





ABSTRACT
Wide-field imaging surveys such as the Dark Energy Survey (DES) rely on coarse measurements of spectral energy distributions in a few filters to estimate the redshift distribution of source galaxies. In this regime, sample variance, shot noise, and selection effects limit the attainable accuracy of redshift calibration and thus of cosmological constraints. We present a new method to combine wide-field, few-filter measurements with catalogues from deep fields with additional filters and sufficiently low photometric noise to break degeneracies in photometric redshifts. The multiband deep field is used as an intermediary between wide-field observations and accurate redshifts, greatly reducing sample variance, shot noise, and selection effects. Our implementation of the method uses self-organizing maps to group galaxies into phenotypes based on their observed fluxes, and is tested using a mock DES catalogue created from N-body simulations. It yields a typical uncertainty on the mean redshift in each of five tomographic bins for an idealized simulation of the DES Year 3 weak-lensing tomographic analysis of σΔz = 0.007, which is a 60 per cent improvement compared to the Year 1 analysis. Although the implementation of the method is tailored to DES, its formalism can be applied to other large photometric surveys with a similar observing strategy.
1 INTRODUCTION
Solving the mysteries surrounding the nature of the cosmic acceleration requires measuring the growth of structure with exquisite precision and accuracy. To this end, one of the most promising probes is weak gravitational lensing. In weak lensing, light from distant source galaxies is deflected by the large-scale structure of the Universe, affecting their apparent shapes by gravitational shear (see e.g. Bartelmann & Schneider 2001, Kilbinger 2015, or Mandelbaum 2018 for a review on the subject). The amplitude of the shear depends on the distribution of the matter causing the lensing, and the distance ratios of source and lens galaxies. The physical interpretation of the signal is thus sensitive to systematic errors in redshift (Huterer et al. 2006; Ma, Hu & Huterer 2006). For precision cosmology from weak lensing probes, an accurate measurement of galaxy shapes must be coupled with a robust characterization of the redshift distribution of source galaxies.
In imaging surveys, redshift must be inferred from the electromagnetic spectral energy distribution (SED) of distant galaxies, integrated over a number of filter bands. Ongoing broad-band imaging surveys, such as the Dark Energy Survey (DES; Dark Energy Survey Collaboration 2005), the Hyper Suprime-Cam Subaru Strategic Program (HSC-SPP; Aihara et al. 2018), and the Kilo Degree Survey (KiDS; de Jong et al. 2013), as well as upcoming ones such as the Large Synoptic Survey Telescope (LSST; Ivezić et al. 2008), the Euclid survey (Laureijs et al. 2011), and the Wide-Field InfraRed Survey Telescope (WFIRST; Spergel et al. 2013), rely on measurements of flux in a small number of bands (three to six) to determine redshifts of source galaxies.
The coarse measurement of a galaxy’s redshifted SED often does not uniquely determine its redshift and type: two different rest-frame SEDs at two different redshifts can be indistinguishable, as illustrated in Fig. 1 (lower panel). This type/redshift degeneracy is the fundamental cause of uncertainty in redshift calibration, i.e. in the constraint of the mean and shape of the redshift distribution of an ensemble of galaxies, across methods. It can bias template-fitting methods (e.g. Benítez 2000; Ilbert et al. 2006), even with a Bayesian treatment of sufficiently flexible template sets, because the choice of priors determines the mix of estimated type/redshift combinations at fixed ambiguous broad-band fluxes. It can bias empirical methods based on machine learning (e.g. Collister & Lahav 2004; Carrasco Kind & Brunner 2013; De Vicente, Sánchez & Sevilla-Noarbe 2016) or direct calibration from spectroscopic samples, because present spectroscopic samples are subject to selection effects at fixed broad-band observables (Bonnett et al. 2016; Gruen & Brimioulle 2017). These can be both explicit (i.e. because spectroscopic targets were selected by properties not observed in a wide-field survey) or implicit (i.e. because success of spectroscopic redshift determination depends on type/redshift). Type/redshift degeneracy contributes to the dominant systematic uncertainty in redshifts derived from cross-correlations (Schneider et al. 2006; Newman 2008; Ménard et al. 2013; Schmidt et al. 2013; Davis et al. 2017,2018; Hildebrandt et al. 2017; Samuroff et al. 2017), the evolution of clustering bias with redshift (Gatti et al. 2018). The latter is due in part to the evolution of the mix of galaxy types as a function of redshift. Because of type/redshift degeneracy, such an evolution is present in any sample that can be selected from broad-band photometry. Finally, type/redshift degeneracy is the fundamental reason for sample variance in redshift calibration from fields like COSMOS (Lima et al. 2008; Amon et al. 2018; Hoyle et al. 2018): a criterion based on few broad-band colours selects a mix of galaxy types/redshifts that depends on the large-scale structure present in a small calibration field.
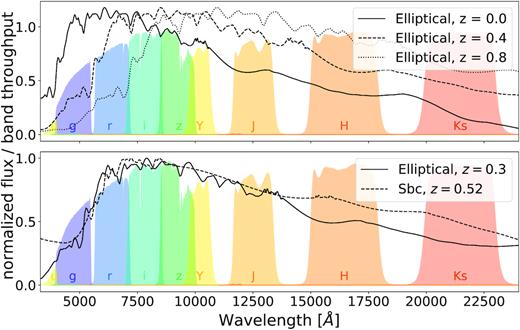
Illustration of how redshift can be estimated from broad-band images, yet not always unambiguously. Top: The same template of an elliptical galaxy is redshifted at z = 0.4 and z = 0.8. These objects exhibit clearly different colours. Bottom: Templates of an elliptical galaxy and a Sbc galaxy at different redshifts are plotted. In the optical (e.g. from griz information), those two objects are indistinguishable: type and redshift are degenerate. Adding u and near-infrared bands – especially the H and Ks bands – differentiates them. Coloured areas show relative throughput of DES ugriz and VISTA YJHKs bands. Galaxy templates are taken from Benítez et al. (2004).
A substantial improvement in redshift calibration therefore requires that the type/redshift degeneracy in wide-field surveys be broken more effectively. While the collection of large, representative samples of faint galaxy spectra remains unfeasible, recent studies indicate that broad-band photometry that covers the full range of optical and near-infrared wavelengths substantially improves the accuracy of redshift calibration (Masters et al. 2017; Hildebrandt et al. 2018). This is again illustrated by the lower panel of Fig. 1: the additional bands can break type/redshift degeneracies that are present in, e.g. (g)riz information. Over large areas and to the depth of upcoming surveys, only few-band photometry is readily available, primarily due to a lack of efficient near-infrared survey facilities (but cf. KiDS+VIKING; Wright et al. 2018). However, in the next decade, imaging surveys such as the Euclid survey (Laureijs et al. 2011) and WFIRST (Spergel et al. 2013) have been designed to address this lack of near-infrared data.
In this paper, we develop a method that leverages photometric data in additional filters (and with sufficiently low photometric noise), available over a limited area of a survey, to break degeneracies and thus overcome the key limitations of redshift distribution characterization from few-band data. Optical surveys commonly observe some regions more often than the wide-field, and these can be chosen to overlap with auxiliary near-infrared data and spectroscopy. The galaxies observed in these ‘deep fields’ can be grouped into a sufficiently fine-grained set of phenotypes based on their observed many-band fluxes (Sánchez & Bernstein 2018). The average density with which galaxies from each phenotype appear in the sky can be measured more accurately from the deep fields than from a smaller spectroscopic sample.
The redshift distribution of a deep-field phenotype can be estimated from a sub-sample for which both the multiband fluxes and accurate redshifts are available. This could be the result of a future targeted spectroscopic campaign (cf. Masters et al. 2015) or, as long as spectroscopic redshifts do not cover all phenotypes, a photometric campaign with high-quality and broad wavelength coverage, to be used with a template fitting method. Members of a phenotype have very similar multiband colours, giving typically a compact redshift distribution. This substantially reduces redshift biases that might arise from non-representative or incomplete spectroscopic follow-up, sample variance, or from variation of clustering bias with redshift. The larger volume and depth of the deep fields allow the estimation of the density of galaxies from each phenotype in the sky with a lower sample variance, lower shot noise, and higher completeness than would be possible from redshift samples alone. Knowing this density and the multiband properties of a phenotype and applying the distribution of measurement noise in the wide survey, we can determine the probability that an observation in the wide field originates from a given phenotype. That is, we learn how to statistically break the type/redshift degeneracy at given broad-band flux from a larger sample of galaxies than is possible to obtain accurate redshifts for. In this scheme, the multiband deep measurements thus mediate an indirect mapping between wide-field measurements and accurate redshifts.
For the purpose of developing the method in this paper, we will assume that the subset of galaxies with known redshifts (1) is representative at any position in multiband deep field colour space, and (2) has their redshifts characterized accurately. While progress is being made towards achieving this with spectroscopy (e.g. Masters et al. 2019), or many-band photometric redshifts, which show promising performance (at least for a large subset of the source galaxies measured in DES; Laigle et al. 2016; Eriksen et al. 2019), substantial work remains to be done on validating this assumption in practical applications of our scheme, and extending its validity to the fainter galaxy samples required by future lensing surveys.
The paper is organized as follows. In Section 2, we develop the formalism of the method which is tested on a mock galaxy catalogue presented in Section 3. The implementation of the method with self-organizing maps (SOMs) is presented in Section 4 and the fiducial choices of features and hyperparameters are described in Section 5. The performance of the method with unlimited samples is assessed in Section 6. We then apply the method to a simulated DES catalogue in order to forecast its performance on ongoing and future surveys. The DES Year 3 (Y3), i.e. the analysis of the data taken in the first 3 yr of DES, targets an uncertainty in the mean redshift of each source tomographic bin σΔz ∼ 0.01, which is unmatched for wide-field galaxy samples with comparable data, and a main motivation for this work. The sources of uncertainty and their impacts on a DES Y3-like calibration are characterized in Section 7. The impact of the DES Y3 weak lensing analysis choices on redshift calibration are assessed in Section 8. We describe the redshift uncertainty on a DES Y3-like analysis in Section 9 and explore possible improvements of the calibration in Section 10. Finally, we conclude in Section 11. A reader less interested in technical aspects may wish to focus on Section 2 and Section 7.
We define three terms used in this paper that have varying uses in the cosmological literature. By sample variance we mean a statistical uncertainty introduced by the limited volume of a survey. By shot noise we mean a statistical uncertainty introduced by the limited number of objects in a sample. And the term bias is used for a mean offset of an estimated quantity from a true one that remains after averaging over many (hypothetical) random realizations of a survey.
2 FORMALISM
In this section we develop a method based on galaxy phenotypes to estimate redshift distributions in tomographic bins. The method is applicable to any photometric survey with a similar observation strategy to DES.
Assume two kinds of photometric measurements are obtained over the survey: wide data (e.g. flux or colours), available for every galaxy in the survey, and deep data, available only for a subset of galaxies. The dimensionality of the deep data is higher by having flux measurements in more bands of the electromagnetic spectrum. We shall denote the wide data by |$\mathbf {\hat{x}}$| with errors |$\mathbf {\hat{\Sigma }}$|. We will call the deep data |$\mathbf {x}$|. We will assume noiseless deep data, but confirm that obtainable levels of deep field noise do not affect our conclusions. The deep sample is considered complete in the sense that any galaxy included in the wide data would be observed if its location was within a deep field.
A third sample contains galaxies with confidently known redshifts, z. The redshift data can be obtained using many-band photometric observations or spectroscopy. In this work, we will assume the redshift sample to be a representative subset of the deep data, with perfect redshift information. This is a fair assumption when the redshift sample is populated with high-quality photometric redshifts (e.g. from COSMOS or multimedium/narrow-band surveys), and the deep sample is complete to sufficiently faint magnitudes. It is, however, a strong assumption for spectroscopic redshifts when matched to a photometric sample with only few observed bands (Gruen & Brimioulle 2017). As one increases the wavelength coverage, the assumption of representativeness becomes less problematic: in our scheme, it is only required to hold at each position in deep multicolour space, and thus only for subsets of galaxies with close to uniform type and well-constrained redshift. This is confirmed by the observation that, at a given position in seven-colour optical-NIR data space, the dependence of mean redshift on magnitude is small. Once in a discretized cell of the Euclid/WFIRST colour space, Masters et al. (2019) quantify the dependence on galaxy brightness as ∼0.0029 change in |$\Delta z/(1 + \bar{z})$| per magnitude. Thus despite a selection effect in the spectroscopic survey to only observe a brighter subset of the galaxies at given deep multiband colour, the inferred redshift distribution would still be close to unbiased and representative of the full sample.
In order to estimate the conditional probability |$p(z|\mathbf {\hat{x}})$|, the deep sample can be used as an intermediary between wide-field photometry and redshift. Redshifts inferred directly from wide measurements with only a small number of bands can be degenerate when distinct galaxy types/redshifts yield the same observables. This is the ultimate reason behind sample variance and selection biases in redshift calibration: the same observed wide-field data can correspond to different distributions of redshift depending on the line of sight or additional selections, e.g. based on the success of a spectroscopic redshift determination. Sample variance, shot noise, and selection effects may thus cause the mix of types/redshifts in a redshift sample at given |$\mathbf {\hat{x}}$| to deviate from the mean of a complete sample collected over a larger area.
The type/redshift degeneracy is mitigated for a deep sample in which supplementary bands and more precise photometry reduce the type mixing at a given point in multicolour space. A tighter relation can in this case be found between redshifts and deep observables. At the same time, the small sample of galaxies with known accurate redshifts can be reweighted to match the density of deep field galaxies in this multicolour space. Because the position in this multicolour space is highly indicative of type and redshift, and because larger, complete samples of deep photometric galaxies can be collected, this reweighting evens out the type/redshift mix of the redshift sample at given wide-field flux (Lima et al. 2008). As a result, sample variance and selection effects present in the redshift sample are reduced. By statistically relating the deep to the wide data that would be observed for the same galaxy, the deep sample enables estimating wide galaxy redshifts with reduced susceptibility to sample variance and selection effects.
The deep and wide data sets do not necessarily represent the same population of galaxies. Not all galaxies seen in the deep field are detected in the wide field, and for a particular science case, not all the galaxies detected in the wide data are used. Only the ones satisfying some selection, |$\hat{s}$|, are taken into account. The wide data, |$\mathbf {\hat{x}}$|, and its errors, |$\mathbf {\hat{\Sigma }}$|, are correlated with other properties that may enter in the selection, |$\hat{s}$|, such as ellipticity or size. These properties are linked to colours in the deep observations, |$\mathbf {x}$|, that are unobserved in the wide data. For example, morphology correlates with galaxy colour (e.g. Larson, Tinsley & Caldwell 1980; Strateva et al. 2001). Assume one sample, |$\hat{s}_0$|, selects elliptical galaxies and another, |$\hat{s}_1$|, selects spiral galaxies. Those two samples will have a different distribution of |$\mathbf {x}$| given |$\mathbf {\hat{x}}$|. Therefore, the mapping of |$\mathbf {\hat{x}}$| to z will be different for different science samples, |$\hat{s}$|. In our case |$\hat{s}$| is the selection of observed DES galaxies that end up in our weak lensing source catalogue.
It is useful to consider the sources of bias, sample variance, and shot noise inherent to this scheme. We note that the transfer function, |$p(c|\hat{c}, \hat{s})$|, is proportional to |$p(\hat{c}, \hat{s}|c)p(c)$| per Bayes’ theorem. Sample variance and shot noise in the estimated redshift distribution can thus be caused by the limited volume and count of the deep galaxy sample, introducing noise in p(c), or by the limited overlap sample, introducing noise in |$p(\hat{c}, \hat{s}|c)$|. If it were the case that c uniquely determines the redshift, there would be no variance in p(z|c) as long as a redshift is known for at least one galaxy from each deep cell c. For a large enough sample of bands in the deep data, p(z|c) is indeed much narrower than |$p(z|\hat{c},\hat{s})$|. Sample variance and shot noise due to limited redshift sample (as estimated in Bordoloi, Lilly & Amara 2010; Gruen & Brimioulle 2017) can therefore be reduced in this scheme.
Biases could be introduced by the discretization. Equation (4) is an approximation to equation (2) that breaks when the redshift distribution varies within the confines of a c cell in a way that is correlated with |$\hat{c}$| or |$\hat{s}$|. One of the purposes of this paper is to test the validity of this approximation (see Section 5.2 and Section 6).
2.1 Source bin definition
To perform tomographic analysis of lensing signals (see e.g. Hu 1999), galaxies must be placed into redshift bins. The pheno-z method, developed in Section 2, to estimate redshift distributions is independent of the bin assignment method. The simple algorithm presented in this section is aimed to assign galaxies to one bin uniquely, with little overlap of bins, such that each contains roughly the same number of galaxies.
To achieve the binning, two samples are used: the redshift sample for which we have deep measurements and the overlap sample for which we have deep and wide measurements. The redshift sample is assigned to cells c and the mean redshift, |$\bar{z}_c$|, in each of those cells is computed. Each galaxy in the overlap sample is assigned to cells c and |$\hat{c}$|. The fractional occupation of those cells |$f_{c}=p(c|\hat{s})$| and |$f_{\hat{c}}=p(\hat{c}|\hat{s})$| are such that |$\sum _c f_{c} = \sum _{\hat{c}} f_{\hat{c}} = 1$|. All galaxies in the redshift sample are used whereas only the galaxies respecting the selection criteria enter the overlap sample.
We wish to assign galaxies to Nbin tomographic bins (Nbin = 5 in this work). The first step consists of assigning cells c to tomographic bins B. The cells |$\hat{c}$| are then assigned to tomographic bins |$\hat{B}$| using the transfer function. The procedure is the following:
Cells c are sorted by their mean redshift, |$\bar{z}_c$|, in ascending order. Cells are assigned to bin B until |$\sum _{c\in B}f_c \ge \frac{1}{N_{\mathrm{bin}}}$|, where B = 1, ..., Nbin. We discuss the impact of cells lacking redshift information in Section 7.4.
- Each cell |$\hat{c}$| is assigned to a bin |$\hat{B}$| by finding which bin B it has the highest probability of belonging to through |$p(c|\hat{c},\hat{s})$|:(5)\begin{eqnarray*} \hat{B} = {\rm argmax}_B p(B|\hat{c},\hat{s}) = {\rm argmax}_B \sum _{c\in B} p(c|\hat{c}, \hat{s}). \end{eqnarray*}
Individual galaxies are assigned to bin |$\hat{B}$| based on their wide cell assignment, |$\hat{c}$|.
3 SIMULATED DES GALAXY CATALOGUES
In this work we use simulated galaxy catalogues designed to mimic observational data collected with the Dark Energy Camera (DECam; Honscheid et al., 2008; Flaugher et al. 2015). DECam is a 570 megapixel camera with a 3 deg2 field-of-view, installed at the prime focus of the Blanco 4-m telescope at the Cerro Tololo Inter-American Observatory (CTIO) in northern Chile. In addition, we mimic data by surveys conducted with the Visible and Infrared Survey Telescope for Astronomy (VISTA; Emerson et al. 2004), a 4-m telescope located at ESO’s Cerro Paranal Observatory in Chile and mounted with a near-infrared camera, VIRCAM (VISTA InfraRed CAMera), which has a 1.65 degree diameter field-of-view containing 67 megapixels. Both the underlying real and simulated galaxy samples are described below.
3.1 The Dark Energy Survey
The DES is an ongoing ground-based wide-area optical imaging survey which is designed to probe the causes of cosmic acceleration through four independent probes: Type Ia supernovae, baryon acoustic oscillations, weak gravitational lensing, and galaxy clusters. After 6 yr of operations (2013–2019), the survey has imaged about one-eighth of the total sky. DES has conducted two distinct multiband imaging surveys with DECam: a ∼5000 deg2 wide-area survey in the grizY bands1 and a ∼27 deg2 deep supernova survey observed in the griz bands. The deep supernova survey overlaps with the VISTA YJHKs bands measurements, and we have obtained u band imaging of these fields using DECam.
3.1.1 DES Year 3 samples
The pheno-z method requires four samples to estimate redshift distributions in tomographic bins using equation (6). The following data sets will be used in the DES Y3 analysis:
Deep sample: In DES, ugriz deep photometry is obtained in 10 supernova fields (∼27 deg2), as well as in the COSMOS field (∼2 deg2). Some of those fields overlap with deep VISTA measurements in the YJHKs bands from the UltraVista survey (McCracken et al. 2012) for COSMOS and from the VISTA Deep Extragalactic Observations (VIDEO; Jarvis et al. 2013) survey for the supernova fields. Table 1 summarizes the overlap between the DES deep photometry and the UltraVISTA (COSMOS) and VIDEO fields. The VISTA Y band is available in three of the four fields where JHKs bands are available. Including the Y band reduces the total available area from 9.93 to 7.99 deg2. We examine the trade-off between area and Y band in Section 7.3.2. In the especially deep supernova fields C3 and X3, DECam griz is at an equivalent depth of at least 200 × 90 s, while the regular depth supernova field E2 has at least 80 × 90 s exposures, compared to a final wide-field DES exposure time of 10 × 90 s.
Redshift sample: The galaxies in the COSMOS field can be assigned a redshift either by using many-band photo-zs (Laigle et al. 2016) which are available for all galaxies or by using spectroscopic redshifts available for a subset of galaxies as long as this subset is representative of the colour space spanned by the deep sample and is a fair sample of z within any given cell.2 The use of many-band photo-z is advantageous as it avoids selection effects commonly present in spectroscopic samples. The COSMOS catalogue provides photometry in 30 different UV, visible, and IR bands. For each galaxy, the probability density function (PDF) pC30(z) of its redshift given its photometry is computed using the LePhare template-fitting code (Arnouts et al. 1999; Ilbert et al. 2006). The typical width of pC30(z) for DES sources is ≈0.01(1 + z) and the typical catastrophic failure rate is 1 per cent. The available overlap between DES deep and UltraVista for which many-band photo-zs are available is 1.38 deg2 and contains ∼135 000 galaxies.
Overlap sample: This sample comprises objects for which deep and (possibly synthetic) wide measurements are available. In practice, we will use balrog (Suchyta et al. 2016), a software package that paints synthetic galaxies into observed images in order to render wide measurements and assess selection effects. The deep sample galaxies are painted several times over the whole DES footprint to produce a number of realizations of each deep field galaxy under different observing conditions and noise realizations. The shape measurement pipeline is also run on those fake galaxies yielding only objects that would end up in the shape catalogue after its cuts on e.g. observed size and signal-to-noise ratio. This method produces a sample of galaxies with deep and wide measurements with the same selection as the real source galaxies used in the weak lensing analysis.
Wide sample: All galaxies that are selected for the shape catalogue are included in the wide sample. These are the galaxies for which we infer the redshift distributions.
Overlap between DES deep ugriz measurements and VISTA (Y)JHKs measurements. E2, X3, and C3 refer to the DES supernova fields and |$\mathcal {C}$| to the COSMOS field. There are VISTA Y band measurements in COSMOS, E2, and X3 fields but not in the C3 field. The last column shows the reduced deep field area when using Y band.
| E2 | X3 | C3 | |$\boldsymbol{\mathcal {C}}$| | Total | ||
|---|---|---|---|---|---|---|
| JHKs | YJHKs | |||||
| Overlap (deg2) | 3.32 | 3.29 | 1.94 | 1.38 | 9.93 | 7.99 |
| E2 | X3 | C3 | |$\boldsymbol{\mathcal {C}}$| | Total | ||
|---|---|---|---|---|---|---|
| JHKs | YJHKs | |||||
| Overlap (deg2) | 3.32 | 3.29 | 1.94 | 1.38 | 9.93 | 7.99 |
Overlap between DES deep ugriz measurements and VISTA (Y)JHKs measurements. E2, X3, and C3 refer to the DES supernova fields and |$\mathcal {C}$| to the COSMOS field. There are VISTA Y band measurements in COSMOS, E2, and X3 fields but not in the C3 field. The last column shows the reduced deep field area when using Y band.
| E2 | X3 | C3 | |$\boldsymbol{\mathcal {C}}$| | Total | ||
|---|---|---|---|---|---|---|
| JHKs | YJHKs | |||||
| Overlap (deg2) | 3.32 | 3.29 | 1.94 | 1.38 | 9.93 | 7.99 |
| E2 | X3 | C3 | |$\boldsymbol{\mathcal {C}}$| | Total | ||
|---|---|---|---|---|---|---|
| JHKs | YJHKs | |||||
| Overlap (deg2) | 3.32 | 3.29 | 1.94 | 1.38 | 9.93 | 7.99 |
3.2 Buzzard mock galaxy catalogue
We use the buzzard-v1.6 simulation, a mock DES catalogue created from a set of dark-matter-only simulations (a detailed description of the simulation and the catalogue construction can be found in MacCrann et al. 2018; DeRose et al. 2019, Wechsler et al. in preparation). buzzard-v1.6 is constructed from a set of three N-body simulations run using l-gadget2, a version of gadget2 (Springel 2005) modified for memory efficiency. The simulation box sizes ranged from 1 to 4 h−1Gpc. Light cones from each box were constructed on the fly.
Galaxies are added to the simulations using the Adding Density Dependent GAlaxies to Light-cone Simulations algorithm (addgals; DeRose et al. 2019, Wechsler et al. in preparation). This algorithm pastes galaxies on to dark matter particles in an N-body simulation by matching galaxy luminosities with local dark matter densities. This method does not use dark matter host haloes, which are commonly unresolved for the galaxies and simulations used here. SEDs from a training set of spectroscopic data from SDSS DR7 (Cooper et al. 2011) are assigned to the simulated galaxies to match the colour–environment relation. These SEDs are integrated in the DES pass bands to generate ugriz magnitudes and in the VISTA pass bands to generate YJHKs magnitudes (see Fig. 1). Galaxy sizes and ellipticities are drawn from distributions fit to SuprimeCam i band data (Miyazaki et al. 2002). Galaxies are added to the simulation to the projected apparent magnitude limit of the final DES data set out to redshift z = 2.
The use of SDSS spectra means that the SEDs assigned in Buzzard are limited to bright or low redshift galaxies. In contrast to template fitting methods, the resulting lack of SED evolution with redshift is not a major concern for testing our scheme: there is no assumption made that the same underlying SED exists at different redshifts to produce different but related phenotypes. Changes in galaxy SEDs with redshift could, however, introduce a different degree of type-redshift degeneracy as seen in the mock catalogues, which is a caveat in transferring our findings to real data and should be tested by comparing e.g. the scatter of redshift within SOM cells between mock and data. Note also that as the rest-frame UV part of the SEDs is not recorded by the SDSS spectra, the spectroscopic data must be extrapolated to produce the optical colours at z⪆1.5. The lack of informative colours above this redshift motivates the redshift cut in the samples described below. This may lead to an underestimate of the uncertainty in high-redshift tails. Only a small fraction of observable galaxies in those parts of wide-field colour–magnitude space that provide sufficiently constrained redshift distributions for lensing use in DES Y1 (the analysis of the data taken in the first year of DES) and Y3 lie at z > 1.5 (cf. e.g. Hoyle et al. 2018), but this will change in deeper future data sets. In addition, our error estimates assume that the overall population density and signal-to-noise distribution of Buzzard galaxies as a function of redshift mimics the data, which is only approximately true.
3.2.1 Mock samples in buzzard
Using the buzzard simulated catalogue, we construct the four samples described in Section 3.1.1 to test and refine our method. In the simulations, galaxies are assigned a true redshift ztrue and a true flux in each band. Observed fluxes are derived for each galaxy depending on its position on the sky. The error model used is tailored to match DES wide-field observations. In the following, in order for the simulations to mimic the real data, we will use the simulated true and observed information as deep and wide information, respectively.
We use the true redshift for the redshift sample and to compare our inferred redshift distributions to the true ones. We reiterate that this assumption is likely valid for the brighter subset of existing spectroscopic and many-band photometric redshift samples only (Laigle et al. 2016; Eriksen et al. 2019; Masters et al. 2019), and must be validated when applying any empirical redshift calibration scheme in practice. The simulated true fluxes without errors are used as the deep measurements. This is justified by the significantly longer integrated exposure time of the deep fields relative to the wide survey. We have validated that flux errors at least five times smaller than those that define the limiting magnitudes in Appendix A, applied to the simulated deep field catalogues, do not appreciably affect our redshift calibration. We are actively studying the interplay of deep field flux errors and SOM calibration on Y3 data (Myles et al. in preparation). When the measurements are considered noiseless, |$\mathbf {\Sigma }$| is taken to be the identity matrix when training the SOM (Section 4.1) or when assigning galaxies to the SOM. To mimic the deep and redshift samples, two cuts are performed on the Buzzard catalogue. Only galaxies with true redshift ztrue < 1.5 and true magnitude in i band |$m_{\mathrm{true},\, i}\lt 24.5$| are kept in both samples. The hard boundary at ztrue = 1.5 has its drawbacks (namely, in the reliability of the error estimate of the highest redshift bin) but it ensures that the colours are sufficiently correct which is not the case at high ztrue in the simulations. The redshift sample is expected to be representative of the deep sample at any point in deep multicolour space, as would be the case for COSMOS multiband redshifts.
For the wide sample, we want galaxies whose properties are similar to the ones of galaxies we would use in the DES Y3 cosmology analysis. These galaxies are a subset of all DES Y3 observed galaxies in the wide survey. This subset is the result of both easy-to-mock selections (galaxies with observed magnitude in some band lower than a threshold) and difficult-to-mock selections (cut galaxies which would fail in the shape measurement algorithm). We use the simple selection criterion of observed magnitude in i band |$m_{\mathrm{obs},\, i}\lt 23.5$| to create the wide sample. A more refined selection, which depends on a galaxy’s size and the limiting magnitude in r band of the survey at its position on the sky, is used at the end of this work to check the robustness of our uncertainties estimates (see Section 8.1). The distributions of the observed i band magnitude of those three selections applied to all galaxies in a buzzard tile (∼53 deg2) is shown in Fig. 2.
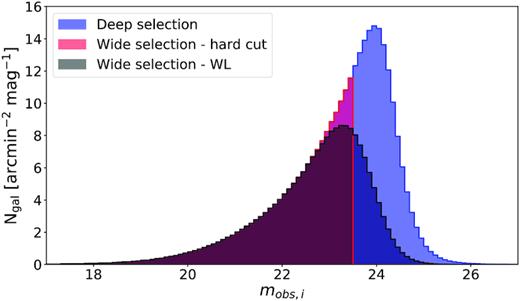
Distribution of the observed i band magnitude of three selections, |$\hat{s}$|, applied to all galaxies in a buzzard tile (∼53 deg2). The deep selection (blue) is ztrue < 1.5 and |$m_{\mathrm{true},\, i}\lt 24.5$|. The hard cut selection (red) is the deep selection plus |$m_{\mathrm{obs},\, i}\lt 23.5$|. The weak lensing (WL) selection (black) uses a more complex criterion based on the size of the galaxy and the limiting magnitude of the DES Y3 survey (see Section 8.1).
To obtain the overlap sample, we apply the same selection criterion as the one used for the wide sample. To mimic the balrog algorithm, we can take the galaxies in the deep sample, randomly select positions over the full Y3 footprint and run the error model at their position to obtain a noisy version of the galaxy. This allows us to have multiple wide realizations of the same galaxy. Only galaxies respecting the wide selection criterion are then selected. The galaxies in the deep sample can be spliced a certain number of times giving an overlap sample of variable size.
In summary, only two selections are performed: a deep and a wide. The first is applied to the redshift and deep samples, the second to the overlap and wide samples.
4 IMPLEMENTATION
As stated in Section 2, a wide variety of clustering methods can be used to achieve the assignment of wide and deep data to cells |$\hat{c}$| and c, respectively. In this work, we use SOMs to obtain both. This choice is motivated by the visual representation offered by this method which helps interpretation and debugging. Also, recent works have shown the capabilities of this algorithm in dealing with photo-zs (see e.g. Carrasco Kind & Brunner 2014; Masters et al. 2015).
4.1 Self-organizing maps
A self-organizing map (SOM) or Kohonen map is a type of artificial neural network that produces a discretized and low-dimensional representation of the input space. Since its introduction by Kohonen (1982), this algorithm has found a large range of scientific applications (see e.g. Kohonen 2001). In astronomy, SOMs have been used in different classification problems: galaxy morphologies (Naim, Ratnatunga & Griffiths 1997), gamma-ray bursts (Rajaniemi & Mähönen 2002), or astronomical light curves (Brett, West & Wheatley 2004). More recently, this method has been used to compute photo-zs: single photo-z estimator (Geach 2012; Way & Klose 2012) and the full redshift PDF (Carrasco Kind & Brunner 2014). It has also been used to characterize the colour-redshift relation to determine relevant spectroscopic targets (Masters et al. 2015) necessary to meet the photo-z precision requirements for weak lensing cosmology for the Euclid survey (Laureijs et al. 2011). This work resulted in the Complete Calibration of the Colour-Redshift Relation (C3R2; Masters et al. 2017) survey, which targets missing regions of colour space.
The SOM algorithm is an unsupervised method (the output variable, in our case the redshift, is not used in training) which produces a direct mapping from the input space to a lower dimensional grid. The training phase is a competitive process whereby cells of the map (more commonly called neurons or nodes) compete to most closely resemble each galaxy of the training data, until the best match is assigned as that galaxy’s phenotype. The SOM is a type of non-linear principal component analysis which preserves separation, i.e. distances in input space are reflected in the map.
Consider a training sample of n galaxies. For each galaxy we can build an m-dimensional input vector |$\mathbf {x} \in \mathbb {R}^m$| made of measured galaxy attributes such as magnitudes, colours, or size (but not the redshift). A SOM is a set of C cells arranged in an l-dimensional grid that has a given topology. Here we consider 2D square maps with periodic boundary conditions (the map resembles a torus). Each cell is associated to a weight vector |$\mathbf {\omega _k} \in \mathbb {R}^m$|, where k = 1, ..., C, that lives in the same space as the input vectors.
4.2 Assignment of galaxies to cells
4.3 Scheme implementation
The computation of the redshift distributions with the pheno-z scheme (see equation 6) is depicted in Fig. 3. To compute p(z|c), a ‘Deep SOM’ is trained using all galaxies in the deep sample. A redshift distribution can be computed for each SOM cell c by assigning the redshift sample to the Deep SOM. A second SOM, the ‘Wide SOM’, is trained on the wide sample. Assignment of the galaxies in this sample to the Wide SOM yields |$p(\hat{c}|\hat{s})$|. The transfer function, |$p(c|\hat{c}, \hat{s})$|, is computed by assigning the galaxies in the overlap sample to the Deep and the Wide SOMs. The tomographic bins are obtained using the procedure described in Section 2.1 using the assignment of the redshift and overlap samples to the Deep SOM as well as the transfer function, |$p(c|\hat{c}, \hat{s})$|.
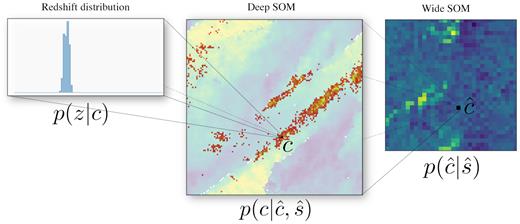
The pheno-z scheme using self-organizing maps (SOMs). This illustration depicts the estimation of redshift distributions using equation (6). The Wide and Deep SOMs are trained using the wide and deep samples, respectively. The term p(z|c) is computed using the assignment of the redshift sample to the Deep SOM. For each cell c, a normalized redshift histogram is computed using the galaxies assigned to the cell. The transfer function, |$p(c|\hat{c},\hat{s})$|, is obtained by assigning the overlap sample to both the Wide and Deep SOMs. For all galaxies assigned to a cell |$\hat{c}$|, the probability of belonging to any cell c can be computed. The last piece of our scheme, |$p(\hat{c}|\hat{s})$|, is the fractional occupation of the wide sample in the Wide SOM.
The last piece of our scheme is the redshift distribution p(z|c) of deep cell c. We use the assignment of the redshift sample to the deep cells c. For each cell c, we compute p(z|c) as a normalized redshift histogram with bin spacing Δz = 0.02. This resolution is sufficient since we only use combinations of these histograms, corresponding to wide-field bins with relatively wide redshift distributions, for our metrics.
5 FIDUCIAL SOMS
We must choose the features (Section 5.1) used to train the SOMs as well as their hyperparameters (Section 5.2), i.e. parameters whose values are not learned during the training process. Intuition guides the search for the best parameters but empirical evidence settles the final choices. The choice of the number of cells for both SOMs is specific to the samples available in DES Y3.
5.1 Choice of features
Luptitudes could be used as entries of the input vector, |$\boldsymbol {x}$|, but for a sufficient set of measured colours we expect most of the information regarding redshift to lie in the shape of the SED. The flux of a galaxy in this case is only a weak prior on its redshift. We find that in practice the addition of total flux (or magnitude) to the Deep SOM does not improve the performance of the algorithm. Ratios of fluxes (or equivalently difference of magnitudes) appear to encode the most relevant information to discriminate redshifts and types. Similar to colour, which is a difference of magnitudes, we can define ‘lupticolour’ which is a difference of luptitudes. For high signal-to-noise ratios, a lupticolour is equivalent to the ratio of fluxes. For noisy detections, it becomes the preferable flux difference.
Our tests show that adding a luptitude to the input vector of the deep SOM slightly decreases the ability of the method to estimate the redshift distributions whereas for the Wide SOM, it improves it. The difference lies in the number of bands available. The deep input vector has eight lupticolours which are enough to characterize the redshift of the galaxy. For the wide input vector with only three lupticolours, the luptitude adds information and helps break degeneracies at low redshift.
5.2 Choice of hyperparameters
As presented in Section 4.1, the SOM has various hyperparameters. Apart from one key parameter, the number of cells in the SOM, both the wide and the Deep SOMs share the same hyperparameters.
The topology of the 2D grid (square, rectangular, spherical, or hexagonal), the boundary conditions (periodic or not) as well as the number of cells must be decided. Carrasco Kind & Brunner (2014) showed that spherical or rectangular grids with periodic boundary conditions performed better. The drawback of the spherical topology is that the number of cells cannot be easily tuned. This leads us to choose the square grid with periodic boundary conditions.
Our pheno-z scheme assumes that |$p(z|c,\hat{c}, \hat{s})=p(z|c)$|, i.e. once the assignment to a Deep SOM cell, c, is known, a galaxy’s noisy photometry, embodied by its assignment to the Wide SOM cell, |$\hat{c}$|, does not add information. This is only true if the cell c represents a negligible volume in the griz colour space compared to the photometric uncertainty. This assumption requires a sufficient number of Deep SOM cells. A second assumption of our method is that we have a p(z|c) for each Deep SOM cell, c, which is only true if we have a sufficient number of galaxies with redshifts to sample the distribution in each cell. While for a narrow distribution p(z|c) a small number of galaxies suffices, this still limits the number of Deep SOM cells. Those two competing effects lead us to set the Deep SOM to a 128 by 128 grid (16 384 cells). This setup reduces the number of empty cells for a COSMOS-like redshift sample (∼135 000 galaxies) while producing rather sharp phenotypes, i.e. the volume of each cell in colour space is small.
The number of cells of the Wide SOM is dictated by the photometric uncertainty in the wide measurements. By scanning over the number of Wide SOM cells, we found that a 32 by 32 grid offers a sufficient amount of cells to describe the possible phenotypes observed in the wide survey, and that larger numbers of cells did not significantly change the calibration.
The pheno-z method is robust to other available hyperparameters. The learning rate, a0, which governs how much each step in the training process affects the map, has a negligible impact unless we choose extreme values (0.01, 0.99). It is set to a0 = 0.5. The initial width of the neighbourhood function, σs, is set to the full size of the SOM. This allows the first training vectors to affect the whole map. The maximum number of training steps, tmax, must be large enough such that the SOM converges. By scanning over tmax, we found that two million steps are sufficient.
We also looked at 3D SOMs and found that an extra dimension for the same number of cells had a negligible impact on the results.
5.3 Validation of the fiducial SOMs
Our fiducial pheno-z scheme uses a 128 by 128 lupticolour Deep SOM and a 32 by 32 lupticolour–luptitude Wide SOM. In Appendix B, we present the assessment of this choice on our redshift calibration procedure. Using other feature combinations for the deep and Wide SOMs results in a similar calibration. The feature selection does not matter much but our choice has the conceptual advantages described in Section 5.1. While using a limited redshift sample, increasing the number of cells of the Deep SOM leads to a higher calibration error whereas increasing the number of cells of the Wide SOM does not affect it.
6 PHENO-Z SCHEME PERFORMANCE WITH UNLIMITED SAMPLES
In this section, we use our pheno-z scheme with the fiducial SOMs presented in the preceding section to test its capabilities. We show that, with large enough redshift, deep, and overlap samples, the choices made in the methodology allow a redshift calibration without relevant biases. The effect of limited samples is evaluated separately in Section 7.
These metrics are the calibration error of the method. Averaging them over many (hypothetical) random realizations of a survey gives the bias of the method. In the Y1 analysis, the detailed shape of the redshift distributions had little impact. Switching the redshift distribution shape directly estimated from resampled COSMOS objects (Hoyle et al. 2018) to the one estimated using Bayesian Photometric Redshifts (BPZ; Benítez 2000), a template fitting method, had little impact on the cosmological inference from cosmic shear as long as the mean redshift of the distributions agreed within uncertainties (Troxel et al. 2018). This is consistent with the finding of Bonnett et al. (2016) for the DES Science Verification analysis. For future, statistically improved, lensing measurements, this simplification may however become invalid. We therefore focus our attention on the first metric for tuning and validating the method, but aim to be able to characterize the biases in general (i.e. in terms of possible realizations of the redshift distributions).
The bias is determined under ‘perfect’ conditions that are defined by the following requirements: the redshift sample is identical to the deep sample, the overlap sample is identical to the wide sample, and both are large. The galaxies of all samples are randomly sampled from the full DES Y3 footprint. We use our usual selection mobs, i < 23.5 for the wide/overlap sample. A hundred iterations of this best case scenario are run where the redshift/deep sample is made of 106 galaxies and the wide/overlap sample is made of 2 × 106 galaxies. Table 2 presents the means of the metrics defined in equation (20) for this best case scenario for our fiducial lupticolour 128 by 128 Deep SOM coupled to a lupticolour–luptitude 32 by 32 Wide SOM. For comparison the same test is performed with a lupticolour 256 by 256 Deep SOM. As expected, from the reduction of biases related to discretization, increasing the number of cells in the Deep SOM results in a lower bias. This means that there are more than 16 384 possible phenotypes (as the 128 by 128 Deep SOM has 16 384 cells). The first two bins are the most affected: increasing the number of cells by a factor of four reduces the bias, 〈Δ〈z〉〉, by a factor of two. Note that this increase in resolution is only possible with the idealized, large redshift/deep sample used in this test. If our available redshift sample were larger, we would use a larger SOM.
Bias of the pheno-z method in the best case scenario of a large redshift sample. Shown are the biases on mean redshift of tomographic bins, 〈Δ〈z〉〉, and width of redshift distribution of a bin, 〈Δσ(z)〉. The fiducial 128 by 128 Deep SOM is compared to a 256 by 256 Deep SOM. For such a large redshift sample, the increased number of Deep SOM cells is beneficial. Note that the standard deviation of both metrics in this best case scenario is an order of magnitude smaller than their means. The mean of the true redshift distribution in each bin, 〈ztrue〉, is also shown.
| metric | size | Bin 1 | Bin 2 | Bin 3 | Bin 4 | Bin 5 |
|---|---|---|---|---|---|---|
| 〈ztrue〉 | 0.34 | 0.48 | 0.68 | 0.87 | 1.07 | |
| 〈Δ〈z〉〉 | 128 | −0.0050 | −0.0024 | 0.0001 | 0.0025 | 0.0024 |
| 256 | −0.0026 | −0.0010 | 0.0003 | 0.0018 | 0.0020 | |
| 〈Δσ(z)〉 | 128 | −0.0039 | −0.0027 | −0.0029 | −0.0018 | −0.0014 |
| 256 | −0.0023 | −0.0015 | −0.0015 | −0.0009 | −0.0003 | |
| metric | size | Bin 1 | Bin 2 | Bin 3 | Bin 4 | Bin 5 |
|---|---|---|---|---|---|---|
| 〈ztrue〉 | 0.34 | 0.48 | 0.68 | 0.87 | 1.07 | |
| 〈Δ〈z〉〉 | 128 | −0.0050 | −0.0024 | 0.0001 | 0.0025 | 0.0024 |
| 256 | −0.0026 | −0.0010 | 0.0003 | 0.0018 | 0.0020 | |
| 〈Δσ(z)〉 | 128 | −0.0039 | −0.0027 | −0.0029 | −0.0018 | −0.0014 |
| 256 | −0.0023 | −0.0015 | −0.0015 | −0.0009 | −0.0003 | |
Bias of the pheno-z method in the best case scenario of a large redshift sample. Shown are the biases on mean redshift of tomographic bins, 〈Δ〈z〉〉, and width of redshift distribution of a bin, 〈Δσ(z)〉. The fiducial 128 by 128 Deep SOM is compared to a 256 by 256 Deep SOM. For such a large redshift sample, the increased number of Deep SOM cells is beneficial. Note that the standard deviation of both metrics in this best case scenario is an order of magnitude smaller than their means. The mean of the true redshift distribution in each bin, 〈ztrue〉, is also shown.
| metric | size | Bin 1 | Bin 2 | Bin 3 | Bin 4 | Bin 5 |
|---|---|---|---|---|---|---|
| 〈ztrue〉 | 0.34 | 0.48 | 0.68 | 0.87 | 1.07 | |
| 〈Δ〈z〉〉 | 128 | −0.0050 | −0.0024 | 0.0001 | 0.0025 | 0.0024 |
| 256 | −0.0026 | −0.0010 | 0.0003 | 0.0018 | 0.0020 | |
| 〈Δσ(z)〉 | 128 | −0.0039 | −0.0027 | −0.0029 | −0.0018 | −0.0014 |
| 256 | −0.0023 | −0.0015 | −0.0015 | −0.0009 | −0.0003 | |
| metric | size | Bin 1 | Bin 2 | Bin 3 | Bin 4 | Bin 5 |
|---|---|---|---|---|---|---|
| 〈ztrue〉 | 0.34 | 0.48 | 0.68 | 0.87 | 1.07 | |
| 〈Δ〈z〉〉 | 128 | −0.0050 | −0.0024 | 0.0001 | 0.0025 | 0.0024 |
| 256 | −0.0026 | −0.0010 | 0.0003 | 0.0018 | 0.0020 | |
| 〈Δσ(z)〉 | 128 | −0.0039 | −0.0027 | −0.0029 | −0.0018 | −0.0014 |
| 256 | −0.0023 | −0.0015 | −0.0015 | −0.0009 | −0.0003 | |
7 SOURCES OF UNCERTAINTY DUE TO LIMITED SAMPLES
Deep multiband observations and, more so, observations that accurately determine galaxy redshifts with spectroscopy or otherwise, require substantial telescope resources. As a result, in practice, deep and redshift samples are limited in galaxy count and area. In this section, we determine the impact of these limited samples on redshift calibration using our scheme.
Limited samples can impact redshift calibration both as a statistical error – i.e. depending on the field or sample of galaxies chosen for deep and redshift observations – or as a systematic error – i.e. as a bias due to the limited resolution by which galaxies sample colour space (see also Section 6). We use the metrics presented in equation (20) to assess this limitation: 〈Δ〈z〉〉 over many realizations of our samples assesses the systematic error in mean redshift, whereas σ(Δ〈z〉) is a statistical error due to variance in the samples used.
To this end, we use the buzzard simulated catalogues to assess systematic and statistical errors. Each source of uncertainty, i.e. the effect of limiting each sample, is separately probed in the sub-sections below. At each iteration of a test, only the sample of interest is modified and the other fixed samples are sampled randomly over the full DES footprint and with a sufficient number to avoid a sample variance or shot noise contribution. In Section 7.5, we discuss the perhaps counter-intuitive finding that the statistical error in a realistic use case is limited by the size of the deep sample, not the redshift sample.
7.1 Limited redshift sample
The redshift sample used to estimate p(z|c) is limited in two ways. First, it contains a finite number of galaxies; second, the galaxies it contains come from a small field on the sky: COSMOS. This implies that the scatter of the redshift calibration error, σ(Δ〈z〉), has contributions from shot noise and sample variance, respectively.
7.1.1 Shot noise
One can assess the effect of shot noise in the redshift sample by computing the redshift distribution of a sample of galaxies many times using our pheno-z method. At each iteration we randomly select a fixed number of galaxies for our redshift sample. In this test, we do not want to include sample variance, thus the redshift sample is also composed of galaxies randomly selected over the full DES footprint.
The left-hand panel of Fig. 4 shows the shot noise as a function of the number of galaxies in the redshift sample. If the number of galaxies is too low, there is a significant scatter in Δ〈z〉, but with more than ∼105 galaxies, the scatter reaches a plateau at the 2–4 × 10−4 level which is well below our requirements (σΔz ∼ 0.01). Note that the first and last bins exhibit more shot noise probably due to the hard boundaries at z = 0 and z = 1.5.
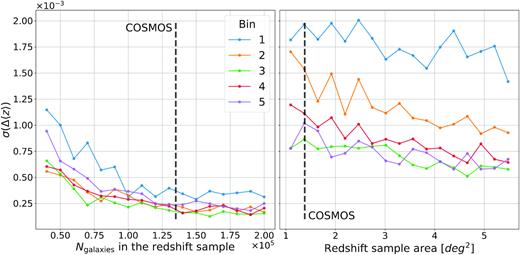
Shot noise due to limited sample size (left-hand panel) compared to the sample variance due to limited sample area (right-hand panel) in the redshift sample. The grey dashed line highlights the number of galaxies in the COSMOS field and its size. The standard deviation of the difference in mean redshift between the true and estimated distribution over 100 iterations is plotted. Left-hand panel: Effect of shot noise as a function of the number of galaxies in the redshift sample. The galaxies used to compute p(z|c) are sampled from the whole sky to avoid any sample variance contribution. Above ∼105 galaxies, increasing the number of objects does not yield a significant improvement. Right-hand panel: Effect of sample variance as a function of redshift field area sampled. One hundred thousand galaxies are sampled over different contiguous areas. The calibration of redshift distribution with the pheno-z scheme is not limited by the number of galaxies in COSMOS but by their common location on the same line of sight.
7.1.2 Sample variance
This effect stems from the fact that the selection of galaxies depends on the environment: as the matter field is not homogeneous on small scales, different lines of sight have different distributions of galaxies.
With a redshift sample that is small on the sky, subsets of galaxies contained in this sample have the same environment which influences their overall properties (notably redshift and colours). This sample variance was a major limitation in the DES Y1 redshift calibration. To test the effect of sample variance we can repeat our calibration method many times with a redshift sample coming from a different part of the sky at each iteration. The top plot in Fig. 5 shows the result of one iteration with a redshift sample made of 135 000 galaxies sampled from a 1.38 deg2 field. The estimated distribution has many spikes. Those are caused by the incomplete population of galaxies in the sample: galaxies have similar redshifts and colours. Many Deep SOM cells that should have broader redshift distributions end up being peaked due to the presence of a galaxy cluster in the redshift field. When the redshift sample is limited to a small field on the sky, the p(z|c) is strongly structured by sample variance.
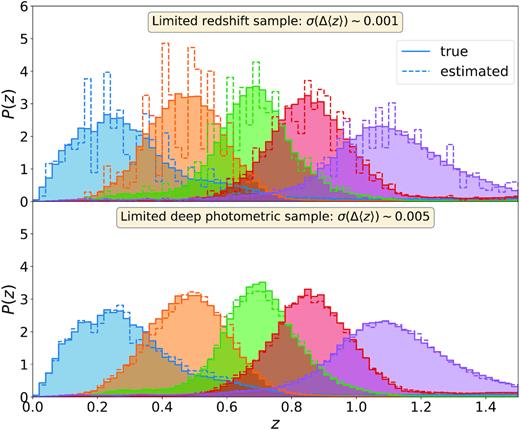
Top panel: Impact of limited redshift sample in the redshift distribution calibration. The redshift sample is made of 135 000 galaxies sampled from a 1.38 deg2 field. The spikes in the estimated distributions are due to the particular redshift distribution of this small area. Bottom panel: Impact of limited deep sample in the redshift distribution calibration. The deep field is made of three fields of 3.32, 3.29, and 1.38 deg2, respectively. Each deep field galaxy is painted 10 times at random positions over the whole DES footprint to yield an overlap sample of ∼4.6 × 106 galaxies. Although the redshift distributions do not exhibit the spikes visible in the upper panel, the scatter of the calibration error, Δ〈z〉, is three to five times larger, meaning that the sample variance in the deep sample dominates over the one in the redshift sample.
We test the effect of sample variance as a function of the redshift field area available. To avoid shot noise effects, we sample the same number of galaxies for redshift fields of different sizes. The sample variance is measured as the standard deviation of the difference between the mean of the true redshift distribution and the mean of the pheno-z estimation. As expected, it decreases as the area increases. This effect is shown in the right-hand panel of Fig. 4 for a fixed number of galaxies of 105. The first tomographic bin has a higher level of sample variance because of higher density fluctuations due to the smaller volume at low redshift.
For the DES Y3 calibration, we expect that the redshift sample will contain about 135 000 galaxies in a 1.38 deg2 field from COSMOS. The expected sample variance from such a field is quoted in Table 3 for two different sets of VISTA bands used. Using the Y band, we expect uncertainties of the order σ(Δ〈 z〉) ∼ 0.001 from sample variance alone. Relative to Section 7.1.1, we find that for COSMOS, this effect dominates by a factor of five, compared to shot noise. For comparison, DES Y1 redshift calibration (Hoyle et al. 2018) achieved a typical σ(Δ〈 z〉) ∼ 0.02, with sample variance (labelled ‘COSMOS footprint sampling’ in their table 2) contributing ∼0.007 in quadrature to the uncertainty. Despite using an identical sample of galaxies as Hoyle et al. ( 2018), our pheno-z method reveals a net reduction of the sample variance in the COSMOS redshift information, owing to augmentation of the estimate of multicolour density of galaxies with a larger, purely photometric, deep sample. The main source of sample variance is the limited size of the deep sample (Section 7.3) which, however, can be more easily extended than the redshift sample.
Sources of bias and uncertainty of redshift calibration with the pheno-z scheme. Δ〈z〉 is the difference between the means of the true and estimated redshift distribution. The mean (i.e. bias) and standard deviation of this metric over 100 iterations are shown, with the last column (in bold) showing the root-mean-square of the latter over the tomographic bins. To isolate the effect of limited redshift and limited deep samples, only one sample is modified in each iteration. All other samples are fixed, sufficiently large, and sampled from the whole DES footprint. The upper two and lower two lines show the impact of using VISTA Y band in our pheno-z scheme. Using it reduces the area of deep field available but improves deep colour information. For the limited redshift sample, 135 000 galaxies are sampled from the 1.38 deg2 field.
| Test | |$\boldsymbol{\langle \Delta \langle z \rangle \rangle }$| in bin | |$\boldsymbol{\sigma (\Delta \langle z \rangle)}$| in bin | |$\boldsymbol{\sigma _{\mathrm{RMS}}(\Delta \langle z \rangle)}$| | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| VISTA bands | Sample | Size (deg2) | 1 | 2 | 3 | 4 | 5 | 1 | 2 | 3 | 4 | 5 | |
| YJHKs | Redshift | 1.38 | −0.0051 | −0.0024 | −0.0006 | 0.0021 | 0.0022 | 0.0016 | 0.0014 | 0.0008 | 0.0010 | 0.0008 | 0.0012 |
| Deep | 7.99 | −0.0062 | −0.0049 | −0.0006 | 0.0020 | 0.0047 | 0.0077 | 0.0042 | 0.0031 | 0.0026 | 0.0036 | 0.0046 | |
| JHKs | Redshift | 1.38 | −0.0054 | −0.0027 | −0.0001 | 0.0028 | 0.0048 | 0.0017 | 0.0015 | 0.0007 | 0.0008 | 0.0010 | 0.0012 |
| Deep | 9.93 | −0.0050 | −0.0049 | −0.0002 | 0.0017 | 0.0078 | 0.0065 | 0.0037 | 0.0027 | 0.0027 | 0.0032 | 0.0040 | |
| Test | |$\boldsymbol{\langle \Delta \langle z \rangle \rangle }$| in bin | |$\boldsymbol{\sigma (\Delta \langle z \rangle)}$| in bin | |$\boldsymbol{\sigma _{\mathrm{RMS}}(\Delta \langle z \rangle)}$| | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| VISTA bands | Sample | Size (deg2) | 1 | 2 | 3 | 4 | 5 | 1 | 2 | 3 | 4 | 5 | |
| YJHKs | Redshift | 1.38 | −0.0051 | −0.0024 | −0.0006 | 0.0021 | 0.0022 | 0.0016 | 0.0014 | 0.0008 | 0.0010 | 0.0008 | 0.0012 |
| Deep | 7.99 | −0.0062 | −0.0049 | −0.0006 | 0.0020 | 0.0047 | 0.0077 | 0.0042 | 0.0031 | 0.0026 | 0.0036 | 0.0046 | |
| JHKs | Redshift | 1.38 | −0.0054 | −0.0027 | −0.0001 | 0.0028 | 0.0048 | 0.0017 | 0.0015 | 0.0007 | 0.0008 | 0.0010 | 0.0012 |
| Deep | 9.93 | −0.0050 | −0.0049 | −0.0002 | 0.0017 | 0.0078 | 0.0065 | 0.0037 | 0.0027 | 0.0027 | 0.0032 | 0.0040 | |
Sources of bias and uncertainty of redshift calibration with the pheno-z scheme. Δ〈z〉 is the difference between the means of the true and estimated redshift distribution. The mean (i.e. bias) and standard deviation of this metric over 100 iterations are shown, with the last column (in bold) showing the root-mean-square of the latter over the tomographic bins. To isolate the effect of limited redshift and limited deep samples, only one sample is modified in each iteration. All other samples are fixed, sufficiently large, and sampled from the whole DES footprint. The upper two and lower two lines show the impact of using VISTA Y band in our pheno-z scheme. Using it reduces the area of deep field available but improves deep colour information. For the limited redshift sample, 135 000 galaxies are sampled from the 1.38 deg2 field.
| Test | |$\boldsymbol{\langle \Delta \langle z \rangle \rangle }$| in bin | |$\boldsymbol{\sigma (\Delta \langle z \rangle)}$| in bin | |$\boldsymbol{\sigma _{\mathrm{RMS}}(\Delta \langle z \rangle)}$| | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| VISTA bands | Sample | Size (deg2) | 1 | 2 | 3 | 4 | 5 | 1 | 2 | 3 | 4 | 5 | |
| YJHKs | Redshift | 1.38 | −0.0051 | −0.0024 | −0.0006 | 0.0021 | 0.0022 | 0.0016 | 0.0014 | 0.0008 | 0.0010 | 0.0008 | 0.0012 |
| Deep | 7.99 | −0.0062 | −0.0049 | −0.0006 | 0.0020 | 0.0047 | 0.0077 | 0.0042 | 0.0031 | 0.0026 | 0.0036 | 0.0046 | |
| JHKs | Redshift | 1.38 | −0.0054 | −0.0027 | −0.0001 | 0.0028 | 0.0048 | 0.0017 | 0.0015 | 0.0007 | 0.0008 | 0.0010 | 0.0012 |
| Deep | 9.93 | −0.0050 | −0.0049 | −0.0002 | 0.0017 | 0.0078 | 0.0065 | 0.0037 | 0.0027 | 0.0027 | 0.0032 | 0.0040 | |
| Test | |$\boldsymbol{\langle \Delta \langle z \rangle \rangle }$| in bin | |$\boldsymbol{\sigma (\Delta \langle z \rangle)}$| in bin | |$\boldsymbol{\sigma _{\mathrm{RMS}}(\Delta \langle z \rangle)}$| | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| VISTA bands | Sample | Size (deg2) | 1 | 2 | 3 | 4 | 5 | 1 | 2 | 3 | 4 | 5 | |
| YJHKs | Redshift | 1.38 | −0.0051 | −0.0024 | −0.0006 | 0.0021 | 0.0022 | 0.0016 | 0.0014 | 0.0008 | 0.0010 | 0.0008 | 0.0012 |
| Deep | 7.99 | −0.0062 | −0.0049 | −0.0006 | 0.0020 | 0.0047 | 0.0077 | 0.0042 | 0.0031 | 0.0026 | 0.0036 | 0.0046 | |
| JHKs | Redshift | 1.38 | −0.0054 | −0.0027 | −0.0001 | 0.0028 | 0.0048 | 0.0017 | 0.0015 | 0.0007 | 0.0008 | 0.0010 | 0.0012 |
| Deep | 9.93 | −0.0050 | −0.0049 | −0.0002 | 0.0017 | 0.0078 | 0.0065 | 0.0037 | 0.0027 | 0.0027 | 0.0032 | 0.0040 | |
7.2 Limited overlap sample
We estimate the overlap sample by drawing galaxies from the deep fields (i.e. the overlap between deep DES ugriz and VISTA YJHKs or JHKs; see Section 3.1.1) over the full DES footprint with the balrog algorithm. In this section we test what size of the overlap sample is required.
We assume the deep sample is artificially drawn at random locations over the footprint, with N realizations of each galaxy over the full footprint. N must be sufficient to provide enough deep-wide tuples to populate the transfer function, |$p(c|\hat{c},\hat{s})$|, and avoid noise introduced by unevenly sampling observing conditions.
Our investigation shows that increasing N from 5 to 50 has no impact on the mean and standard deviation of the calibration error, Δ〈z〉. We thus use 10 realizations at different random positions (i.e. with different noise realizations) of each deep field galaxy. This corresponds to 1–2 per cent ratio of galaxy count in the overlap to wide sample for DES Y3.
7.3 Limited deep sample
The overlap sample used to compute the transfer function, |$p(c|\hat{c},\hat{s})$|, is limited by the deep sample. Indeed, balrog takes as input the galaxies measured in the deep survey, which spans only a limited area (see Section 3.1.1). We first look at the sample variance in the overlap sample due to the limited area of the deep sample. Secondly, we look at the trade-offs between the number of VISTA bands used and the area available.
7.3.1 Sample variance
As the area is bigger than the one of the redshift sample, we might expect less sample variance coming from the overlap sample. Unfortunately, that is not the case. The transfer function is sensitive to changes in |$p(c, \hat{c})$| due to sample variance. Although the reconstructed redshift distributions, shown on the bottom plot in Fig. 5, do not exhibit the spikes produced by the limited redshift sample shown on the top plot, the scatter of the calibration error, Δ〈 z〉, is three to five times larger, as reported in Table 3. The sample variance of the deep sample dominates over that of the redshift sample. We are learning a noisy realization of the distribution of multiband deep colours given a wide-field flux measurement, and so are incorrectly learning the distribution of SEDs given our selection and observed galaxy colours.
7.3.2 Number of bands versus deep area
As described in Section 3.1.1 and Table 1, depending on which VISTA bands are used the available area in the deep sample will be different. Either we use YJHKs and have 7.99 deg2 of deep fields in three places or we drop the Y band and have 9.93 deg2 in four fields. Those two possibilities are tested empirically.
We repeat the tests performed on the limited redshift sample (Section 7.1) and on the limited deep sample (Section 7.3) without the Y band and with the increased area. The results, shown in Table 3, show two opposite trends. The bias, 〈Δ〈z〉〉, is significantly larger without the Y band for the last bin and almost unchanged for the other bins. At large redshift, the Y band provides valuable information necessary to estimate correctly the redshift distribution. The bias is not sensitive to the area used but to the number of bands available. On the contrary, the variance of the calibration error is affected by the size of the deep field. Without the Y band, the standard deviation of the calibration error, σ(Δ〈z〉), is smaller by about 15 per cent because this option provides a larger deep field area.
The two effects – a bigger deep field area and one less band – have opposite impact of about the same amplitude. A reduction in bias in the high redshift bin is particularly beneficial and thus may favour including Y.
7.4 Impact of empty Deep SOM cells
When computing the redshift distributions using equation (6), the |$p(c_e|\hat{c},\hat{s})$| of empty cells, ce, is set to zero. To check that this does not introduce a bias, we compute the ‘true’ redshift distributions of the empty cells by assigning a sample of 5 × 105 galaxies to the Deep SOM. A redshift distribution is obtained for the initially empty cells and used in our |$p(z|\hat{B}, \hat{s})$| computation. In Table 4, we compare the resulting bias in the two cases: with empty cells ignored and with empty cells filled with a large number of galaxies to be as close to the ‘true’ redshift distribution as we can get. This latter method is equivalent to a ‘perfect’ interpolation to the empty cells. We therefore conclude that ignoring empty cells does not introduce a relevant bias. In practice, since larger numbers of cells could be empty in the case of sparse redshift samples, and since spectroscopic samples (rather than complete redshifts over a field) may suffer selection biases, the impact of cells without redshift information should be checked.
Setting the p(ce) of empty Deep SOM cells, ce, to zero does not introduce a bias. The bias, 〈Δ〈z〉〉, and standard deviation of the calibration error, σ(Δ〈z〉), in five tomographic bins is computed over 162 iterations of our pheno- z scheme with a different 1.38 deg2 redshift sample at each iteration. The redshift distribution of empty Deep SOM cells, p(z|ce), is either set to zero or filled with the redshifts of a large sample of galaxies.
| metric | |$\boldsymbol{p(z|c_e)}$| | Bin 1 | Bin 2 | Bin 3 | Bin 4 | Bin 5 |
|---|---|---|---|---|---|---|
| 〈Δ〈z〉〉 | Set to 0 | −0.0080 | −0.0038 | 0.0004 | 0.0013 | 0.0039 |
| Filled | −0.0078 | −0.0038 | 0.0007 | 0.0017 | 0.0043 | |
| σ(Δ〈z〉) | Set to 0 | 0.0017 | 0.0014 | 0.0008 | 0.0011 | 0.0008 |
| Filled | 0.0014 | 0.0012 | 0.0005 | 0.0008 | 0.0006 |
| metric | |$\boldsymbol{p(z|c_e)}$| | Bin 1 | Bin 2 | Bin 3 | Bin 4 | Bin 5 |
|---|---|---|---|---|---|---|
| 〈Δ〈z〉〉 | Set to 0 | −0.0080 | −0.0038 | 0.0004 | 0.0013 | 0.0039 |
| Filled | −0.0078 | −0.0038 | 0.0007 | 0.0017 | 0.0043 | |
| σ(Δ〈z〉) | Set to 0 | 0.0017 | 0.0014 | 0.0008 | 0.0011 | 0.0008 |
| Filled | 0.0014 | 0.0012 | 0.0005 | 0.0008 | 0.0006 |
Setting the p(ce) of empty Deep SOM cells, ce, to zero does not introduce a bias. The bias, 〈Δ〈z〉〉, and standard deviation of the calibration error, σ(Δ〈z〉), in five tomographic bins is computed over 162 iterations of our pheno- z scheme with a different 1.38 deg2 redshift sample at each iteration. The redshift distribution of empty Deep SOM cells, p(z|ce), is either set to zero or filled with the redshifts of a large sample of galaxies.
| metric | |$\boldsymbol{p(z|c_e)}$| | Bin 1 | Bin 2 | Bin 3 | Bin 4 | Bin 5 |
|---|---|---|---|---|---|---|
| 〈Δ〈z〉〉 | Set to 0 | −0.0080 | −0.0038 | 0.0004 | 0.0013 | 0.0039 |
| Filled | −0.0078 | −0.0038 | 0.0007 | 0.0017 | 0.0043 | |
| σ(Δ〈z〉) | Set to 0 | 0.0017 | 0.0014 | 0.0008 | 0.0011 | 0.0008 |
| Filled | 0.0014 | 0.0012 | 0.0005 | 0.0008 | 0.0006 |
| metric | |$\boldsymbol{p(z|c_e)}$| | Bin 1 | Bin 2 | Bin 3 | Bin 4 | Bin 5 |
|---|---|---|---|---|---|---|
| 〈Δ〈z〉〉 | Set to 0 | −0.0080 | −0.0038 | 0.0004 | 0.0013 | 0.0039 |
| Filled | −0.0078 | −0.0038 | 0.0007 | 0.0017 | 0.0043 | |
| σ(Δ〈z〉) | Set to 0 | 0.0017 | 0.0014 | 0.0008 | 0.0011 | 0.0008 |
| Filled | 0.0014 | 0.0012 | 0.0005 | 0.0008 | 0.0006 |
Some of the cells (∼50) remain empty even when the very large sample is assigned to the Deep SOM. Those cells are often located where there is a sharp colour and redshift gradient. This results from the SOM training: both sides of the boundary evolve differently pulling the cells to empty regions of colour space. These cells are not a problem in our scheme as they never enter any computation.
7.5 Discussion of statistical error budget
The comparison of Sections 7.1 and 7.3 shows that the limited area of the deep photometric sample is dominating the statistical error budget of redshift calibration for a DES-like setting, by a factor of several, rather than the limited size of a COSMOS-like redshift sample (see Fig. 5).
This finding can be understood from the role of these samples in our scheme. The redshift sample informs the redshift distribution of galaxies at given multiband colour. Because at most multiband colours this redshift distribution is narrow, there is little room for sample variance – regardless of their position in the sky, any set of redshift galaxies of the same multiband colour will be very similar in mean redshift. Increasing the number of accurate redshifts, or spreading them over a larger area, reduces this variance further (see Fig. 4), but it is already at a tolerable level for a COSMOS-like sample.
The deep sample, while not adding accurate redshift information, constrains the density of galaxies in multiband colour space, i.e. the mix of multiband colours that corresponds to a given few-band colour observed in the wide field. Uncertain information about this distribution can be seen as an incorrect prior on the abundance of galaxy templates, causing an inaccurate breaking of the type/redshift degeneracy.
This finding represents an opportunity: by separating the abundance aspect of sample variance from the redshift sample, it allows us to augment the scarce information on accurate galaxy redshifts with a larger, complete sample for which deep multiband photometry can be acquired with relatively modest observational effort.
8 IMPACT OF ANALYSIS CHOICES FOR DES Y3 WEAK LENSING
In this section, we assess the robustness of our method when the quality of the inputs decreases. We first test a more realistic selection, |$\hat{s}$|, for the wide and overlap samples in Section 8.1. The metacalibration (Huff & Mandelbaum 2017; Sheldon & Huff 2017) weak lensing analysis requires the use of fluxes measured by the shape measurement algorithm to correct for selection biases. We test the effect of this noisier photometry in Section 8.2. Finally, we test the possibility of dropping the g band in the Wide SOM in Section 8.3. The combined effect of these realistic conditions is discussed in Section 9.
We compare those variations of the scheme to a ‘standard’ pheno-z scheme which uses DES ugriz and VISTA YJHKs bands for the Deep SOM and DES griz for the Wide SOM, a 1.38 deg2 redshift sample, a 7.99 deg2 deep sample, and a hard cut mobs, i < 23.5 as the wide selection. In this standard scheme, 10 realizations of each deep field galaxy at different random positions constitute the overlap sample. The usual metrics for this standard scheme are presented in Table 5.
Comparison of the standard pheno-z scheme to various variations of the scheme. The standard scheme uses DES ugriz and VISTA YJHKs bands for the Deep SOM and DES griz for the Wide SOM. It uses a redshift sample made of 135 000 galaxies sampled from a 1.38 deg2 field, a 7.99 deg2 deep sample, and a hard cut mobs, i < 23.5 for the wide selection. In this standard scheme, 10 realizations of each deep field galaxy at different random positions constitute the overlap sample. The mean and standard deviation of the metrics given in equation (20) over 100 iterations are presented.
| Variation | Bin 1 | Bin 2 | Bin 3 | Bin 4 | Bin 5 | Bin 1 | Bin 2 | Bin 3 | Bin 4 | Bin 5 |
|---|---|---|---|---|---|---|---|---|---|---|
| |$\boldsymbol{\langle \Delta \langle z \rangle \rangle }$| | |$\boldsymbol{\sigma (\Delta \langle z \rangle)}$| | |||||||||
| Standard | −0.0073 | −0.0040 | 0.0006 | 0.0016 | 0.0056 | 0.0077 | 0.0042 | 0.0028 | 0.0033 | 0.0037 |
| w/ weak lensing selectiona | −0.0057 | −0.0040 | 0.0003 | 0.0027 | 0.0057 | 0.0083 | 0.0046 | 0.0042 | 0.0030 | 0.0042 |
| w/ metacalibration fluxesb | −0.0089 | −0.0044 | 0.0001 | 0.0022 | 0.0069 | 0.0077 | 0.0049 | 0.0039 | 0.0033 | 0.0037 |
| w/ only rizc | −0.0070 | −0.0050 | 0.0019 | 0.0006 | 0.0061 | 0.0071 | 0.0051 | 0.0036 | 0.0036 | 0.0038 |
| w/ decreased softening parameterd | −0.0074 | −0.0053 | −0.0012 | −0.0005 | 0.0044 | 0.0072 | 0.0040 | 0.0034 | 0.0028 | 0.0033 |
| |$\boldsymbol{\langle \Delta \sigma (z)\rangle }$| | |$\boldsymbol{\sigma (\Delta \sigma (z))}$| | |||||||||
| Standard | −0.0048 | −0.0045 | −0.0057 | −0.0054 | −0.0044 | 0.0036 | 0.0026 | 0.0029 | 0.0024 | 0.0037 |
| w/ weak lensing selectiona | −0.0009 | −0.0043 | −0.0044 | −0.0042 | −0.0039 | 0.0043 | 0.0035 | 0.0039 | 0.0027 | 0.0035 |
| w/ Metacalibration fluxesb | −0.0047 | −0.0040 | −0.0053 | −0.0048 | −0.0036 | 0.0039 | 0.0031 | 0.0037 | 0.0030 | 0.0039 |
| w/ only rizc | −0.0043 | −0.0029 | −0.0054 | −0.0051 | −0.0034 | 0.0036 | 0.0043 | 0.0034 | 0.0029 | 0.0035 |
| w/ decreased softening parameterd | −0.0034 | −0.0041 | −0.0051 | −0.0048 | −0.0039 | 0.0036 | 0.0033 | 0.0030 | 0.0026 | 0.0035 |
| Variation | Bin 1 | Bin 2 | Bin 3 | Bin 4 | Bin 5 | Bin 1 | Bin 2 | Bin 3 | Bin 4 | Bin 5 |
|---|---|---|---|---|---|---|---|---|---|---|
| |$\boldsymbol{\langle \Delta \langle z \rangle \rangle }$| | |$\boldsymbol{\sigma (\Delta \langle z \rangle)}$| | |||||||||
| Standard | −0.0073 | −0.0040 | 0.0006 | 0.0016 | 0.0056 | 0.0077 | 0.0042 | 0.0028 | 0.0033 | 0.0037 |
| w/ weak lensing selectiona | −0.0057 | −0.0040 | 0.0003 | 0.0027 | 0.0057 | 0.0083 | 0.0046 | 0.0042 | 0.0030 | 0.0042 |
| w/ metacalibration fluxesb | −0.0089 | −0.0044 | 0.0001 | 0.0022 | 0.0069 | 0.0077 | 0.0049 | 0.0039 | 0.0033 | 0.0037 |
| w/ only rizc | −0.0070 | −0.0050 | 0.0019 | 0.0006 | 0.0061 | 0.0071 | 0.0051 | 0.0036 | 0.0036 | 0.0038 |
| w/ decreased softening parameterd | −0.0074 | −0.0053 | −0.0012 | −0.0005 | 0.0044 | 0.0072 | 0.0040 | 0.0034 | 0.0028 | 0.0033 |
| |$\boldsymbol{\langle \Delta \sigma (z)\rangle }$| | |$\boldsymbol{\sigma (\Delta \sigma (z))}$| | |||||||||
| Standard | −0.0048 | −0.0045 | −0.0057 | −0.0054 | −0.0044 | 0.0036 | 0.0026 | 0.0029 | 0.0024 | 0.0037 |
| w/ weak lensing selectiona | −0.0009 | −0.0043 | −0.0044 | −0.0042 | −0.0039 | 0.0043 | 0.0035 | 0.0039 | 0.0027 | 0.0035 |
| w/ Metacalibration fluxesb | −0.0047 | −0.0040 | −0.0053 | −0.0048 | −0.0036 | 0.0039 | 0.0031 | 0.0037 | 0.0030 | 0.0039 |
| w/ only rizc | −0.0043 | −0.0029 | −0.0054 | −0.0051 | −0.0034 | 0.0036 | 0.0043 | 0.0034 | 0.0029 | 0.0035 |
| w/ decreased softening parameterd | −0.0034 | −0.0041 | −0.0051 | −0.0048 | −0.0039 | 0.0036 | 0.0033 | 0.0030 | 0.0026 | 0.0035 |
Comparison of the standard pheno-z scheme to various variations of the scheme. The standard scheme uses DES ugriz and VISTA YJHKs bands for the Deep SOM and DES griz for the Wide SOM. It uses a redshift sample made of 135 000 galaxies sampled from a 1.38 deg2 field, a 7.99 deg2 deep sample, and a hard cut mobs, i < 23.5 for the wide selection. In this standard scheme, 10 realizations of each deep field galaxy at different random positions constitute the overlap sample. The mean and standard deviation of the metrics given in equation (20) over 100 iterations are presented.
| Variation | Bin 1 | Bin 2 | Bin 3 | Bin 4 | Bin 5 | Bin 1 | Bin 2 | Bin 3 | Bin 4 | Bin 5 |
|---|---|---|---|---|---|---|---|---|---|---|
| |$\boldsymbol{\langle \Delta \langle z \rangle \rangle }$| | |$\boldsymbol{\sigma (\Delta \langle z \rangle)}$| | |||||||||
| Standard | −0.0073 | −0.0040 | 0.0006 | 0.0016 | 0.0056 | 0.0077 | 0.0042 | 0.0028 | 0.0033 | 0.0037 |
| w/ weak lensing selectiona | −0.0057 | −0.0040 | 0.0003 | 0.0027 | 0.0057 | 0.0083 | 0.0046 | 0.0042 | 0.0030 | 0.0042 |
| w/ metacalibration fluxesb | −0.0089 | −0.0044 | 0.0001 | 0.0022 | 0.0069 | 0.0077 | 0.0049 | 0.0039 | 0.0033 | 0.0037 |
| w/ only rizc | −0.0070 | −0.0050 | 0.0019 | 0.0006 | 0.0061 | 0.0071 | 0.0051 | 0.0036 | 0.0036 | 0.0038 |
| w/ decreased softening parameterd | −0.0074 | −0.0053 | −0.0012 | −0.0005 | 0.0044 | 0.0072 | 0.0040 | 0.0034 | 0.0028 | 0.0033 |
| |$\boldsymbol{\langle \Delta \sigma (z)\rangle }$| | |$\boldsymbol{\sigma (\Delta \sigma (z))}$| | |||||||||
| Standard | −0.0048 | −0.0045 | −0.0057 | −0.0054 | −0.0044 | 0.0036 | 0.0026 | 0.0029 | 0.0024 | 0.0037 |
| w/ weak lensing selectiona | −0.0009 | −0.0043 | −0.0044 | −0.0042 | −0.0039 | 0.0043 | 0.0035 | 0.0039 | 0.0027 | 0.0035 |
| w/ Metacalibration fluxesb | −0.0047 | −0.0040 | −0.0053 | −0.0048 | −0.0036 | 0.0039 | 0.0031 | 0.0037 | 0.0030 | 0.0039 |
| w/ only rizc | −0.0043 | −0.0029 | −0.0054 | −0.0051 | −0.0034 | 0.0036 | 0.0043 | 0.0034 | 0.0029 | 0.0035 |
| w/ decreased softening parameterd | −0.0034 | −0.0041 | −0.0051 | −0.0048 | −0.0039 | 0.0036 | 0.0033 | 0.0030 | 0.0026 | 0.0035 |
| Variation | Bin 1 | Bin 2 | Bin 3 | Bin 4 | Bin 5 | Bin 1 | Bin 2 | Bin 3 | Bin 4 | Bin 5 |
|---|---|---|---|---|---|---|---|---|---|---|
| |$\boldsymbol{\langle \Delta \langle z \rangle \rangle }$| | |$\boldsymbol{\sigma (\Delta \langle z \rangle)}$| | |||||||||
| Standard | −0.0073 | −0.0040 | 0.0006 | 0.0016 | 0.0056 | 0.0077 | 0.0042 | 0.0028 | 0.0033 | 0.0037 |
| w/ weak lensing selectiona | −0.0057 | −0.0040 | 0.0003 | 0.0027 | 0.0057 | 0.0083 | 0.0046 | 0.0042 | 0.0030 | 0.0042 |
| w/ metacalibration fluxesb | −0.0089 | −0.0044 | 0.0001 | 0.0022 | 0.0069 | 0.0077 | 0.0049 | 0.0039 | 0.0033 | 0.0037 |
| w/ only rizc | −0.0070 | −0.0050 | 0.0019 | 0.0006 | 0.0061 | 0.0071 | 0.0051 | 0.0036 | 0.0036 | 0.0038 |
| w/ decreased softening parameterd | −0.0074 | −0.0053 | −0.0012 | −0.0005 | 0.0044 | 0.0072 | 0.0040 | 0.0034 | 0.0028 | 0.0033 |
| |$\boldsymbol{\langle \Delta \sigma (z)\rangle }$| | |$\boldsymbol{\sigma (\Delta \sigma (z))}$| | |||||||||
| Standard | −0.0048 | −0.0045 | −0.0057 | −0.0054 | −0.0044 | 0.0036 | 0.0026 | 0.0029 | 0.0024 | 0.0037 |
| w/ weak lensing selectiona | −0.0009 | −0.0043 | −0.0044 | −0.0042 | −0.0039 | 0.0043 | 0.0035 | 0.0039 | 0.0027 | 0.0035 |
| w/ Metacalibration fluxesb | −0.0047 | −0.0040 | −0.0053 | −0.0048 | −0.0036 | 0.0039 | 0.0031 | 0.0037 | 0.0030 | 0.0039 |
| w/ only rizc | −0.0043 | −0.0029 | −0.0054 | −0.0051 | −0.0034 | 0.0036 | 0.0043 | 0.0034 | 0.0029 | 0.0035 |
| w/ decreased softening parameterd | −0.0034 | −0.0041 | −0.0051 | −0.0048 | −0.0039 | 0.0036 | 0.0033 | 0.0030 | 0.0026 | 0.0035 |
8.1 Weak lensing selection |$\hat{s}$|
The values for the mean and standard deviation of the bias using the weak lensing selection described in equation (21) are presented in Table 5 (see ‘w/ weak lensing selection’ entry). Using a more refined weak lensing selection than the hard cut at |$m_{\mathrm{obs},\, i}\lt 23.5$| used throughout this work does not introduce any bias but slightly increases the variance.
8.2 metacalibration fluxes
For our cosmology analysis, we must understand if, when sheared, a galaxy’s tomographic bin changes. The shape algorithm – metacalibration – allows us to artificially shear the galaxies and measure their resulting fluxes. The metacalibration flux measurement is noisier than the usual multiobject fitting (MOF; Drlica-Wagner et al. 2018, their section 6.3) flux measurement used by DES but the tomographic binning must be performed on metacalibration fluxes for the reason mentioned above (see also Zuntz et al. 2018, their Section 7.4). The estimation of the redshift distribution could then be performed using MOF photometry. To achieve this, we would need to introduce a third SOM and compute a transfer function between MOF fluxes and metacalibration fluxes. We suspect that introducing a third SOM would not improve our calibration. To avoid this complication we can perform the estimation of redshift distributions using metacalibration fluxes.
We run our pheno-z scheme replacing the wide ‘MOF’ fluxes by the mock metacalibration fluxes. As can be seen in Table 5 (entry ‘w/ metacalibration fluxes’), this results in a slight increase of the bias and variance in calibration.
8.3 Dropping the g band
Detailed tests on DES Y1 and Y3 data (Mike Jarvis, private communication) and theoretical considerations (Plazas & Bernstein 2012) show that point-spread function (PSF) modelling in DES is most difficult in the g band. The expected and observed bias in PSF modelling in g band significantly biases shape measurement. At a secondary level, it also biases g band photometry. Thus, it may be preferable to run metacalibration uniquely on the riz bands. In this case, the tomographic binning must be performed only on those bands. To simplify the comparisons and separate the different effects, we use only the riz bands, but still use ‘MOF’ fluxes. We perform our pheno-z scheme, training the Wide SOM on riz bands. The result of dropping the g band is shown in Table 5 (entry ‘w/ only riz’). The observed degradation is similarly slight to the one produced by the use of metacalibration fluxes.
The g band carries some useful information, especially at low redshift. Indeed, dropping this band results in larger bins. This effect is the strongest for the lowest redshift bin as can be seen in Fig. 6, where the true redshift distributions obtained using griz or riz are compared.
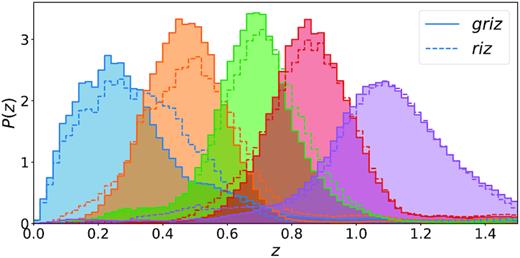
Comparison of redshift distributions of bins defined with and without g band colour in addition to riz. Information contained in g is particularly useful at low redshift. We show the true redshift distributions. The calibration of mean redshift does not substantially suffer from the loss of g band data in the wide field.
9 PHENO-Z UNCERTAINTY FOR DES Y3
We integrate the different variations discussed in Section 8 to be as close as possible to the actual redshift distribution estimation of DES Y3 weak lensing sources.
We make use of three deep fields of 3.32, 3.29, and 1.38 deg2 (see Table 1), respectively, to train a 128 by 128 Deep SOM. The input vectors are eight lupticolours relative to the i band (using DES ugriz and VISTA YJHKs). The redshift sample is made of 135 000 galaxies sampled from a 1.38 deg2 field mimicking COSMOS. Each deep field galaxy is painted 10 times over the full DES footprint to yield the overlap sample used to compute the transfer function. The wide sample is made of randomly selected galaxies over the full DES footprint. The wide and overlap sample selection is performed using the refined weak lensing selection (see Section 8.1), and the samples use mock metacalibration fluxes (see Section 8.2). The 32 by 32 Wide SOM is trained on the wide sample, and does not use the g band (see Section 8.3). Its input vector is |$\boldsymbol {x} = (\mu _i, \mu _r-\mu _i, \mu _z-\mu _i)$|, where μx is the luptitude in x band (see equation 19). A total of 300 iterations of this pheno-z fiducial scheme are performed with different deep and redshift fields at each iteration. The resulting redshift distributions of the wide sample are presented in Fig. 7 and the associated metrics in Table 6 (entry ‘DES Y3’). The expectation value of the realizations estimates closely the shape of the true redshift distribution. At each redshift, 68 per cent of the realizations are comprised in the light shaded area. This broad region is the result of sample variance.
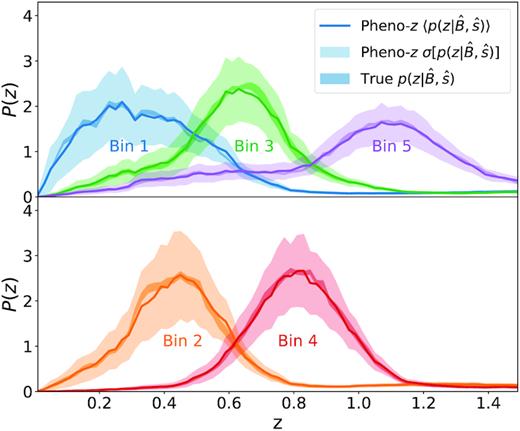
Effect of sample variance on the DES Y3 source redshift distributions. A total of 300 realizations of the distributions are computed using the pheno-z scheme. The light shaded regions contain 68 per cent of these realizations at each redshift. Their means (lines) estimate closely the true redshift distributions (dark shaded regions; mildly different in each realization).
All effects affecting the calibration of Y3 source redshift distributions are included yielding the expected uncertainty on redshift distributions. The DES Y3 uncertainties are computed on 300 iterations and include the predicted redshift and deep samples size, metacalibration fluxes, only riz bands for the galaxies in the wide sample and the weak lensing selection. Increasing the deep fields available to a total of 29.88 deg2 reduces the standard deviation on Δ〈z〉 by 34–41 per cent and on Δσ(z) by 35–43 per cent. Increasing the redshift field area by a factor of four reduces the bias, 〈Δ〈z〉〉, by 34–41 per cent in the first two bins and has a marginal impact on the other bins. The standard deviation of this metric decreases by 17–34 per cent. From these metrics, total uncertainty is estimated according to equation (23) and shown in Fig. 8.
| Pheno-z scheme | Bin 1 | Bin 2 | Bin 3 | Bin 4 | Bin 5 | Bin 1 | Bin 2 | Bin 3 | Bin 4 | Bin 5 |
|---|---|---|---|---|---|---|---|---|---|---|
| |$\boldsymbol{\langle \Delta \langle z \rangle \rangle }$| | |$\boldsymbol{\sigma (\Delta \langle z \rangle)}$| | |||||||||
| DES Y3 | −0.0061 | −0.0056 | 0.0008 | 0.0019 | 0.0080 | 0.0075 | 0.0061 | 0.0047 | 0.0037 | 0.0054 |
| Bigger deep sample | −0.0063 | −0.0059 | 0.0010 | 0.0018 | 0.0077 | 0.0044 | 0.0039 | 0.0031 | 0.0022 | 0.0033 |
| Bigger redshift sample | −0.0040 | −0.0033 | 0.0017 | 0.0017 | 0.0077 | 0.0050 | 0.0044 | 0.0039 | 0.0031 | 0.0044 |
| |$\boldsymbol{\langle \Delta \sigma (z)\rangle }$| | |$\boldsymbol{\sigma (\Delta \sigma (z))}$| | |||||||||
| DES Y3 | −0.0009 | −0.0016 | −0.0034 | −0.0049 | −0.0041 | 0.0042 | 0.0045 | 0.0042 | 0.0029 | 0.0036 |
| Bigger deep sample | −0.0013 | −0.0020 | −0.0037 | −0.0054 | −0.0042 | 0.0027 | 0.0027 | 0.0024 | 0.0018 | 0.0023 |
| Bigger redshift sample | −0.0007 | −0.0009 | −0.0025 | −0.0043 | −0.0036 | 0.0033 | 0.0034 | 0.0028 | 0.0021 | 0.0028 |
| Pheno-z scheme | Bin 1 | Bin 2 | Bin 3 | Bin 4 | Bin 5 | Bin 1 | Bin 2 | Bin 3 | Bin 4 | Bin 5 |
|---|---|---|---|---|---|---|---|---|---|---|
| |$\boldsymbol{\langle \Delta \langle z \rangle \rangle }$| | |$\boldsymbol{\sigma (\Delta \langle z \rangle)}$| | |||||||||
| DES Y3 | −0.0061 | −0.0056 | 0.0008 | 0.0019 | 0.0080 | 0.0075 | 0.0061 | 0.0047 | 0.0037 | 0.0054 |
| Bigger deep sample | −0.0063 | −0.0059 | 0.0010 | 0.0018 | 0.0077 | 0.0044 | 0.0039 | 0.0031 | 0.0022 | 0.0033 |
| Bigger redshift sample | −0.0040 | −0.0033 | 0.0017 | 0.0017 | 0.0077 | 0.0050 | 0.0044 | 0.0039 | 0.0031 | 0.0044 |
| |$\boldsymbol{\langle \Delta \sigma (z)\rangle }$| | |$\boldsymbol{\sigma (\Delta \sigma (z))}$| | |||||||||
| DES Y3 | −0.0009 | −0.0016 | −0.0034 | −0.0049 | −0.0041 | 0.0042 | 0.0045 | 0.0042 | 0.0029 | 0.0036 |
| Bigger deep sample | −0.0013 | −0.0020 | −0.0037 | −0.0054 | −0.0042 | 0.0027 | 0.0027 | 0.0024 | 0.0018 | 0.0023 |
| Bigger redshift sample | −0.0007 | −0.0009 | −0.0025 | −0.0043 | −0.0036 | 0.0033 | 0.0034 | 0.0028 | 0.0021 | 0.0028 |
All effects affecting the calibration of Y3 source redshift distributions are included yielding the expected uncertainty on redshift distributions. The DES Y3 uncertainties are computed on 300 iterations and include the predicted redshift and deep samples size, metacalibration fluxes, only riz bands for the galaxies in the wide sample and the weak lensing selection. Increasing the deep fields available to a total of 29.88 deg2 reduces the standard deviation on Δ〈z〉 by 34–41 per cent and on Δσ(z) by 35–43 per cent. Increasing the redshift field area by a factor of four reduces the bias, 〈Δ〈z〉〉, by 34–41 per cent in the first two bins and has a marginal impact on the other bins. The standard deviation of this metric decreases by 17–34 per cent. From these metrics, total uncertainty is estimated according to equation (23) and shown in Fig. 8.
| Pheno-z scheme | Bin 1 | Bin 2 | Bin 3 | Bin 4 | Bin 5 | Bin 1 | Bin 2 | Bin 3 | Bin 4 | Bin 5 |
|---|---|---|---|---|---|---|---|---|---|---|
| |$\boldsymbol{\langle \Delta \langle z \rangle \rangle }$| | |$\boldsymbol{\sigma (\Delta \langle z \rangle)}$| | |||||||||
| DES Y3 | −0.0061 | −0.0056 | 0.0008 | 0.0019 | 0.0080 | 0.0075 | 0.0061 | 0.0047 | 0.0037 | 0.0054 |
| Bigger deep sample | −0.0063 | −0.0059 | 0.0010 | 0.0018 | 0.0077 | 0.0044 | 0.0039 | 0.0031 | 0.0022 | 0.0033 |
| Bigger redshift sample | −0.0040 | −0.0033 | 0.0017 | 0.0017 | 0.0077 | 0.0050 | 0.0044 | 0.0039 | 0.0031 | 0.0044 |
| |$\boldsymbol{\langle \Delta \sigma (z)\rangle }$| | |$\boldsymbol{\sigma (\Delta \sigma (z))}$| | |||||||||
| DES Y3 | −0.0009 | −0.0016 | −0.0034 | −0.0049 | −0.0041 | 0.0042 | 0.0045 | 0.0042 | 0.0029 | 0.0036 |
| Bigger deep sample | −0.0013 | −0.0020 | −0.0037 | −0.0054 | −0.0042 | 0.0027 | 0.0027 | 0.0024 | 0.0018 | 0.0023 |
| Bigger redshift sample | −0.0007 | −0.0009 | −0.0025 | −0.0043 | −0.0036 | 0.0033 | 0.0034 | 0.0028 | 0.0021 | 0.0028 |
| Pheno-z scheme | Bin 1 | Bin 2 | Bin 3 | Bin 4 | Bin 5 | Bin 1 | Bin 2 | Bin 3 | Bin 4 | Bin 5 |
|---|---|---|---|---|---|---|---|---|---|---|
| |$\boldsymbol{\langle \Delta \langle z \rangle \rangle }$| | |$\boldsymbol{\sigma (\Delta \langle z \rangle)}$| | |||||||||
| DES Y3 | −0.0061 | −0.0056 | 0.0008 | 0.0019 | 0.0080 | 0.0075 | 0.0061 | 0.0047 | 0.0037 | 0.0054 |
| Bigger deep sample | −0.0063 | −0.0059 | 0.0010 | 0.0018 | 0.0077 | 0.0044 | 0.0039 | 0.0031 | 0.0022 | 0.0033 |
| Bigger redshift sample | −0.0040 | −0.0033 | 0.0017 | 0.0017 | 0.0077 | 0.0050 | 0.0044 | 0.0039 | 0.0031 | 0.0044 |
| |$\boldsymbol{\langle \Delta \sigma (z)\rangle }$| | |$\boldsymbol{\sigma (\Delta \sigma (z))}$| | |||||||||
| DES Y3 | −0.0009 | −0.0016 | −0.0034 | −0.0049 | −0.0041 | 0.0042 | 0.0045 | 0.0042 | 0.0029 | 0.0036 |
| Bigger deep sample | −0.0013 | −0.0020 | −0.0037 | −0.0054 | −0.0042 | 0.0027 | 0.0027 | 0.0024 | 0.0018 | 0.0023 |
| Bigger redshift sample | −0.0007 | −0.0009 | −0.0025 | −0.0043 | −0.0036 | 0.0033 | 0.0034 | 0.0028 | 0.0021 | 0.0028 |
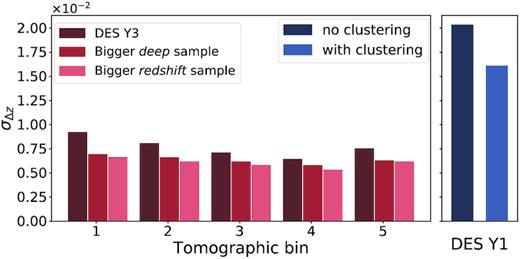
Predicted uncertainty in the mean redshift for DES Y3 (equation 23) compared to the uncertainty of the DES Y1 analysis with and without clustering information (Hoyle et al. 2018). The potential impact on this uncertainty of a bigger deep or redshift sample is also presented (dark red versus brighter red bars). A caveat to the comparison to DES Y1 is that, unlike the Y1 uncertainty shown here, the pheno-z calibration uncertainty is correlated between bins, however in a way that can be accounted for in the cosmological likelihood.
The Δ〈 z〉 in different bins are correlated which must be accounted for in the inference of cosmological parameters. In the Y1 analysis (Hoyle et al. 2018), the uncertainty on the mean redshift was derived independently for each redshift bin. The off-diagonal elements of the covariance matrix of Δ〈 z〉 could not be estimated accurately. Hoyle et al. ( 2018) showed that increasing the diagonal elements of the covariance matrix by a factor (1.6)2 and zeroing the off-diagonal elements ensured that the uncertainties of any inferred parameters were conservatively estimated for reasonable values of the off-diagonal elements. The DES Y1 values presented in Fig. 8 have also been increased by this factor 1.6. We do not include this factor in our DES Y3 estimate, as there we plan to fully marginalize over the correlated redshift distribution uncertainty. Given multiple realizations of the distributions, whose variability due to sample variance is estimated here, we can marginalize over redshift uncertainty fully by directly sampling from these realizations in the cosmological likelihood (Cordero et al. in preparation). This fully accounts for the correlation between the redshift bins and we expect it to yield reduced – yet still conservative – errors on derived quantities, which adds to the improvement in calibration possible with our scheme. The covariance matrix of Δ〈 z〉 is presented in Fig. 9. As expected, neighbouring bins are more correlated and the correlation is higher at low redshift.
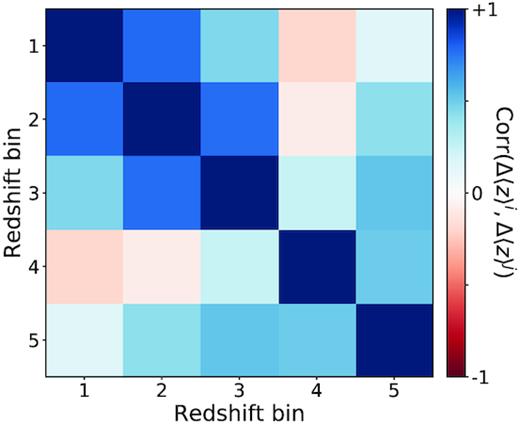
Correlation matrix of Δ〈z〉 between redshift bins for the DES Y3 configuration.
10 POSSIBLE IMPROVEMENTS
Our pheno-z scheme applied to the simulated buzzard catalogue allows us to investigate how the calibration could be improved with more data. As we have previously seen, the bias is limited by the size of our redshift sample whereas the standard deviation of the calibration error is limited by the size of the deep fields. We investigate how both those effects could be mitigated.
The major contributor to the cosmic variance in our pheno-z scheme are the deep fields. Increasing their area by taking VISTA YJHKs images of the DES supernova fields would allow us to reduce the sample variance. The VISTA Extragalactic Infrared Legacy Survey (VEILS)3 is currently imaging some of the lacking photometry in J and Ks bands. We estimate that 15, 8, 14, and 8 VISTA pointings in Y, J, H, and Ks bands, respectively, would be needed to acquire the remaining uncovered DES supernova fields area. Achieving similar depth to the VIDEO survey (see table 1 of Jarvis et al. 2013 for planned time per pointing) would require ∼395 h of telescope time. We test this possibility by assuming the availability of five deep fields: one 1.38 deg2, one 9 deg2, one 7.5 deg2, and two 6 deg2 fields. The mean and standard deviation of the calibration error, Δ〈 z〉, over 300 iterations are presented in Table 6 (see entry ‘Bigger deep sample’). As expected the mean of the bias is marginally reduced by the increase of the deep fields area. As shown in Fig. 10, the standard deviation decreases by 34–41 per cent. This significant reduction of the sample variance can also be seen in the standard deviation of Δσ(z) which decreases by 35–43 per cent.
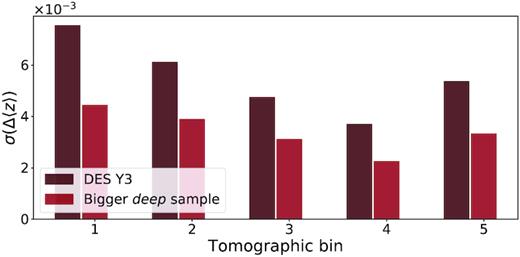
Taking VISTA YJHKs measurements in the DES supernova fields would increase the deep field area available by ∼22 deg2 which would result in a significant decrease of the sample variance.
The bias of the method is limited by the number of galaxies in the redshift sample. As we have seen in Section 6, increasing the number of cells in the Deep SOM reduces the bias, but those cells must be populated. Therefore we need a large enough sample to populate a bigger SOM. Let us assume that we can increase the number of galaxies for which we have many-band photo- z by a factor of four and use a 256 by 256 Deep SOM. We suppose that we take many-band measurements in three supplementary COSMOS-like (i.e. 1.38 deg2) fields in the DES footprint. In each of these fields we sample 135 000 galaxies. As we have seen in Section 7.1, the increase of area should not be contiguous but at different locations on the sky to maximize the sample variance reduction. Furthermore, as the many-bands must include DES ugriz and VISTA YJHKs, these fields can also be used in the transfer function computation.
The results of increasing the redshift field area by a factor of four is presented in Table 6 (entry ‘Bigger redshift sample’). The effect on Δ〈z〉 and Δσ(z) is assessed over 300 iterations. The RMS of the calibration error of mean redshift is decreased by 18 per cent. As the redshift field is also part of the deep fields and is used in the transfer function computation, the standard deviation of Δ〈z〉 also decreases by 17–34 per cent.
While there are advantages to the spatial resolution and wavelength coverage of the space-based observations of the COSMOS field, a multimedium/narrow-band survey like the Advanced Large Homogeneous Area Medium-Band Redshift Astronomical (ALHAMBRA; Moles et al. 2008) survey with the appropriate depth might also offer the necessary sample of reliable photometric redshifts. The data could be provided by the ongoing Physics of the Accelerating Universe (PAU; Martí et al. 2014; Eriksen et al. 2019) survey or by the planned Javalambre Physics of the Accelerating Universe Astrophysical Survey (J-PAS; Benitez et al. 2014). Another option would be to use a sufficiently accurate photometric code on the weight vectors of the Deep SOM. This would yield a redshift PDF for each Deep SOM cell.
The method could be extended by incorporating the information contained in the clustering of sources. A hierarchical Bayesian model can be used to combine the pheno-z method with the information contained in the galaxy clustering against a well-characterized tracer population (Sánchez & Bernstein 2018).
10.1 Reliability of redshift samples
One aspect not considered in this work is the reliability of present or obtainable redshift samples. Photometric redshifts based on multiband fluxes, such as COSMOS (Laigle et al. 2016), are known to suffer from increasing outlier rates towards faint magnitudes. These have recently been found to be a significant concern for the purposes of lensing cosmology, at least under some conditions (Hildebrandt et al. 2018). Likewise, spectroscopic samples can suffer from outliers due to erroneous line identifications or blends. In addition, such a sample may be incomplete at a given position in multiband colour space, albeit superior to a photometric sample with a limited number of bands (Gruen & Brimioulle 2017).
Unless complementary information, e.g. from clustering, is able to counter these sources of potential bias (Sánchez & Bernstein 2018), we thus emphasize that application of our method requires validating that the redshift samples used are sufficiently reliable. While this is not within the scope of this work, which is primarily meant to establish the statistical benefits of a phenotypic approach that uses deep field photometry as part of wide field redshift calibration, such tests need to be part of any practical application to data.
11 CONCLUSION
Inferring accurate redshift distributions from coarse measurements of redshifted source photometry is a difficult task. Improving the characterization of redshift distributions requires breaking type/redshift degeneracies. To this end, we propose a novel method – phenotypic redshift – which uses photometric deep fields, where measurements in more bands are available. The information from multiband deep fields acts as an intermediary between wide-field photometry and accurate redshifts to produce a better mapping in two ways. First, because the deep fields in surveys like DES are larger than existing samples of galaxies with accurately known redshifts, it provides an improved estimate of the distribution of galaxies in colour space. Secondly, the deep many-band photometry better breaks type/redshift degeneracies, thereby improving the colour/redshift relation applied in the redshift estimation. Importantly, this reduces sample variance and selection effects due to the sparse sample of galaxies with accurate redshifts and therefore leverages this scarce resource towards a more accurate characterization of the target sample’s redshift distribution.
Our implementation of this method uses two SOMs: one to group galaxies into phenotypes based on their observed fluxes in the deep fields, and one to discretize the wide-field flux measurements. By taking actual or simulated observations of the deep fields under wide-field conditions, the transfer of galaxies from cells in one of these maps to the other can be accurately quantified.
Application of the method to simulated galaxy samples allows us to probe the various sources of uncertainty in a coherent manner. We tested the method on a mock DES catalogue, emulating a calibration of the DES Year 3 weak lensing analysis using DES deep fields with near-infrared auxiliary data, and COSMOS for redshifts. With these samples, the typical uncertainty on the mean redshift in five tomographic bins is σΔz = 0.007, which is about a factor of 2 improvement compared to the Year 1 analysis. The method yields realizations of redshift distributions which can be marginalized in the cosmological parameter likelihood, accounting for the correlation between redshift distributions in different tomographic bins. This finding comes with the caveat, shared among all redshift calibration methods that are based on reference samples, that it assumes perfectly accurate redshifts to be known for the COSMOS-like sample used in the calibration.
About half the error is due to systematic biases, 〈Δz〉, in the method. This bias is limited by our ability to populate the deep field SOM on a fine enough grid. If we had more galaxies with accurate redshifts, we could increase the number of phenotypes. The potential gains are rather modest for the effort required: if DES had three additional COSMOS-like fields, the RMS value of the calibration error would be reduced by 18 per cent. This is a tall order and unlikely to be fulfilled on the time-scale of DES. A different solution to the requirement of a high-resolution deep field SOM with redshifts in each cell may be to use a template fitting technique to assign redshift distributions to any cells not covered by spectroscopy.
The error due to sample variance can, on the contrary, be reduced with a somewhat unexpected strategy. We find the sample variance of the method to be dominated by the area covered with deep multiband photometric observations, rather than the sample of accurate redshifts (Section 7.5). Designs of future imaging surveys should thus maximize the overlap of their deep fields with complementary photometric surveys. For example, ∼395 h of telescope time would be needed to obtain VISTA YJHKs measurements over the rest of the DES supernova fields. This would reduce the sample variance by 34–41 per cent, and would also be beneficial to redshift calibrations with the overlapping LSST. The Dark Energy Science Collaboration of LSST aims for σΔz = 0.002(1 + z) in their Year 1 analysis and σΔz = 0.001(1 + z) in their Year 10 analysis (The LSST Dark Energy Science Collaboration 2018), which are challenging requirements. Our tests indicate that while in principle they could be met by a scheme like the one presented here, this would require both an increase in the resolution of the deep field SOM (and thus a larger sample of galaxies with known redshift and accurate multiband photometry) and a larger volume of purely photometric optical and near-infrared deep fields.
In DES Y1, the information contained in the clustering of sources was used separately to constrain the redshift distribution. The pheno-z method provides a way of combining flux measurements with information contained in the sources’ position. A hierarchical Bayesian model allows us to combine the pheno-z method and the information contained in the galaxy clustering against a well-characterized tracer population in a robust way (Sánchez & Bernstein 2018). We intend to apply a variation of this method on DES Y3 data.
Obtaining reliable redshifts to cover the many-colour optical/NIR space remains a major observational and modelling challenge. The pheno-z framework can leverage this effort by efficiently using complementary information about the abundance and redshift of observable galaxy types to accurately estimate redshift distributions of ensembles of galaxies selected from photometric data sets.
ACKNOWLEDGEMENTS
The authors thank Jamie McCullough and numerous members of the DES Collaboration for helpful comments on the manuscript.
This work was supported in part by the U.S. Department of Energy under contract number DE-AC02-76SF00515. Support for DG was provided by NASA through Einstein Postdoctoral Fellowship grant number PF5-160138 awarded by the Chandra X-ray Center, which is operated by the Smithsonian Astrophysical Observatory for NASA under contract NAS8-03060.
Funding for the DES Projects has been provided by the U.S. Department of Energy, the U.S. National Science Foundation, the Ministry of Science and Education of Spain, the Science and Technology Facilities Council of the United Kingdom, the Higher Education Funding Council for England, the National Center for Supercomputing Applications at the University of Illinois at Urbana-Champaign, the Kavli Institute of Cosmological Physics at the University of Chicago, the Center for Cosmology and Astro-Particle Physics at the Ohio State University, the Mitchell Institute for Fundamental Physics and Astronomy at Texas A&M University, Financiadora de Estudos e Projetos, Fundação Carlos Chagas Filho de Amparo à Pesquisa do Estado do Rio de Janeiro, Conselho Nacional de Desenvolvimento Científico e Tecnológico and the Ministério da Ciência, Tecnologia e Inovação, the Deutsche Forschungsgemeinschaft and the Collaborating Institutions in the Dark Energy Survey.
The Collaborating Institutions are Argonne National Laboratory, the University of California at Santa Cruz, the University of Cambridge, Centro de Investigaciones Energéticas, Medioambientales y Tecnológicas-Madrid, the University of Chicago, University College London, the DES-Brazil Consortium, the University of Edinburgh, the Eidgenössische Technische Hochschule (ETH) Zürich, Fermi National Accelerator Laboratory, the University of Illinois at Urbana-Champaign, the Institut de Ciències de l’Espai (IEEC/CSIC), the Institut de Física d’Altes Energies, Lawrence Berkeley National Laboratory, the Ludwig-Maximilians Universität München and the associated Excellence Cluster Universe, the University of Michigan, the National Optical Astronomy Observatory, the University of Nottingham, The Ohio State University, the University of Pennsylvania, the University of Portsmouth, SLAC National Accelerator Laboratory, Stanford University, the University of Sussex, Texas A&M University, and the OzDES Membership Consortium.
Based in part on observations at Cerro Tololo Inter-American Observatory, National Optical Astronomy Observatory, which is operated by the Association of Universities for Research in Astronomy (AURA) under a cooperative agreement with the National Science Foundation.
The DES data management system is supported by the National Science Foundation under Grant Numbers AST-1138766 and AST-1536171. The DES participants from Spanish institutions are partially supported by MINECO under grants AYA2015-71825, ESP2015-66861, FPA2015-68048, SEV-2016-0588, SEV-2016-0597, and MDM-2015-0509, some of which include ERDF funds from the European Union. IFAE is partially funded by the CERCA program of the Generalitat de Catalunya. Research leading to these results has received funding from the European Research Council under the European Union’s Seventh Framework Program (FP7/2007-2013) including ERC grant agreements 240672, 291329, and 306478. We acknowledge support from the Australian Research Council Centre of Excellence for All-sky Astrophysics (CAASTRO), through project number CE110001020, and the Brazilian Instituto Nacional de Ciência e Tecnologia (INCT) e-Universe (CNPq grant 465376/2014-2).
This paper has been authored by Fermi Research Alliance, LLC under Contract No. DE-AC02-07CH11359 with the U.S. Department of Energy, Office of Science, Office of High Energy Physics. The United States Government retains and the publisher, by accepting the article for publication, acknowledges that the United States Government retains a non-exclusive, paid-up, irrevocable, world-wide license to publish or reproduce the published form of this manuscript, or allow others to do so, for United States Government purposes.
This paper has gone through internal review by the DES collaboration.
Footnotes
While there are DES Y band flux measurements available, due to their lower depth we will not use it.
REFERENCES
APPENDIX A: SOFTENING PARAMETER OF LUPTITUDES
The use of luptitudes to build the input vector of our scheme requires the choice of a softening parameter, b, which sets the scale at which luptitudes transition between logarithmic and linear behaviour (see equation 19).
Two requirements guide the choice of this parameter. The differences between luptitudes and magnitudes for high signal-to-noise data as well as the luptitude variance at low flux levels should be minimized. The former is the intrinsic goal of luptitudes while the latter is not strictly required. It is just convenient if the luptitude variance at zero flux is comparable to its variance at a small signal-to-noise ratio. These two effects oppose each other. Lupton et al. (1999) minimize a total penalty made of the addition of those two effects modelled as costs. The optimal choice of b with their penalty is b = 1.042σ where σ2 is the variance of the flux. This assumes all objects have the same error.
In reality, measurement errors change as the observation conditions change. It could be possible to set different values of b for different parts of the sky although it is unpractical. We can set b for the whole footprint using a typical seeing quality and sky brightness for a given band. Lupton et al. (1999) show that even if the softening parameter is badly chosen, it does not result in catastrophic definition of luptitudes; we recover the expected behaviour.
The limiting magnitudes used are conservative as the DES deep measurements are expected to be at a higher depth. Also, our simulations have true fluxes which have no errors. We test the sensitivity of our quoted uncertainties to the softening parameter by running our pheno-z scheme with limiting magnitudes in all deep bands increased by one magnitude (thus decreasing the softening parameter). The result is presented in Table 5 (entry ‘w/ decreased softening parameter’). There is no significant change in our metrics. Hence, we are insensitive to such a change of the softening parameter.
APPENDIX B: VALIDATION OF FEATURE AND SOM SIZE CHOICE
Calibration error, Δ〈 z〉, and overlap between bins for different choices of features. Colour denotes a difference in magnitudes whereas lupticolour denotes a difference in luptitudes. All those differences are with respect to the i band. Magnitude and luptitude denote adding the i band magnitude and luptitude, respectively. The Deep SOMs are 128 by 128 and the Wide SOMs are 32 by 32. All samples used in this test are randomly selected over the whole sky. There is no significant difference between the features used. We choose to use lupticolour for the Deep SOM and lupticolour + luptitude for the Wide SOM as it is a convenient way to deal with objects which are not measured in some bands (see Section 5.1).
| Deep SOM | Wide SOM | |$\boldsymbol{\Delta \langle z \rangle }$| in bin | Overlap | ||||
|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | |||
| colour | lupticolour | 0.0001 | −0.0009 | 0.0002 | 0.0034 | 0.0106 | 0.33 |
| lupticolour | lupticolour | −0.0011 | −0.0022 | −0.0011 | 0.0026 | 0.0080 | 0.34 |
| lupticolour | lupticolour + luptitude | −0.0029 | −0.0020 | −0.0004 | 0.0022 | 0.0072 | 0.37 |
| colour | lupticolour + luptitude | −0.0016 | −0.0014 | 0.0004 | 0.0022 | 0.0113 | 0.37 |
| colour | colour | 0.0005 | −0.0011 | 0.0001 | 0.0037 | 0.0105 | 0.34 |
| colour | colour + magnitude | 0.0014 | −0.0009 | 0.0003 | 0.0028 | 0.0103 | 0.38 |
| Deep SOM | Wide SOM | |$\boldsymbol{\Delta \langle z \rangle }$| in bin | Overlap | ||||
|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | |||
| colour | lupticolour | 0.0001 | −0.0009 | 0.0002 | 0.0034 | 0.0106 | 0.33 |
| lupticolour | lupticolour | −0.0011 | −0.0022 | −0.0011 | 0.0026 | 0.0080 | 0.34 |
| lupticolour | lupticolour + luptitude | −0.0029 | −0.0020 | −0.0004 | 0.0022 | 0.0072 | 0.37 |
| colour | lupticolour + luptitude | −0.0016 | −0.0014 | 0.0004 | 0.0022 | 0.0113 | 0.37 |
| colour | colour | 0.0005 | −0.0011 | 0.0001 | 0.0037 | 0.0105 | 0.34 |
| colour | colour + magnitude | 0.0014 | −0.0009 | 0.0003 | 0.0028 | 0.0103 | 0.38 |
Calibration error, Δ〈 z〉, and overlap between bins for different choices of features. Colour denotes a difference in magnitudes whereas lupticolour denotes a difference in luptitudes. All those differences are with respect to the i band. Magnitude and luptitude denote adding the i band magnitude and luptitude, respectively. The Deep SOMs are 128 by 128 and the Wide SOMs are 32 by 32. All samples used in this test are randomly selected over the whole sky. There is no significant difference between the features used. We choose to use lupticolour for the Deep SOM and lupticolour + luptitude for the Wide SOM as it is a convenient way to deal with objects which are not measured in some bands (see Section 5.1).
| Deep SOM | Wide SOM | |$\boldsymbol{\Delta \langle z \rangle }$| in bin | Overlap | ||||
|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | |||
| colour | lupticolour | 0.0001 | −0.0009 | 0.0002 | 0.0034 | 0.0106 | 0.33 |
| lupticolour | lupticolour | −0.0011 | −0.0022 | −0.0011 | 0.0026 | 0.0080 | 0.34 |
| lupticolour | lupticolour + luptitude | −0.0029 | −0.0020 | −0.0004 | 0.0022 | 0.0072 | 0.37 |
| colour | lupticolour + luptitude | −0.0016 | −0.0014 | 0.0004 | 0.0022 | 0.0113 | 0.37 |
| colour | colour | 0.0005 | −0.0011 | 0.0001 | 0.0037 | 0.0105 | 0.34 |
| colour | colour + magnitude | 0.0014 | −0.0009 | 0.0003 | 0.0028 | 0.0103 | 0.38 |
| Deep SOM | Wide SOM | |$\boldsymbol{\Delta \langle z \rangle }$| in bin | Overlap | ||||
|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | |||
| colour | lupticolour | 0.0001 | −0.0009 | 0.0002 | 0.0034 | 0.0106 | 0.33 |
| lupticolour | lupticolour | −0.0011 | −0.0022 | −0.0011 | 0.0026 | 0.0080 | 0.34 |
| lupticolour | lupticolour + luptitude | −0.0029 | −0.0020 | −0.0004 | 0.0022 | 0.0072 | 0.37 |
| colour | lupticolour + luptitude | −0.0016 | −0.0014 | 0.0004 | 0.0022 | 0.0113 | 0.37 |
| colour | colour | 0.0005 | −0.0011 | 0.0001 | 0.0037 | 0.0105 | 0.34 |
| colour | colour + magnitude | 0.0014 | −0.0009 | 0.0003 | 0.0028 | 0.0103 | 0.38 |
We find that the choice of features does not matter very much. The first four bins have a calibration error, for all features combination tested, of Δ〈 z〉 < 0.005 which is acceptable for our purpose. The last bin has a larger calibration error, reaching Δ〈 z〉 > 0.01, but it is the most suspect one in the simulations as it is constructed from a hard cutoff at z = 1.5. We stick to the deep lupticolour and wide lupticolour-luptitude SOMs for the reasons mentioned in Section 5.1.
To test the impact of the size of the SOMs on our scheme, we use a realistic redshift sample (105 galaxies) and different SOM sizes. The result, presented in Fig. B1, shows that increasing the size of the Deep SOM results in a larger calibration error whereas increasing the size of the Wide SOM does not result in any improvement. We therefore stick to the 128 by 128 Deep SOM and 32 by 32 Wide SOM.
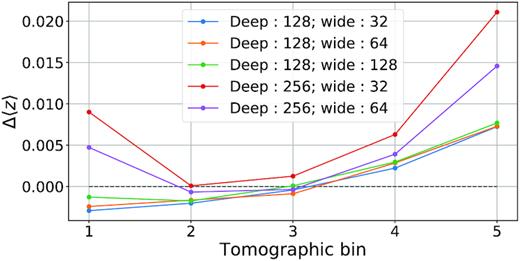
Impact of the number of deep and Wide SOM cells on the redshift distribution estimation. An unbiased method would give Δ〈z〉 = 0 for all bins (grey dashed line). The Deep SOM is trained on lupticolours and the Wide SOM on lupticolours and the luptitude in i band. All SOMs are square and the size given in the legend is the number of cells on a side (e.g. 128 means a 128 by 128 SOM).
APPENDIX C: CALCULATION OF COVARIANCE AND INVERSE COVARIANCE MATRICES
We present the analytic forms for calculating the covariance and inverse covariance matrices for two cases:
differences of magnitudes or luptitudes with respect to a reference magnitude or luptitude, and including the reference magnitude or luptitude;
differences of magnitudes or luptitudes with respect to a reference magnitude or luptitude, not including the reference magnitude or luptitude.
For example, we might have the bands g, r, and i, and we might decide to use the i band as the reference band. Let us call the errors in each band σx. We assume each band is independently measured. We define the four combinations of covariance terms between the reference band magnitude and the colours:
- The covariance between the reference band magnitude and itself,(C1)\begin{eqnarray*} \Sigma _{i, i} = \sigma ^2_i \ . \end{eqnarray*}
- The covariance between the reference band magnitude and a colour,(C2)\begin{eqnarray*} \Sigma _{i, g-i} = -\sigma ^2_i \ . \end{eqnarray*}
- The covariance between a colour and itself,(C3)\begin{eqnarray*} \Sigma _{g-i, g-i} = \sigma ^2_g + \sigma ^2_i \ . \end{eqnarray*}
- The covariance between one colour and a second,(C4)\begin{eqnarray*} \Sigma _{g-i, r-i} = \sigma ^2_i \ . \end{eqnarray*}
We are interested in the inverse covariance matrix for equation (14). We could numerically invert the covariance matrices constructed from the above rules, but we find a significant speedup (about 60 times faster) from using analytic formulas for the inverse covariance. When our input vector is the reference magnitude and differences with respect to the reference band, for example |$\boldsymbol {x} = (m_i, m_g-m_i, m_r-m_i)$|, then the inverse covariance terms are as follows:
- The inverse covariance between the reference band magnitude and itself,where the sum is over all flux passbands f.(C7)\begin{eqnarray*} \Sigma ^{-1}_{i, i} = \sum _f \frac{1}{\sigma ^2_f} \ , \end{eqnarray*}
- The inverse covariance between the reference band magnitude and a colour,(C8)\begin{eqnarray*} \Sigma ^{-1}_{i, g-i} = \frac{1}{\sigma ^2_g} \ . \end{eqnarray*}
- The inverse covariance between a colour and itself,(C9)\begin{eqnarray*} \Sigma ^{-1}_{g-i, g-i} = \frac{1}{\sigma ^2_g} \ . \end{eqnarray*}
- The inverse covariance between one colour and a second,(C10)\begin{eqnarray*} \Sigma ^{-1}_{g-i, r-i} = 0 \ . \end{eqnarray*}
When our input vector is only the difference with respect to the reference band, for example |$\boldsymbol {x} = (m_g-m_i, m_r-m_i)$|, then the inverse covariance terms are as follows:
- The inverse covariance between a colour and itself,where the sum is over all flux passbands f.(C11)\begin{eqnarray*} \Sigma ^{-1}_{g-i, g-i} = \frac{1}{\sigma ^2_g} - \frac{1}{\sigma ^4_g} \frac{1}{\sum _f \frac{1}{\sigma ^2_f}} \ , \end{eqnarray*}
- The inverse covariance between one colour and a second,where the sum is over all flux passbands f.(C12)\begin{eqnarray*} \Sigma ^{-1}_{g-i, r-i} = -\frac{1}{\sigma ^2_g \sigma ^2_r} \frac{1}{\sum _f \frac{1}{\sigma ^2_f}} \ , \end{eqnarray*}
Author notes
Einstein Fellow

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}