





Abstract
The limited memory steepest descent method (LMSD) proposed by Fletcher is an extension of the Barzilai–Borwein ‘two-point step size’ strategy for steepest descent methods for solving unconstrained optimization problems. It is known that the Barzilai–Borwein strategy yields a method with an |$R$|-linear rate of convergence when it is employed to minimize a strongly convex quadratic. This article extends this analysis for LMSD, also for strongly convex quadratics. In particular, it is shown that, under reasonable assumptions, the method is |$R$|-linearly convergent for any choice of the history length parameter. The results of numerical experiments are also provided to illustrate behaviors of the method that are revealed through the theoretical analysis.
1. Introduction
For solving unconstrained nonlinear optimization problems, one of the simplest and most widely used techniques is steepest descent (SD). This refers to any strategy in which, from any solution estimate, a productive step is obtained by moving some distance along the negative gradient of the objective function, i.e., the direction along which function descent is steepest.
While SD methods have been studied for over a century and employed in numerical software for decades, a unique and powerful instance came about relatively recently in the work by Barzilai & Borwein (1988), where a ‘two-point step size’ strategy is proposed and analysed. The resulting SD method, commonly referred to as the BB method, represents an effective alternative to other SD methods that employ an exact or inexact line search when computing the step size in each iteration.
The theoretical properties of the BB method are now well-known when it is employed to minimize an |$n$|-dimensional strongly convex quadratic objective function. Such objective functions are interesting in their own right, but one can argue that such analyses also characterize the behavior of the method in the neighborhood of a strong local minimizer for any smooth objective function. In the original work (i.e., Barzilai & Borwein, 1988), it is shown that the method converges |$R$|-superlinearly when |$n=2$|. In Raydan (1993), it is shown that the method converges from any starting point for any natural number |$n$|, and in Dai & Liao (2002), it is shown that the method converges |$R$|-linearly for any such |$n$|.
In each iteration of the BB method, the step size is determined by a computation involving the displacement in the gradient of the objective observed between the current iterate and the previous iterate. As shown in Fletcher (2012), this idea can be extended to a limited memory steepest descent (LMSD) method in which a sequence of |$m$| step sizes is computed using the displacements in the gradient over the previous |$m$| steps. This extension can be motivated by the observation that these displacements lie in a Krylov subspace determined by a gradient previously computed in the algorithm, which in turn yields a computationally efficient strategy for computing |$m$| distinct eigenvalue estimates of the Hessian (i.e., matrix of second derivatives) of the objective function. The reciprocals of these eigenvalue estimates represent reasonable step size choices. Indeed, if the eigenvalues are computed exactly, then the algorithm terminates in a finite number of iterations; e.g., see Lai (1981), Fletcher (2012) and Section 2.
In Fletcher (2012), it is shown that the proposed LMSD method converges from any starting point when it is employed to minimize a strongly convex quadratic function. However, to the best of our knowledge, the convergence rate of the method for |$m > 1$| has not yet been analysed. The main purpose of this article is to show that, under reasonable assumptions, this LMSD method converges |$R$|-linearly when employed to minimize such a function. Our analysis builds upon the analyses in Fletcher (2012) and Dai & Liao (2002).
We mention at the outset that numerical evidence has shown that the practical performance of the BB method is typically much better than known convergence proofs suggest; in particular, the empirical rate of convergence is often |$Q$|-linear with a contraction constant that is better than that observed for a basic SD method. Based on such evidence, we do not claim that the convergence results proved in this article fully capture the practical behavior of LMSD methods. To explore this claim, we present the results of numerical experiments that illustrate our convergence theory, and demonstrate that the practical performance of LMSD can be even better than the theory suggests. We conclude with a discussion of possible explanations of why this is the case for LMSD, in particular, by referencing a known finite termination result for a special (computationally expensive) variant of the algorithm.
Organization
In Section 2, we formally state the problem of interest, notation to be used throughout the article, Fletcher’s LMSD algorithm and a finite termination property for it. In Section 3, we prove that the LMSD algorithm is |$R$|-linearly convergent for any history length. The theoretical results proved in Section 3 are demonstrated numerically in Section 4 and concluding remarks are presented in Section 5.
Notation
The set of real numbers (i.e., scalars) is denoted as |$ {\mathbb{R}}{}$|, the set of non-negative real numbers is denoted as |${\mathbb{R}}{}_+$|, the set of positive real numbers is denoted as |${\mathbb{R}}{}_{++}$| and the set of natural numbers is denoted as |${\mathbb{N}}{} := \{1,2,\dots\}$|. A natural number as a superscript is used to denote the vector-valued extension of any of these sets—e.g., the set of |$n$|-dimensional real vectors is denoted as |${\mathbb{R}}{n}$|—and a Cartesian product of natural numbers as a superscript is used to denote the matrix-valued extension of any of these sets—e.g., the set of |$n \times n$| real matrices is denoted as |${\mathbb{R}}{n\times n}$|. A finite sequence of consecutive positive integers of the form |$\{1,\dots,n\} \subset {\mathbb{N}}{}$| is denoted using the shorthand |$[n]$|. Subscripts are used to refer to a specific element of a sequence of quantities, either fixed or generated by an algorithm. For any vector |$v \in {\mathbb{R}}{n}$|, its Euclidean (i.e., |$\ell_2$|) norm is denoted by |$\|v\|$|.
Fundamentals
In this section, we state the optimization problem of interest along with corresponding definitions and concepts to which we will refer throughout the remainder of the article. We then state Fletcher’s LMSD algorithm and prove a finite termination property for it, as is done in Lai (1981) and Fletcher (2012).
2.1 Problem statement
Formally, we make the following assumption about the problem data.
The eigendecomposition of |$A$| defined in Assumption 2.1 plays a crucial role in our analysis. In particular, we will make extensive use of the fact that any gradient of the objective function computed in the algorithm, a vector in |${\mathbb{R}}{n}$|, can be written as a linear combination of the columns of the orthogonal matrix |$Q$|. This will allow us to analyse the behavior of the algorithm componentwise according to the weights in these linear combinations corresponding to the sequence of computed objective gradients. Such a strategy has been employed in all of the aforementioned articles on BB and LMSD.
LMSD method
Fletcher’s LMSD method is stated as Algorithm LMSD. The iterate update in the algorithm is the standard update in an SD method: each subsequent iterate is obtained from the current iterate minus a multiple of the gradient of the objective function evaluated at the current iterate. With this update at its core, Algorithm LMSD operates in cycles. At |$x_{k,1} \in {\mathbb{R}}{n}$| representing the initial point of the |$k$|th cycle, a sequence of |$m$| positive step sizes |$\{\alpha_{k,j}\}_{j\in[m]}$| are selected to be employed in an inner cycle composed of |$m$| updates, the result of which is set as the initial point for cycle |$k+1$|.
However, this is less efficient than using (2.8) due to the need to store |$Q_k$| and, since the QR factorization of |$G_k$| requires |$\sim\!\!m^2 n$| flops, as opposed to the |$\sim\!\!\frac{1}{2} m^2 n$| flops required for (2.8) (see Fletcher, 2012).
The choice to order the eigenvalues of |$T_k$| in decreasing order is motivated by Fletcher (2012). In short, this ensures that the step sizes in cycle |$k+1$| are ordered from smallest to largest, which improves the likelihood that the objective function and the norm of the objective gradient decrease monotonically, at least initially, in each cycle. This ordering is not essential for our analysis, but is a good choice for any implementation of the algorithm; hence, we state the algorithm to employ this ordering.
One detail that remains for a practical implementation of the method is how to choose the initial step sizes |$\{\alpha_{1,j}\}_{j\in[m]} \subset {\mathbb{R}}{}_{++}$|. This choice has no effect on the theoretical results proved in this article, though our analysis does confirm the fact that the practical performance of the method can be improved if one has the knowledge to choose one or more step sizes exactly equal to reciprocals of eigenvalues of |$A$|; see Section 2.3. Otherwise, one can either provide a full set of |$m$| step sizes or carry out an initialization phase in which the first few cycles are shorter in length, dependent on the number of objective gradients that have been observed so far; see Fletcher (2012), for further discussion on this matter.
In (2.4), if |$G_k$| for some |$k \in {\mathbb{N}}{}$| does not have linearly independent columns, then |$R_k$| is singular and the formulas (2.8) and (2.9) are invalid, meaning that the employed approach is not able to provide |$m$| eigenvalue estimates for cycle |$k$|. As suggested in Fletcher (2012), an implementation of the method can address this by iteratively removing ‘older’ columns of |$G_k$| until the columns form a linearly independent set of vectors, in which case the approach would be able to provide |$[\overset{\sim }{\mathop{m}}\,] \leq m$| stepsizes for the subsequent (shortened) cycle. We advocate such an approach in practice and, based on the results proved in this paper, conjecture that the convergence rate of the algorithm would be |$R$|-linear. However, the analysis for such a method would be extremely cumbersome, given that the number of iterations in each cycle might vary from one cycle to the next within a single run of the algorithm. Hence, in our analysis in Section 3, we assume that |$G_k$| has linearly independent columns for all |$k \in {\mathbb{N}}{}$|. In fact, we go further and assume that |$\|R_k^{-1}\|$| is bounded proportionally to the reciprocal of the norm of the objective gradient at the first iterate in cycle |$k$| (meaning that the upper bound diverges as the algorithm converges to the minimizer of the objective function). These norms are easily computed in an implementation of the algorithm; hence, we advocate that a procedure of iteratively removing ‘older’ columns of |$G_k$| would be based on observed violations of such a bound. See the discussion following Assumption 3.4 in Section 3.
2.3 Finite termination property of LMSD
If, for some |$k \in {\mathbb{N}}{}$| and |$j \in [m]$|, the step sizes in Algorithm LMSD up through iteration |$(k,j) \in {\mathbb{N}}{} \times [m]$| include the reciprocals of all of the |$r \leq n$| distinct eigenvalues of |$A$|, then the algorithm terminates by the end of iteration |$(k,j),$| with |$x_{k,j+1}$| yielding |$\|g_{k,j+1}\| = 0$|. This is shown in the following lemma and theorem, which together demonstrate and extend the arguments made, e.g., in [Fletcher (2012, Section 2).
The result then follows since the columns of |$Q$| form an orthogonal basis of |${\mathbb{R}}{n}$|. □
Suppose that Assumption 2.1 holds and that Algorithm LMSD is run with termination tolerance |$\epsilon = 0$|. If, for some |$(k,j) \in {\mathbb{N}}{} \times [m]$|, the set of computed step sizes up through iteration |$(k,j)$| includes all of the values |$\{\lambda_{(l)}^{-1}\}_{l\in[r]}$|, then, at the latest, the algorithm terminates finitely at the end of iteration |$(k,j)$| with |$x_{k,j+1}$| yielding |$\|g_{k,j+1}\| = 0$|.
Theorem 2.4 implies that Algorithm LMSD will converge finitely by the end of the second cycle if |$m \geq r$| and the eigenvalues of |$T_1$| include all eigenvalues |$\{\lambda_{(l)}\}_{l\in[r]}$|. This is guaranteed, e.g., when the first cycle involves |$m = n$| steps and |$G_1$| has linearly independent columns.
|$\boldsymbol{R}$|-linear convergence rate of LMSD
Our primary goal in this section is to prove that Algorithm LMSD converges |$R$|-linearly for any choice of the history length parameter |$m \in [n]$|. For context, we begin by citing two known convergence results that apply to Algorithm LMSD, then turn our attention to our new convergence rate results.
3.1 Known convergence properties of LMSD
In the appendix of Fletcher (2012), the following convergence result is proved for Algorithm LMSD. The theorem is stated slightly differently here only to account for our different notation.
Suppose that Assumption 2.1 holds and that Algorithm LMSD is run with termination tolerance |$\epsilon = 0$|. Then, either |$g_{k,j} = 0$| for some |$(k,j) \in {\mathbb{N}}{} \times [m]$| or the sequences |$\{g_{k,j}\}_{k=1}^\infty$| for each |$j \in [m]$| converge to zero.
Fletcher’s result, however, does not illuminate the rate at which these sequences converge to zero. Only for the case of |$m=1$| in which Algorithm LMSD reduces to a BB method does the following results from Dai & Liao (2002) (see Lemma 2.4 and Theorem 2.5 therein) provide a convergence rate guarantee.
Overall, the computed gradients vanish |$R$|-linearly with constants that depend only on |$(\lambda_1,\lambda_n)$|.
3.2 |$R$|-linear convergence rate of LMSD for arbitrary |$m \in [n]$|
Our goal in this subsection is to build upon the proofs of the results stated in the previous subsection (as given in the cited references) to show that, under reasonable assumptions, Algorithm LMSD possesses an |$R$|-linear rate of convergence for any |$m \in [n]$|. More precisely, our goal is to show that the gradients computed by the algorithm vanish |$R$|-linearly with constants that depend only on the spectrum of the data matrix |$A$|. One of the main challenges in this pursuit is the fact, hinted at by Lemma 3.2 for the case of |$m=1$|, that the gradients computed in Algorithm LMSD might not decrease monotonically in norm. This is one reason why the analysis in Dai & Liao (2002) is so remarkable, and, not surprisingly, it is an issue that must be overcome in our analysis as well. But our analysis also overcomes new challenges. In particular, the analysis in Dai & Liao (2002) is able to be more straightforward due to the fact that, in a BB method, a step size computation is performed after every iterate update. In particular, this means that, in iteration |$k \in {\mathbb{N}}{}$|, the current gradient |$g_{k,1}$| plays a role in the computation of |$\alpha_{k,1}$|. In LMSD, on the other hand, a set of step sizes are computed and employed in sequence, meaning that multiple iterate updates are performed until the next set of step sizes are computed. This means that, in each cycle, iterate updates are performed using step sizes computed using old gradient information. Another challenge that our analysis overcomes is the fact that the computed step sizes cannot all be characterized in the same manner; rather, as revealed later in Lemma 3.7, each set of step sizes is spread through distinct intervals in the spectrum of |$A$|. Our analysis overcomes all these challenges by keeping careful track of the affects of applying each sequence of step sizes vis-à-vis the weights in (2.10) for all |$(k,j) \in {\mathbb{N}}{} \times [m]$|. In particular, we show that even though the gradients might not decrease monotonically in norm and certain weights in (2.10) might increase within each cycle, and from one cycle to the next, the weights ultimately vanish in a manner that corresponds to |$R$|-linear vanishing of the gradients for any |$m \in [n]$|.
Formally, for simplicity and brevity in our analysis, we make the following standing assumption throughout this section.
Assumption 2.1 holds, as do the following:
(i) Algorithm LMSD is run with |$\epsilon = 0$| and |$g_{k,j} \neq 0$| for all |$(k,j) \in {\mathbb{N}}{} \times [m]$|.
(ii) For all |$k \in {\mathbb{N}}{}$|, the matrix |$G_k$| has linearly independent columns. Further, there exists a scalar |$\rho \geq 1$| such that, for all |$k \in {\mathbb{N}}{}$|, the nonsingular matrix |$R_k$| satisfies |$\|R_k^{-1}\| \leq \rho\|g_{k,1}\|^{-1}$|.

Assumption 3.4|$(i)$| is reasonable because, in any situation in which the algorithm terminates finitely, all of our results hold for the iterations prior to that in which the algorithm terminates. Hence, by proving that the algorithm possesses an |$R$|-linear rate of convergence for cases when it does not terminate finitely, we claim that it possesses such a rate in all cases. As for Assumption 3.4|$(ii)$|, first recall Remark 2.2. In addition, the bound on the norm of the inverse of |$R_k$| is reasonable since, in the case of |$m=1$|, one finds that |$Q_kR_k = G_k = g_{k,1}$| has |$Q_k = g_{k,1}/\|g_{k,1}\|$| and |$R_k = \|g_{k,1}\|$|, meaning that the bound holds with |$\rho=1$|. (This means that, in practice, one might choose |$\rho \geq 1$| and iteratively remove columns of |$G_k$| for the computation of |$T_k$| until one finds |$\|R_k^{-1}\| \leq \rho\|g_{k,1}\|^{-1}$|, knowing that, in the extreme case, there will remain one column for which this condition is satisfied. However, for the reasons already given in Remark 2.2, we make Assumption 3.4, meaning that |$G_k$| always has |$m$| columns.)
Our analysis hinges on properties of the step sizes computed in Steps 12–15 of Algorithm LMSD as they relate to the spectrum of the matrix |$A$|. These properties do not necessarily hold for the initial set of step sizes |$\{\alpha_{1,j}\}_{j\in[m]}$|, which are merely restricted to be in |${\mathbb{R}}{}_{++}$|. However, for ease of exposition in our analysis, rather than distinguish between the step sizes in the initial cycle (i.e., |$k=1$|) vs. all subsequent cycles (i.e., |$k \geq 2$|), we proceed under the assumption that all properties that hold for |$k \geq 2$| also hold for |$k=1$|. (One could instead imagine that an ‘initialization cycle’ is performed corresponding to |$k=0$|, in which case all of our subsequent results are indeed true for all |$k \in {\mathbb{N}}{}$|.) We proceed in this manner, without stating it as a formal assumption, since our main conclusion (see Theorem 3.13) remains true whether or not one counts the computational effort in the initial cycle.
We begin by stating two results that reveal important properties of the eigenvalues (corresponding to the elements of |$\{T_k\}$|) computed by the algorithm, which in turn reveal properties of the step sizes. The first result is a direct consequence of the Cauchy interlacing theorem. Since this theorem is well-known—see, e.g., Parlett (1998)—we state the lemma without proof.
The second result provides more details about how the eigenvalues computed by the algorithm at the end of iteration |$k \in {\mathbb{N}}{}$| relate to the weights in (2.10) corresponding to |$k$| for all |$j \in [m]$|.
The following is a crucial consequence that one can draw from this observation.
If |${\it{\Delta}}_1 = 0$|, then |$d_{1+\hat{k},\hat{j},1} = 0$| for all |$(\hat{k},\hat{j}) \in {\mathbb{N}}{} \times [m]$|. Otherwise, if |${\it{\Delta}}_1 > 0$|, then:
(i) for any |$(k,j) \in {\mathbb{N}}{} \times [m]$| such that |$d_{k,j,1} = 0$|, it follows that |$d_{k+\hat{k},\hat{j},1} = 0$| for all |$(\hat{k},\hat{j}) \in {\mathbb{N}}{} \times [m]$|;
- (ii) for any |$(k,j) \in {\mathbb{N}}{} \times [m]$| such that |$|d_{k,j,1}| > 0$| and any |$\epsilon_1 \in (0,1)$|, it follows that
If |${\it{\Delta}}_1 = 0$|, then the desired conclusion follows from Lemma 3.8; in particular, it follows from the inequality (3.6) for |$i = 1$|. Similarly, for any |$(k,j) \in {\mathbb{N}}{} \times [m]$| such that |$d_{k,j,1} = 0$|, the conclusion in part |$(i)$| follows from the same conclusion in Lemma 3.8, namely, (3.6) for |$i=1$|. Hence, let us continue to prove part |$(ii)$| under the assumption that |${\it{\Delta}}_1 \in (0,1)$| [recall (3.9)].
Since |$\log(\cdot)$| is nondecreasing, the inequalities yielded by (3.11) combined with (3.10) and (3.6) yield the desired result for |$j=1$|. On the other hand, if the conditions of part |$(ii)$| hold for some other |$j \in [m]$|, then the desired conclusion follows from a similar reasoning, though an extra cycle may need to be completed before the desired conclusion holds for all points in the cycle, i.e., for all |$\hat{j} \in [m]$|. This is the reason for the addition of 1 to |$\lceil \log\epsilon_1/\log\Delta_1 \rceil$| in the general conclusion. □
- (i) |${\it{\Delta}}_{p+1} \in [0,1)$| and there exists |$K_{p+1} \geq K_p$| dependent only on |$\epsilon_p$|, |$\rho$| and the spectrum of |$A$| with(3.14)
- (ii) |${\it{\Delta}}_{p+1} \in [1,\infty)$| and, with |$K_{p+1} := K_p + \hat{K}_p + 1$|, there exists |$\hat{k}_0 \in \{K_p,\dots,K_{p+1}\}$| with(3.15)
We have shown that small squared weights in (2.10) associated with indices up through |$p \in [n-1]$| imply that the squared weight associated with index |$p+1$| eventually becomes small. The next lemma shows that these latter squared weights also remain sufficiently small indefinitely.
Repeating this argument for later iterations, we arrive at the desired conclusion. □
The following lemma is a generalization of Lemma 3.2 for any |$m \in [n]$|. Our proof is similar to that of Lemma 2.4 in Dai & Liao (2002). We provide it in full for completeness.
We are now prepared to state our final result, the proof of which follows in the same manner as Theorem 3.3 follows from Lemma 3.2 in Dai & Liao (2002). We prove it in full for completeness.
The sequence |$\{\|g_{k,1}\|\}$| vanishes |$R$|-linearly.
4. Numerical demonstrations
The analysis in the previous section provides additional insights into the behavior of Algorithm LMSD beyond its |$R$|-linear rate of convergence. In this section, we provide the results of numerical experiments to demonstrate the behavior of the algorithm in a few types of cases. The algorithm was implemented and the experiments were performed in Matlab. It is not our goal to show the performance of Algorithm LMSD for various values of |$m$|, say to argue whether the performance improves or not as |$m$| is increased. This is an important question for which some interesting discussion is provided by Fletcher (2012). However, to determine what is a good choice of |$m$| for various types of cases would require a larger set of experiments that are outside of the scope of this article. For our purposes, our only goal is to provide some simple illustrations of the behavior as shown by our theoretical analysis.
Our analysis reveals that the convergence behavior of the algorithm depends on the spectrum of the matrix |$A$|. Therefore, we have constructed five test examples, all with |$n=100$|, but with different eigenvalue distributions. For the first problem, the eigenvalues of |$A$| are evenly distributed in |$[1,1.9]$|. Since this ensures that |$\lambda_n < 2\lambda_1$|, our analysis reveals that the algorithm converges |$Q$|-linearly for this problem; recall the discussion after Lemma 3.8. All other problems were constructed so that |$\lambda_1 = 1$| and |$\lambda_n = 100$|, for which one clearly finds |$\lambda_n > 2\lambda_1$|. For the second problem, all eigenvalues are evenly distributed in |$[\lambda_1,\lambda_n]$|; for the third problem, the eigenvalues are clustered in five distinct blocks; for the fourth problem, all eigenvalues, except one, are clustered around |$\lambda_1$|; and for the fifth problem, all eigenvalues, except one, are clustered around |$\lambda_n$|. Table 1 shows the spectrum of |$A$| for each problem.
Table 1 also shows the numbers of outer and (total) inner iterations required by Algorithm LMSD (indicated by column headers ‘|$k$|’ and ‘|$j$|’, respectively) when it was run with |$\epsilon = 10^{-8}$| and either |$m=1$| or |$m=5$|. In all cases, the initial |$m$| step sizes were generated randomly from a uniform distribution over the interval |$[\lambda_{100}^{-1},\lambda_1^{-1}]$|. One finds that the algorithm terminated in relatively few outer and inner iterations relative to |$n$|, especially when many of the eigenvalues are clustered. This dependence on clustering of the eigenvalues should not be surprising since, recalling Lemma 3.6, clustered eigenvalues makes it likely that an eigenvalue of |$T_k$| will be near an eigenvalue of |$A$|, which in turn implies by Lemma 2.3 that the weights in the representation (2.10) will vanish quickly. On the other hand, for the problems for which the eigenvalues are more evenly spread in |$[1,100]$|, the algorithm required relatively more outer iterations, though still not an excessively large number relative to |$n$|. For these problems, the performance was mostly better for |$m=5$| vs. |$m=1$|, in terms of both outer and (total) inner iterations.
Spectra of |$A$| for five test problems along with outer and (total) inner iteration counts required by Algorithm LMSD and maximum value of the ratio |$\|R_k^{-1}\|/(\|g_{k,1}\|^{-1})$| observed during the run of Algorithm LMSD. For each spectrum, a set of eigenvalues in an interval indicates that the eigenvalues are evenly distributed within that interval
| |$m=1$| | |$m=5$| | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Problem | Spectrum | |$k$| | |$j$| | |$\rho$| | |$k$| | |$j$| | |$\rho$| | |||
| 1 | |$\{\lambda_{ 1},\dots,\lambda_{100}\}$| | |$\subset$| | |$[ 1, 1.9]$| | 13 | 13 | 1 | 3 | 14 | |$\sim 6\times10^3$| | |
| 2 | |$\{\lambda_{ 1},\dots,\lambda_{100}\}$| | |$\subset$| | |$[ 1,100 ]$| | 124 | 124 | 1 | 23 | 114 | |$\sim 1\times10^4$| | |
| 3 | |$\{\lambda_{ 1},\dots,\lambda_{ 20}\}$| | |$\subset$| | |$[ 1, 2 ]$| | 112 | 112 | 1 | 16 | 79 | |$\sim 2\times10^5$| | |
| |$\{\lambda_{21},\dots,\lambda_{ 40}\}$| | |$\subset$| | |$[25, 26 ]$| | ||||||||
| |$\{\lambda_{41},\dots,\lambda_{ 60}\}$| | |$\subset$| | |$[50, 51 ]$| | ||||||||
| |$\{\lambda_{61},\dots,\lambda_{ 80}\}$| | |$\subset$| | |$[75, 76 ]$| | ||||||||
| |$\{\lambda_{81},\dots,\lambda_{100}\}$| | |$\subset$| | |$[99,100 ]$| | ||||||||
| 4 | |$\{\lambda_{ 1},\dots,\lambda_{ 99}\}$| | |$\subset$| | |$[ 1, 2 ]$| | 26 | 26 | 1 | 4 | 20 | |$\sim 2\times10^{16}$| | |
| |$\lambda_{100}$| | |$=$| | |$100$| | ||||||||
| 5 | |$\lambda_1$| | |$=$| | |$1$| | 16 | 16 | 1 | 5 | 25 | |$\sim 2\times10^{10}$| | |
| |$\{\lambda_{ 2},\dots,\lambda_{100}\}$| | |$\subset$| | |$[99,100 ]$| | ||||||||
| |$m=1$| | |$m=5$| | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Problem | Spectrum | |$k$| | |$j$| | |$\rho$| | |$k$| | |$j$| | |$\rho$| | |||
| 1 | |$\{\lambda_{ 1},\dots,\lambda_{100}\}$| | |$\subset$| | |$[ 1, 1.9]$| | 13 | 13 | 1 | 3 | 14 | |$\sim 6\times10^3$| | |
| 2 | |$\{\lambda_{ 1},\dots,\lambda_{100}\}$| | |$\subset$| | |$[ 1,100 ]$| | 124 | 124 | 1 | 23 | 114 | |$\sim 1\times10^4$| | |
| 3 | |$\{\lambda_{ 1},\dots,\lambda_{ 20}\}$| | |$\subset$| | |$[ 1, 2 ]$| | 112 | 112 | 1 | 16 | 79 | |$\sim 2\times10^5$| | |
| |$\{\lambda_{21},\dots,\lambda_{ 40}\}$| | |$\subset$| | |$[25, 26 ]$| | ||||||||
| |$\{\lambda_{41},\dots,\lambda_{ 60}\}$| | |$\subset$| | |$[50, 51 ]$| | ||||||||
| |$\{\lambda_{61},\dots,\lambda_{ 80}\}$| | |$\subset$| | |$[75, 76 ]$| | ||||||||
| |$\{\lambda_{81},\dots,\lambda_{100}\}$| | |$\subset$| | |$[99,100 ]$| | ||||||||
| 4 | |$\{\lambda_{ 1},\dots,\lambda_{ 99}\}$| | |$\subset$| | |$[ 1, 2 ]$| | 26 | 26 | 1 | 4 | 20 | |$\sim 2\times10^{16}$| | |
| |$\lambda_{100}$| | |$=$| | |$100$| | ||||||||
| 5 | |$\lambda_1$| | |$=$| | |$1$| | 16 | 16 | 1 | 5 | 25 | |$\sim 2\times10^{10}$| | |
| |$\{\lambda_{ 2},\dots,\lambda_{100}\}$| | |$\subset$| | |$[99,100 ]$| | ||||||||
Spectra of |$A$| for five test problems along with outer and (total) inner iteration counts required by Algorithm LMSD and maximum value of the ratio |$\|R_k^{-1}\|/(\|g_{k,1}\|^{-1})$| observed during the run of Algorithm LMSD. For each spectrum, a set of eigenvalues in an interval indicates that the eigenvalues are evenly distributed within that interval
| |$m=1$| | |$m=5$| | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Problem | Spectrum | |$k$| | |$j$| | |$\rho$| | |$k$| | |$j$| | |$\rho$| | |||
| 1 | |$\{\lambda_{ 1},\dots,\lambda_{100}\}$| | |$\subset$| | |$[ 1, 1.9]$| | 13 | 13 | 1 | 3 | 14 | |$\sim 6\times10^3$| | |
| 2 | |$\{\lambda_{ 1},\dots,\lambda_{100}\}$| | |$\subset$| | |$[ 1,100 ]$| | 124 | 124 | 1 | 23 | 114 | |$\sim 1\times10^4$| | |
| 3 | |$\{\lambda_{ 1},\dots,\lambda_{ 20}\}$| | |$\subset$| | |$[ 1, 2 ]$| | 112 | 112 | 1 | 16 | 79 | |$\sim 2\times10^5$| | |
| |$\{\lambda_{21},\dots,\lambda_{ 40}\}$| | |$\subset$| | |$[25, 26 ]$| | ||||||||
| |$\{\lambda_{41},\dots,\lambda_{ 60}\}$| | |$\subset$| | |$[50, 51 ]$| | ||||||||
| |$\{\lambda_{61},\dots,\lambda_{ 80}\}$| | |$\subset$| | |$[75, 76 ]$| | ||||||||
| |$\{\lambda_{81},\dots,\lambda_{100}\}$| | |$\subset$| | |$[99,100 ]$| | ||||||||
| 4 | |$\{\lambda_{ 1},\dots,\lambda_{ 99}\}$| | |$\subset$| | |$[ 1, 2 ]$| | 26 | 26 | 1 | 4 | 20 | |$\sim 2\times10^{16}$| | |
| |$\lambda_{100}$| | |$=$| | |$100$| | ||||||||
| 5 | |$\lambda_1$| | |$=$| | |$1$| | 16 | 16 | 1 | 5 | 25 | |$\sim 2\times10^{10}$| | |
| |$\{\lambda_{ 2},\dots,\lambda_{100}\}$| | |$\subset$| | |$[99,100 ]$| | ||||||||
| |$m=1$| | |$m=5$| | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Problem | Spectrum | |$k$| | |$j$| | |$\rho$| | |$k$| | |$j$| | |$\rho$| | |||
| 1 | |$\{\lambda_{ 1},\dots,\lambda_{100}\}$| | |$\subset$| | |$[ 1, 1.9]$| | 13 | 13 | 1 | 3 | 14 | |$\sim 6\times10^3$| | |
| 2 | |$\{\lambda_{ 1},\dots,\lambda_{100}\}$| | |$\subset$| | |$[ 1,100 ]$| | 124 | 124 | 1 | 23 | 114 | |$\sim 1\times10^4$| | |
| 3 | |$\{\lambda_{ 1},\dots,\lambda_{ 20}\}$| | |$\subset$| | |$[ 1, 2 ]$| | 112 | 112 | 1 | 16 | 79 | |$\sim 2\times10^5$| | |
| |$\{\lambda_{21},\dots,\lambda_{ 40}\}$| | |$\subset$| | |$[25, 26 ]$| | ||||||||
| |$\{\lambda_{41},\dots,\lambda_{ 60}\}$| | |$\subset$| | |$[50, 51 ]$| | ||||||||
| |$\{\lambda_{61},\dots,\lambda_{ 80}\}$| | |$\subset$| | |$[75, 76 ]$| | ||||||||
| |$\{\lambda_{81},\dots,\lambda_{100}\}$| | |$\subset$| | |$[99,100 ]$| | ||||||||
| 4 | |$\{\lambda_{ 1},\dots,\lambda_{ 99}\}$| | |$\subset$| | |$[ 1, 2 ]$| | 26 | 26 | 1 | 4 | 20 | |$\sim 2\times10^{16}$| | |
| |$\lambda_{100}$| | |$=$| | |$100$| | ||||||||
| 5 | |$\lambda_1$| | |$=$| | |$1$| | 16 | 16 | 1 | 5 | 25 | |$\sim 2\times10^{10}$| | |
| |$\{\lambda_{ 2},\dots,\lambda_{100}\}$| | |$\subset$| | |$[99,100 ]$| | ||||||||
In Table 1, we also provide the maximum over |$k$| of the ratio |$\|R_k^{-1}\|/(\|g_{k,1}\|^{-1})$| (indicated by the column header ‘|$\rho$|’) observed during the run of the algorithm for each test problem and each |$m$|. The purpose of this is to confirm that Assumption 3.4 indeed held in our numerical experiments, but also to demonstrate for what value of |$\rho$| the assumption holds. As explained following Assumption 3.4, for |$m = 1$|, the ratio was always equal to |$1$|. As for |$m = 5$|, on the other hand, the ratio was sometimes quite large, though it is worthwhile to remark that the ratio was typically much smaller than this maximum value. We did not observe any predictable behavior about when this maximum value was observed; sometimes it occurred early in the run, while sometimes it occurred toward the end. Overall, the evolution of this ratio depends on the initial point and path followed by the algorithm to the minimizer.
As seen in our analysis (inspired by Raydan, 1993; Dai & Liao, 2002; Fletcher, 2012), a more refined look into the behavior of the algorithm is obtained by observing the step-by-step magnitudes of the weights in (2.10) for the generated gradients. Hence, for each of the test problems, we plot in Figs 1– 5 these magnitudes (on a log scale) for a few representative values of |$i \in [n]$|. Each figure consists of four sets of plots: the first and third show the magnitudes corresponding to |$\{g_{k,1}\}$| (i.e., for the first point in each cycle) when |$m=1$| and |$m=5$|, respectively, while the second and fourth show the magnitudes at all iterations (including inner ones), again when |$m=1$| and |$m=5$|, respectively. In a few of the images, the plot ends before the right-hand edge of the image. This is due to the log of the absolute value of the weight being evaluated as |$-\infty$| in Matlab.
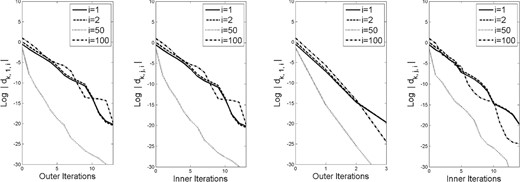
Weights in (2.10) for problem |$1$| with history length |$m=1$| (left two plots) and |$m=5$| (right two plots).
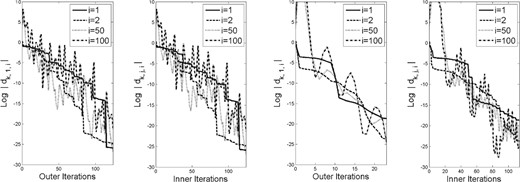
Weights in (2.10) for problem |$2$| with history length |$m=1$| (left two plots) and |$m=5$| (right two plots).
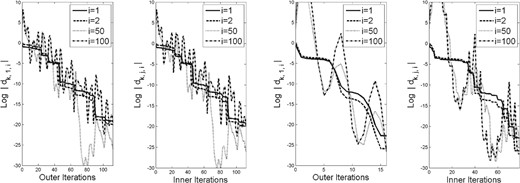
Weights in (2.10) for problem |$3$| with history length |$m=1$| (left two plots) and |$m=5$| (right two plots).
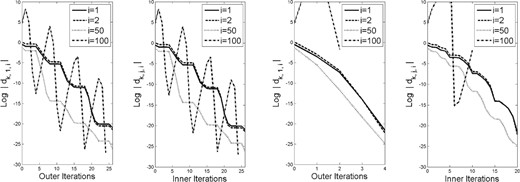
Weights in (2.10) for problem |$4$| with history length |$m=1$| (left two plots) and |$m=5$| (right two plots).
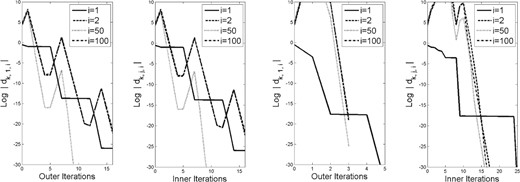
Weights in (2.10) for problem |$5$| with history length |$m=1$| (left two plots) and |$m=5$| (right two plots).
The figures show that the magnitudes of the weights corresponding to |$i=1$| always decrease mono-tonically, as proved in Lemma 3.9. The magnitudes corresponding to |$i=2$| also often decrease monotonically, but, as seen in the results for Problem 5, this is not always the case. In any case, the magnitudes corresponding to |$i=50$| and |$i=100$| often do not decrease monotonically, though, as proved in our analysis, one observes that the magnitudes demonstrate a downward trend over a finite number of cycles.
Even further insight into the plots of these magnitudes can be gained by observing the values of the constants |$\{{\it{\Delta}}_i\}_{i\in[n]}$| for each problem and history length. Recalling (3.6), these constants bound the increase that a particular weight in (2.10) might experience from one point in a cycle to the same point in the subsequent cycle. For illustration, we plot in Figs 6–10 these constants. Values less than 1 are indicated by a black bar, while values greater than or equal to 1 are indicated by a gray bar. Note that, in Fig. 9, all values are small for both history lengths except |${\it{\Delta}}_{100}$|. In Fig. 10, |${\it{\Delta}}_1$| is less than 1 in both figures, but the remaining constants are large for |$m=1$| while being small for |$m=5$|.
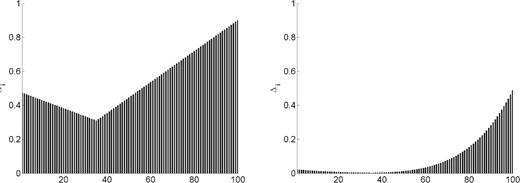
Constants in (3.6) for problem |$1$| with history length |$m=1$| (left plot) and |$m=5$| (right plot).
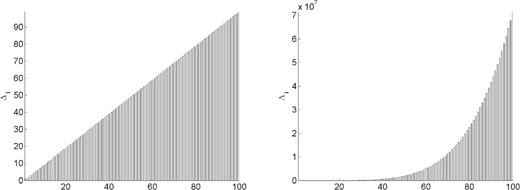
Constants in (3.6) for problem |$2$| with history length |$m=1$| (left plot) and |$m=5$| (right plot).
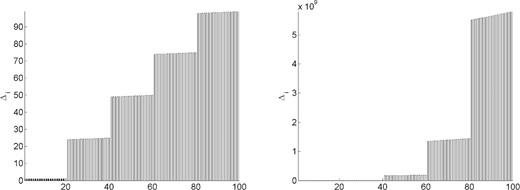
Constants in (3.6) for problem |$3$| with history length |$m=1$| (left plot) and |$m=5$| (right plot).
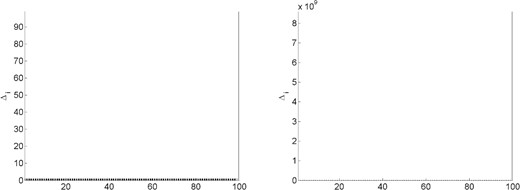
Constants in (3.6) for problem |$4$| with history length |$m=1$| (left plot) and |$m=5$| (right plot).
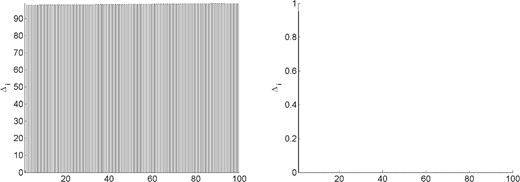
Constants in (3.6) for problem |$5$| with history length |$m=1$| (left plot) and |$m=5$| (right plot).
5. Conclusion
We have shown that the LMSD method proposed by Fletcher (2012) possesses an |$R$|-linear rate of convergence for any history length |$m \in [n]$|, when it is employed to minimize a strongly convex quadratic function. Our analysis effectively extends that in Dai & Liao (2002), which covers only the |$m=1$| case. We have also provided the results of numerical experiments to demonstrate that the behavior of the algorithm reflects certain properties revealed by the theoretical analysis.
One might wonder whether the convergence rate of LMSD is the same when Ritz values are replaced by harmonic Ritz values; see [Fletcher (2012, Section 7]. We answer this in the affirmative in the appendix.
Acknowledgements
The authors would like to thank the Associate Editor for handling the submission of this paper as well as the two anonymous referees whose comments and suggestions helped to improve it. They would also like to thank Prof. Yu-Hong Dai, whose presentation at the Fifth International Conference on Continuous Optimization was an inspiration to complete this work.
Funding
U.S. Department of Energy, Office of Science, Office of Advanced Scientific Computing Research, Applied Mathematics, Early Career Research Program [contract number DE–SC0010615]; U.S. National Science Foundation [grant nos DMS–1319356 and CCF-1618717].
Appendix. LMSD with harmonic Ritz values
As explained in Fletcher (2012, Section 7), an alternative limited memory steepest descent method (LMSD) is one that replaces Ritz values of |$A$| with harmonic Ritz values (see also Curtis & Guo, 2016). In the case of |$m=1$|, this reduces to replacing the ‘first’ with the ‘second’ BB step size formula; see in Barzilai & Borwein (1988, (5)–(6)). In this appendix, we briefly describe the differences in the computations involved in this alternative approach, then argue that the resulting algorithm is also |$R$|-linearly convergent. In fact, much of the analysis in Section 3.2 remains true for this alternative algorithm, so here we only highlight the minor differences.
One also finds that |$P_k = T_k^TT_k + \zeta_k\zeta_k^T$|, where |$\zeta_k^T = \left[ 0 \quad \xi_k \right] J_kR_k^{-1}$| (see Curtis & Guo, 2016).
Let us now argue that this alternative LMSD method is |$R$|-linearly convergent. For this, we first show that the harmonic Ritz values satisfy the same property as shown for the Ritz values in Lemma 3.6.
One can apply, e.g., Theorem 2.1 from Beattie (1998) with ‘|$K$|’|$ = A$|, ‘|$M$|’|$ = I$|, and ‘|$P$|’|$ = Q_k$|, the proof of which follows from min–max characterizations of the eigenvalues.
Given Lemma A.1, one can verify that the results shown in Lemmas 3.8 and 3.9 also hold for our alternative LMSD method. The result in Lemma 3.10 remains true as well, though the argument for this requires a slight addition to the proof. First, we need the following known property that the Ritz and harmonic Ritz values are interlaced (e.g., see Curtis & Guo, 2016, Theorem 3.3).
The remainder of the proof then follows as before with |$\alpha_{k+\hat{k}+1,j} = \mu_{k+\hat{k},j}^{-1}$| for all |$j \in [m]$|. A similar modification is needed in the proof of Lemma 3.11 since it employs a similar argument as in the proof of Lemma 3.10. This way, one can verify that Lemma 3.11 remains true for the alternative LMSD method. Finally, as for Lemma 3.12 and Theorem 3.13, our proofs follow as before without any modifications.
References
Author notes
Dedicated to Roger Fletcher and Jonathan Borwein, whose contributions continue to inspire many in the fields of nonlinear optimization and applied mathematics

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}