) | (0.29) | (0.38) | (0.26) | (0.29) | (0.08) | |
| 8 | |$-$|0.09 | |$-$|0.09 | |$-$|0.06 | −0.07. | |$-$|0.08 | −0.10** |
| (0.08) | (0.06) | (0.06) | (0.04) | (0.05) | (0.04) | |
| 9 | |$-$|0.09 | |$-$|0.09 | |$-$|0.11 | |$-$|0.11 | |$-$|0.10 | |$-$|0.09 |
| (0.14) | (0.10) | (0.10) | (0.08) | (0.08) | (0.06) | |
| 10 | |$-$|0.03 | |$-$|0.02 | −0.12* | −0.09* | −0.11* | −0.08* |
| (0.06) | (0.05) | (0.05) | (0.04) | (0.04) | (0.04) | |
| |$\widehat{\bar{\tau }}^{(\mathcal {C}) \dagger }_t$| | |$-$|0.04 | |$-$|0.02 | 0.04 | |||
| (0.35) | (0.30) | (0.24) | ||||
Notes:|$^{\boldsymbol{\cdot }}$|p|$\lt $|0.1; |$^{*}$|p|$\lt $|0.05; |$^{**}$|p|$\lt $|0.01; |$^{***}$|p|$\lt $|0.001. The estimates are reported for three different time horizons: 1 month, 3 months and 6 months from the intervention. In this table, |$\widehat{\bar{\tau }}^\dagger _t$| is the estimated temporal average effect on the original variable (in all models d = D = 0, therefore this is the effect on the original variable and |$\widehat{\bar{\tau }}^\dagger _t = 0$| implies no effect); |$\widehat{\bar{\tau }}^{(\mathcal {C}) \dagger }_t$| is the temporal average effect aggregated across all items; |$\widehat{\beta }_D$| is the coefficient estimate of the intervention dummy according to REG-ARIMA (|$\widehat{\beta }_D = 0$| implies absence of association). Standard errors within parentheses.
Causal effect estimates of the permanent price reduction on competitor brands.
| Time horizon: | ||||||
|---|---|---|---|---|---|---|
| 1 month | 3 months | 6 months | ||||
| Item | |$\widehat{\bar{\tau }}^\dagger _t$| | |$\widehat{\beta }_D$| | |$\widehat{\bar{\tau }}^\dagger _t$| | |$\widehat{\beta }_D$| | |$\widehat{\bar{\tau }}^\dagger _t$| | |$\widehat{\beta }_D$| |
| 1 | |$-$|0.04 | |$-$|0.03 | 0.02 | |$-$|0.16 | 0.04 | |$-$|0.12 |
| (0.57) | (0.21) | (0.52) | (0.25) | (0.42) | (0.22) | |
| 2 | |$-$|0.13 | |$-$|0.17 | |$-$|0.07 | |$-$|0.13 | |$-$|0.15 | |$-$|0.13 |
| (0.52) | (0.21) | (0.52) | (0.20) | (0.45) | (0.19) | |
| 3 | 0.04 | |$-$|0.06 | 0.09 | |$-$|0.03 | 0.17 | 0.01 |
| (0.42) | (0.22) | (0.32) | (0.20) | (0.21) | (0.17) | |
| 4 | 0.00 | 0.04 | |$-$|0.13 | |$-$|0.03 | |$-$|0.04 | 0.01 |
| (0.31) | (0.19) | (0.23) | (0.16) | (0.18) | (0.13) | |
| 5 | |$-$|0.03 | |$-$|0.02 | 0.05 | 0.06 | 0.12* | 0.12** |
| (0.11) | (0.06) | (0.07) | (0.06) | (0.05) | (0.05) | |
| 6 | |$-$|0.05 | |$-$|0.01 | 0.03 | 0.06 | 0.09 | 0.10* |
| (0.13) | (0.10) | (0.11) | (0.06) | (0.09) | (0.05) | |
| 7 | 0.04 | |$-$|0.11 | 0.11 | |$-$|0.05 | 0.40 | 0.39*** |
| (0.57) | (0.29) | (0.38) | (0.26) | (0.29) | (0.08) | |
| 8 | |$-$|0.09 | |$-$|0.09 | |$-$|0.06 | −0.07. | |$-$|0.08 | −0.10** |
| (0.08) | (0.06) | (0.06) | (0.04) | (0.05) | (0.04) | |
| 9 | |$-$|0.09 | |$-$|0.09 | |$-$|0.11 | |$-$|0.11 | |$-$|0.10 | |$-$|0.09 |
| (0.14) | (0.10) | (0.10) | (0.08) | (0.08) | (0.06) | |
| 10 | |$-$|0.03 | |$-$|0.02 | −0.12* | −0.09* | −0.11* | −0.08* |
| (0.06) | (0.05) | (0.05) | (0.04) | (0.04) | (0.04) | |
| |$\widehat{\bar{\tau }}^{(\mathcal {C}) \dagger }_t$| | |$-$|0.04 | |$-$|0.02 | 0.04 | |||
| (0.35) | (0.30) | (0.24) | ||||
| Time horizon: | ||||||
|---|---|---|---|---|---|---|
| 1 month | 3 months | 6 months | ||||
| Item | |$\widehat{\bar{\tau }}^\dagger _t$| | |$\widehat{\beta }_D$| | |$\widehat{\bar{\tau }}^\dagger _t$| | |$\widehat{\beta }_D$| | |$\widehat{\bar{\tau }}^\dagger _t$| | |$\widehat{\beta }_D$| |
| 1 | |$-$|0.04 | |$-$|0.03 | 0.02 | |$-$|0.16 | 0.04 | |$-$|0.12 |
| (0.57) | (0.21) | (0.52) | (0.25) | (0.42) | (0.22) | |
| 2 | |$-$|0.13 | |$-$|0.17 | |$-$|0.07 | |$-$|0.13 | |$-$|0.15 | |$-$|0.13 |
| (0.52) | (0.21) | (0.52) | (0.20) | (0.45) | (0.19) | |
| 3 | 0.04 | |$-$|0.06 | 0.09 | |$-$|0.03 | 0.17 | 0.01 |
| (0.42) | (0.22) | (0.32) | (0.20) | (0.21) | (0.17) | |
| 4 | 0.00 | 0.04 | |$-$|0.13 | |$-$|0.03 | |$-$|0.04 | 0.01 |
| (0.31) | (0.19) | (0.23) | (0.16) | (0.18) | (0.13) | |
| 5 | |$-$|0.03 | |$-$|0.02 | 0.05 | 0.06 | 0.12* | 0.12** |
| (0.11) | (0.06) | (0.07) | (0.06) | (0.05) | (0.05) | |
| 6 | |$-$|0.05 | |$-$|0.01 | 0.03 | 0.06 | 0.09 | 0.10* |
| (0.13) | (0.10) | (0.11) | (0.06) | (0.09) | (0.05) | |
| 7 | 0.04 | |$-$|0.11 | 0.11 | |$-$|0.05 | 0.40 | 0.39*** |
| (0.57) | (0.29) | (0.38) | (0.26) | (0.29) | (0.08) | |
| 8 | |$-$|0.09 | |$-$|0.09 | |$-$|0.06 | −0.07. | |$-$|0.08 | −0.10** |
| (0.08) | (0.06) | (0.06) | (0.04) | (0.05) | (0.04) | |
| 9 | |$-$|0.09 | |$-$|0.09 | |$-$|0.11 | |$-$|0.11 | |$-$|0.10 | |$-$|0.09 |
| (0.14) | (0.10) | (0.10) | (0.08) | (0.08) | (0.06) | |
| 10 | |$-$|0.03 | |$-$|0.02 | −0.12* | −0.09* | −0.11* | −0.08* |
| (0.06) | (0.05) | (0.05) | (0.04) | (0.04) | (0.04) | |
| |$\widehat{\bar{\tau }}^{(\mathcal {C}) \dagger }_t$| | |$-$|0.04 | |$-$|0.02 | 0.04 | |||
| (0.35) | (0.30) | (0.24) | ||||
Notes:|$^{\boldsymbol{\cdot }}$|p|$\lt $|0.1; |$^{*}$|p|$\lt $|0.05; |$^{**}$|p|$\lt $|0.01; |$^{***}$|p|$\lt $|0.001. The estimates are reported for three different time horizons: 1 month, 3 months and 6 months from the intervention. In this table, |$\widehat{\bar{\tau }}^\dagger _t$| is the estimated temporal average effect on the original variable (in all models d = D = 0, therefore this is the effect on the original variable and |$\widehat{\bar{\tau }}^\dagger _t = 0$| implies no effect); |$\widehat{\bar{\tau }}^{(\mathcal {C}) \dagger }_t$| is the temporal average effect aggregated across all items; |$\widehat{\beta }_D$| is the coefficient estimate of the intervention dummy according to REG-ARIMA (|$\widehat{\beta }_D = 0$| implies absence of association). Standard errors within parentheses.
Summarising, the intervention seems to have produced a significant and positive effect on the sales of store-brand cookies. Conversely, we do not find considerable evidence of a detrimental effect on competitor cookies (the only exception being item 10). This indicates that, even though each store-competitor pair is formed by perfect substitutes, price might not be the only factor driving sales. For example, unobserved factors such as individual preferences or brand faithfulness may have a role as well.
7. CONCLUDING REMARKS
We propose a novel approach under the RCM to estimate the effect of interventions in observational time series settings in the absence of untreated units. After a detailed illustration of the assumptions underneath our causal framework, we defined three causal estimands of interest, i.e., the point, cumulative and average causal effects. Then, we introduced a methodology to perform inference. We applied the proposed methodology to estimate the causal effect of the new price policy introduced by a big supermarket chain in Italy, which addressed a selected subset of store-brand products by permanently lowering their price. The empirical analysis was carried out on the goods belonging to the ‘cookies’ category: the results show that the permanent price reduction was effective in increasing store-brand cookies’ sales. Little evidence of a detrimental effect on the corresponding competitor-brand cookies is found.
FUNDING
The authors thank the Department of Excellence 2018-2022 funding provided by the Italian Ministry of University and Research (MUR). The authors also thank the Statistics Department of the University of Florence (DiSIA) and the Florence Center for Data Science.
Footnotes
The development version of the CausalArima R package can be accessed from https://github.com/FMenchetti/CausalArima.
A notable exception is the method proposed by Chernozhukov et al. (2019), although it requires to observe many control units, and thus it is not applicable in our setting. Related to this, it is worth mentioning that DiD estimators, synthetic control methods and their combinations can be a better choice than C-ARIMA and CausaImpact in case of few pre-treatment periods and multiple treated and control units.
The supermarket chain sometimes run temporary promotions reducing the price of selected goods for a limited period of time. The time interval after the permanent price discount spans from 4 October 2018 to 30 April 2019, and in the corresponding period before the intervention (4 October 2017 to 30 April 2018) there were no temporary promotions on the store brands that are part of this analysis. Thus, the assumption of a constant price level in the period following the intervention is plausible.
Notice that the point effect is analogous to the general causal effect defined in Bojinov and Shephard (2019), with the difference that our estimand is referred to a special setting were the units are subject to a single persistent treatment.
Notice that (4.1) can be written in this form because we are assuming absence of within-group interference and absence of additional spillovers, which imply that the potential outcomes of each unit j only depends on its assignment. Conversely, in case these assumptions are not plausible, (4.1) would need to be restated, e.g., by considering a multivariate model. We are also exploiting Assumption 3.1; since we have a single |$\tau _t(1;0)$| in the model equation.
The information set at time |$t^{*}$| includes both |$\operatorname{Y}_1(0), \dots , \operatorname{Y}_{t^{*}}(0)$| and |$\operatorname{X}_1, \dots , \operatorname{X}_{t^{*}}$|. Instead, recall that in the post-intervention period we are under Assumption 3.2; meaning that covariates are unaffected by the treatment. Thus, we can consider them as deterministic, which explains why we can take |$\operatorname{X}_{t^{*}+k}^\dagger$| outside the expectation in (4.5).
The situation where the ARIMA component of the model is a Random Walk (RW) provides a glaring example of this. In fact,
Since
We excluded the last competitor brand because |$62 \%$| of observations were missing. Thus, we analysed |$J_s = 11$| store and |$J_c = 10$| competitor brands, for a total of |$J = 21$| cookies.
We may have a monthly seasonal pattern on top of the weekly cycle, but the reduced length of the pre-intervention series (398 observations) does not allow to assess whether a double seasonality is present.
To be precise, on the day of a national holiday we have a missing value (so there is no holiday effect), whereas the dummy variable should capture the effect of additional purchases before and after the closure day(s).
REFERENCES
Supporting Information
Additional Supporting Information may be found in the online version of this article at the publisher’s website:
Online Appendix
Replication Package
Notes
Co-editor Dennis Kristensen handled this manuscript.
APPENDIX A: PROOFS OF RESULTS
Proof of Theorem 4.1

{kind=link}
{kind=link}
{kind=link}
{kind=link}